




wheel
Members
-
Joined
-
Last visited
Everything posted by wheel
-
Sorry for the belated response - crazy day!

-
Bridge mode (coming from a FIOS coax ONT).
-
Nope; neither. ISP modem/wifi combo (wifi disabled) into a Netgear R6 series wifi router, both with vanilla default settings. Direct ethernet cable for this particular box. Haven't modified anything in that chain at any point in the better part of the past 5 years.
-
Yeah, I tried everything listed above, and no luck. System still can't reach githubusercontent by ping (raw still OK), and the manual plugin installation attempt gives me an SSL verification failure error. Any ideas for next steps to find the cause of the github / amazonaws blockage on my end? Or if it's ISP-based, does this mean I basically need to just accept unraid as a deprecated OS for my living situation, at least until I move to a new home with a new potential ISP? Seriously, any ideas at all will be incredibly appreciated! Thanks to everyone for the help so far.
-
Done. Thank you for checking! CA-Logging-20220723-0847.zip
-
Similar results from raw, but non-raw comes up blank:
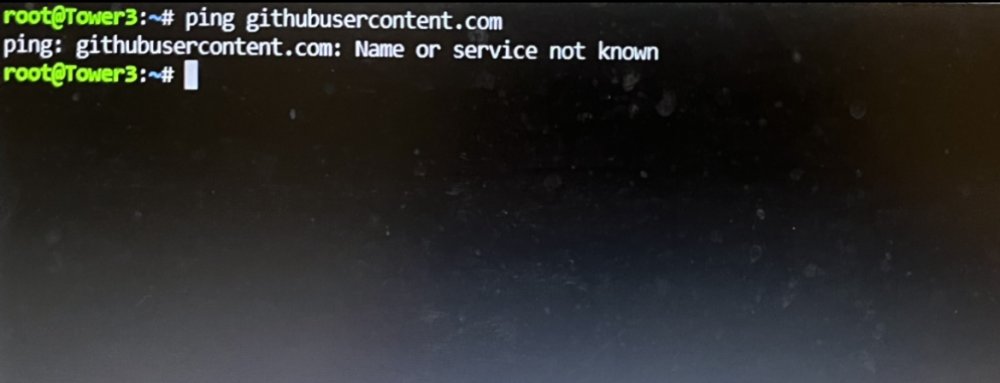
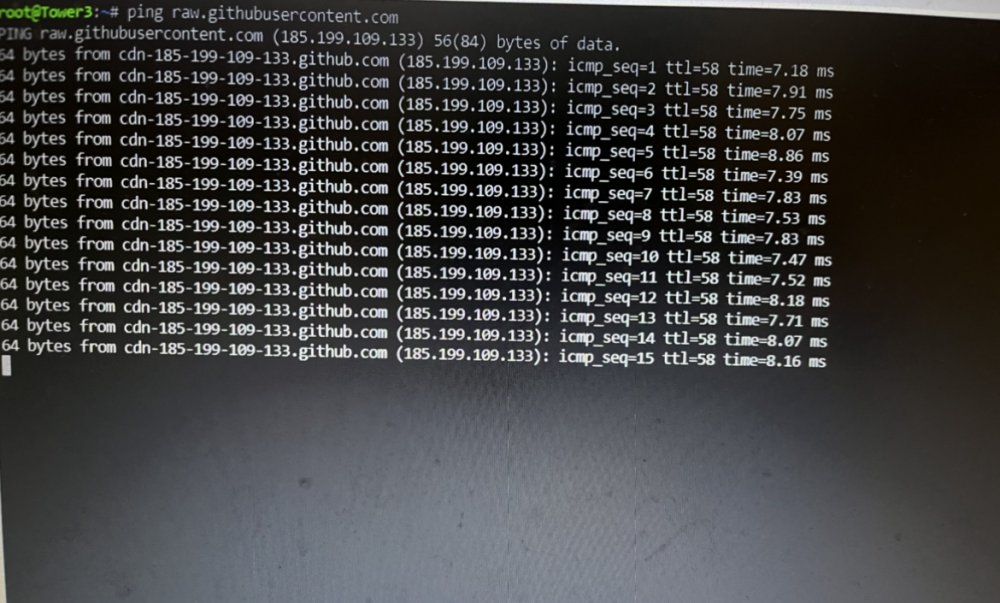
-
Here's my results from a server ping to Github:
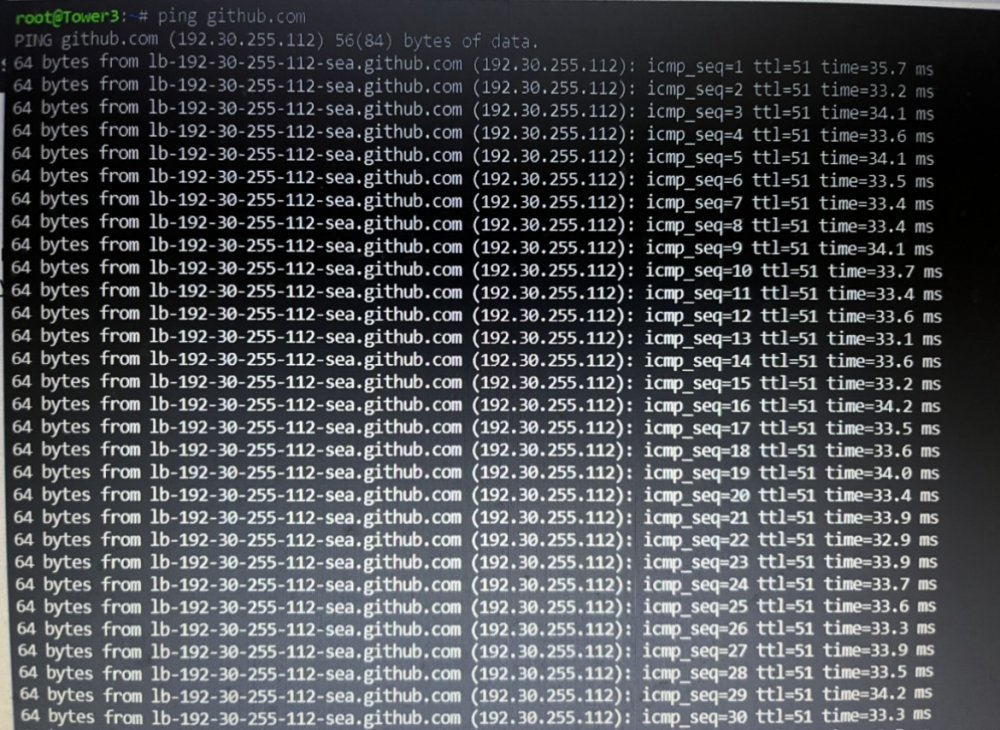
-
Yep; screen gives the wiggly-line "loading" animation for a second, then always goes to "Download of appfeed failed. Community Applications requires your server to have internet access. The most common cause of this failure is a failure to resolve DNS addresses. You can try..." ...and then I've gone through all the things to try, using unraid Network Settings, router settings, changing one thing at a time in each as a troubleshooting method... nada. Checked forum posts for others getting this error message, and tried some of their workarounds. Still the same error message. All three servers listed in the forum as handling the appfeed are currently up and reporting no connection errors. I'm totally at a loss and out of ideas (other than giving up and messing with Crystal Disk or whatever, which wouldn't be the end of the world... but damn, it'd be nice to have a preclear option back in my comfort zone, if possible).
-
I'm definitely not explaining my situation properly. I use my server daily, access it daily, and am constantly on top of drive-replacement-related issues. That's kind of all I use unraid for: a big, dumb-terminal NAS box for file storage and access. WORM stuff. If the default was to keep those boxes completely "off the internet", I would probably never take extra steps to get them communicating with the outside world, if only for security purposes - I just get no personal benefit from (what absolutely seem like amazing and useful) extra features that unraid now offers which it didn't a decade or so ago when I started using it. By no means am I trying to cast shade at any of these features, if anyone's taking my posts the wrong way; I'm just trying to get my stress test functionality back for new disks while changing as little of my comfortable-for-10ish-years setup as possible. Seriously thankful for all the help so far!
-
Sorry, poor phrasing on my part - I haven't clicked on the Apps tab since I first set it up (I think back when I upgraded to the 6.9 series, a couple years back). I definitely haven't tried installing anything (apps or otherwise) since the version bump, until now (trying to install this new "preclear for unassigned devices" service). There's a chance I've been having issues connecting to the Community Apps system for the entire couple of years I've had it set up - I just wouldn't know because I haven't been clicking on the tab to try using it for anything (no need on my part). I also don't see myself using it again for anything once I get preclear working again, based on my past decade or so of unraid use. Again, apologies for not phrasing that more clearly! Rough morning.
-
Nope; they'd get lost in my flood of emails. I run dual parity, check parity monthly, keep an eye on my dashboard(s) multiple times a day, and could easily replace almost everything I have in the event of a total catastrophic data loss from missing notifications. I'm probably not the standard unraid user, but unraid has worked beautifully for my needs for about a decade now. "Easy Preclear" stress tests have absolutely been a part of that, for me.
-
Yeah, and vaguely remember it working for stuff when I did... but I want to say that was towards the beginning of the pandemic? I'm very much a vanilla-unraid user. I don't think I've clicked the Apps button at all since I first set it up way back when.
-
Originally posted in General Support as directed in the "120220-fix-common-problems-more-information/page/2/?tab=comments#comment-1101084" instructions, but just got directed back here: I've been a "set and forget" unraid user for years, so the "new" (I totally know it's not new, but still) method of running stuff on top of vanilla unraid through Community Applications is something I haven't messed with much at all... until this week, at which point I'm beating my head against the wall trying to get it to connect through the internet. For some reason, my preclear option disappeared during an update between February or March of this year and now. I'd previously been using the gfjardim plugin, and clicking preclear through the main unraid array menu. Now, I'm trying to "get preclear back" as an option (days are ticking away on purchase warranties), and it's looking like the only way to do that these days is through the Community Apps' Preclear for Unassigned Devices app. So far, so good. I cannot for the life of me get Community Apps to connect. All the servers (github, amazonaws) listed in the main tech support page for Community Apps show zero issues, so it's definitely a problem on my end. I've configured network settings to include a pair of OpenDNS servers as suggested in these forums. Not using a proxy or PiHole. Diagnostics are attached. Honestly, if there's just a backdoor way of me getting the ability to preclear my disks again without needing to connect to Community Apps, I'd actually just take that route, but if the only way to get preclearing again is to get Community Apps connecting, I'd greatly appreciate any help anyone can give me in making that happen before my preclear schedule starts bumping up against return deadlines! Thanks in advance, beyond words! tower3-diagnostics-20220722-0537.zip
-
Thanks, wgstarks! I'll post in that thread (was posting here versus there following the instructions in the link on the CA connection error page, actually). I'm 100% just using preclear for stress testing new drives, but timing-wise, I'm getting extremely close to just throwing these particular new drives at one of my windows machines and running badblocks or whatever the best-practice software these days is instead. Spending like a decade using preclear as my "don't need to worry as much about RMA'ing this drive in the near future versus just returning it to a retailer in the returns window" insurance policy became a mental security blanket, though, so I'd love to get the functionality back in my unraid box if at all possible. It's just nuts that I'm at an unraid version level that can't manually install the old plugin (just a hair too new), I can't connect through community applications to automatically install the new app, and I'm getting errors trying to install even the binhex-preclear docker container... seriously about to just walk away for a bit for sanity's sake. Hopefully this post (and the one I'm about to make in the CA support thread) lead to some ideas out of this maze! Thank you again for the response.
-
I've been a "set and forget" unraid user for years, so the "new" (I totally know it's not new, but still) method of running stuff on top of vanilla unraid through Community Applications is something I haven't messed with much at all... until this week, at which point I'm beating my head against the wall trying to get it to connect through the internet. For some reason, my preclear option disappeared during an update between February or March of this year and now. I'd previously been using the gfjardim plugin, and clicking preclear through the main unraid array menu. Now, I'm trying to "get preclear back" as an option (days are ticking away on purchase warranties), and it's looking like the only way to do that these days is through the Community Apps' Preclear for Unassigned Devices app. So far, so good. I cannot for the life of me get Community Apps to connect. All the servers (github, amazonaws) listed in the main tech support page for Community Apps show zero issues, so it's definitely a problem on my end. I've configured network settings to include a pair of OpenDNS servers as suggested in these forums. Not using a proxy or PiHole. Diagnostics are attached. Honestly, if there's just a backdoor way of me getting the ability to preclear my disks again without needing to connect to Community Apps, I'd actually just take that route, but if the only way to get preclearing again is to get Community Apps connecting, I'd greatly appreciate any help anyone can give me in making that happen before my preclear schedule starts bumping up against return deadlines! Thanks in advance, beyond words! tower3-diagnostics-20220722-0537.zip
-
Good to know! My SMB speeds using Windows are usually a third or less than what Krusader was giving me, so the Unassigned Devices trick might be what I’m looking for, especially if I can just mount individual disks as a share with a little work (organizing setup is disk-dependent on one of the towers I regularly move new files onto).
-
Any updates on a replacement tower-to-tower transfer alternative? Krusader finally started crapping out on me (won’t even start now with a noVNC webutil.js error I can’t find any details for online, and MC doesn’t seem to want to see my separate server address for transfers between two separate hardware systems…
-
So I've been using Krusader for ages without making any active changes, but I'm running into this error today: noVNC encountered an error: http://((SERVER)):6080/app/webutil.js readSetting@http://(SERVER):6080/app/webutil.js:150:30 initSetting@http://(SERVER):6080/app/ui.js:710:27 initSettings@http://(SERVER)):6080/app/ui.js:131:12 start@http://((SERVER)):6080/app/ui.js:57:12 prime/<@http://((SERVER)):6080/app/ui.js:45:27 I was running 6.8.3, so I upgraded to 6.9.3; same error. I ran a force update on binhex-krusader; same error. Has anyone else run into this? I was using it to transfer files less than a week ago, and absolutely haven't changed anything sense (outside of running a successful parity check yesterday). Any ideas on ways to resolve would be greatly appreciated! tower3-diagnostics-20220510-1114.zip
-
Sorry for the incredibly late response - week totally ran away from me with work. Diagnostics attached; never enabled full disk encryption. CPU's an AMD Phenom II X4 820 @ 2800 MHz. Based on a past conversation (which I'm having an incredibly hard time finding right now), I upgraded my CPU to the best-case scenario for my motherboard, and was told it was just a band-aid improvement, as the CPU is the bottleneck and in order to jump up a level in parity-check speed, I'd need to upgrade my motherboard, too. Serious apologies for not including all of this information in the original post! EDIT: I'm thinking these are the relevant syslog sections: Nov 19 20:20:12 Tower2 kernel: raid6: sse2x1 gen() 3644 MB/s Nov 19 20:20:12 Tower2 kernel: raid6: sse2x1 xor() 3646 MB/s Nov 19 20:20:12 Tower2 kernel: raid6: sse2x2 gen() 5785 MB/s Nov 19 20:20:12 Tower2 kernel: raid6: sse2x2 xor() 6341 MB/s Nov 19 20:20:12 Tower2 kernel: raid6: sse2x4 gen() 6777 MB/s Nov 19 20:20:12 Tower2 kernel: raid6: sse2x4 xor() 3230 MB/s tower2-diagnostics-20211123-0735.zip
-
Theoretically a simple question, but having found tons of options (most outdated / sold out / no longer being made) through post searching, I figured I'd ask a brand new question in hopes of a November 2021 answer in time for Black Friday: I have a "save and forget" media tower which does absolutely nothing outside of holding drives. No docker, no apps, no cache disk. But the motherboard (AM3 AMD 880G SATA 6Gb/s ATX ECS A885GM-A2) doesn't support strong enough CPUs for my dual parity checks to take less than ~3 days (18 data disks spread across WD 8TBs and 12TBs, mostly even split of EMAZ and EDFZ, and two EDAZs - they're mostly connected to a pair of Genuine LSI 6Gbps SAS HBA LSI 9211-8i P20 IT Mode Low Profile cards, which I definitely don't want to replace). I'm finally ready to upgrade that motherboard, and I'm *guessing* my decade-old 2GB of RAM that's been serving my needs well (Crucial 240-Pin DDR3 SDRAM 1333 PC310600) should probably be upgraded to ECC, but if I wanted to max out my parity check speeds as cheaply as possible without hunting old hardware trade boards or dealing with eBay trust issues, does anyone have any readily-retail-available bang-for-buck suggestions for upgrading that old motherboard (and necessarily CPU, from everything I've read)? If the old-slot RAM works, all the better, but presuming my low-demand needs don't need more than 2GB anyway, a bonus ECC upgrade to match a new motherboard hopefully won't break the bank. Thanks so much in advance for any ideas or guidance on this overwhelming shopping endeavor!
-
Following a lot of mid-pandemic work on my unRAID towers, I’ve reached a point where I’m pretty comfortable I’ve done all I can do to ensure against catastrophic failure: finally converted all my ReiserFS drives to XFS, got everything protected by dual parity, resolved a bunch of temperature issues. One thing bugs me, though: two of these 21-drive towers (and one 13-drive tower) are about a decade (and about 7 years) old, and I keep reading snippets of “well, unless your PSU fails and takes out everything at once” in unrelated threads that, combined with the “capacity reduces by 10% or so yearly up to a point” adage, has me thinking I may be dancing on thin ice with all three of these PSUs currently. What gives me pause on replacing all three (or at least the pair of ~decade old ones) immediately is the weird use case of UnRAID (or maybe just mine specifically). All three of these towers were designed for their UnRAID WORM purpose, and none of their parts had any previous life. Am I being extremely paranoid, or is replacement at this point a prudent idea? There have definitely been times (months, even years) where one tower or the other has not been powered on at all, or has seen extremely minimal use (90% idle time when powered on). Could these use situations mitigate the normal “danger zone” timeline on replacing a PSU? …or not enough to ease larger concerns on something like built-up fan dust congealing and overheating the PSU regardless of how long it’s actually been in operation (and at what level of effort)? Any guidance on how concerned I should be (and how swiftly I should replace what I have) would be greatly appreciated! PSU/System Age Specifics (all drives 3.5” between 5700-7200): The 2011 21-disk tower is running on a Corsair Enthusiast Series TX650 ATX12V/EPS12V 80 Plus Bronze, purchased in 2011 The 2012 21-disk tower is running on a Corsair Enthusiast Series TX650 ATX12V/EPS12V 80 Plus Bronze, purchased in 2012 The 2015 13-disk tower is running on a Corsair RM Series 650 Watt ATX/EPS 80PLUS Gold-Certified Power Supply - CP-9020054-NA RM650, purchased in 2015
-
Thanks a ton, itimpi - took those steps, rebooted fine, GUI loaded fine, array started fine! One thing seems weird: on the dashboard, my parity drive's now showing a reallocated sector count of 3. I'd *just* run an errorless parity check right after installing IT-flashed LSI cards (to replace Marvell ones) before attempting to upgrade from 5.0.6 to 6.8.3, and my instinct is to run another parity check right now, to make sure it remains constant at 3, but is there anything that could have happened during the upgrade (nothing touched inside the box) to lead to the reallocated sector counts I should be cautious about before running that parity check?
-
Just tried method 1 (upgrading from 5.0.6 to 6.8.3, or apparently a half-step to 6.5.3?), and unRAIDServer.plg saved fine. I ran installplg unRAIDServer.plg, and: *successfully wrote INLINE file contents *downloaded infozip-6.0-i486-1.txz *verified infozip-6.0-i486-1.txz *installed infozip-6.0-i486-1.txz But then, the plugin tries to download unRAIDServer-6.5.3-x86_64.zip from s3.amazonaws.com. First it tells me s3.amazonaws.com's certificate cannot be verified (unable to locally verify the issuer's authority), and when the HTTP request was sent, the response was 403 Forbidden. With the steps that the Method 1 upgrade plugin, should I just download the 6.8.3 zip from Limetech's site and move the bz* files into the root of my existing flash drive? If I do, can I do that through SMB file transfer and a reboot, or do I need to turn off the server, remove the flash drive, and do anything manually to it that the plugin didn't get around to doing? If my fix is a simple addition of bz* files at this point, are there any other things the upgrade plugin would have taken care of automatically after the 6.5.3 zip was downloded that I now need to take care of manually before trying to boot into 6.8.3? I'm running pure vanilla unRAID at 5.0.6 and have no expectations of adding any dockers/plugins to this box in the future, if that makes a difference. Thanks in advance for any guidance / next steps! I'll go ahead and leave the box on until I hear back here in case staying online after taking the first few steps of unRAIDServer.plg has put me in a position where a reboot would be screwy now.



