




boy914
Members
-
Joined
-
Last visited
-
Thanks @JorgeB! Between chkdsk and those instructions, I was able to get the server back up and running. I need to fix a few things, but so far it looks stable.
-
Hi all, it's been a while... While updating my sever from 10.x (can't remember which version) to 11.5. After the update the server wouldn't boot, and it appears that my flash drive is corrupted. Of course, I didn't follow the instructions and failed to create a flash backup before the upgrade, so I'm wondering if the upgrade process does anything to automatically back up the flash drive contents somewhere. It's probably a long shot, but my other choice is to restore to the last flash backup I have from 2018 and try to remember what I changed since then. If anyone has any tips for accessing a flash drive that Windows doesn't even recognize ("D:\ is not accessible. The file or directory is corrupted and unreadable."), I'm all ears. Attached is what I see on the console during server boot:
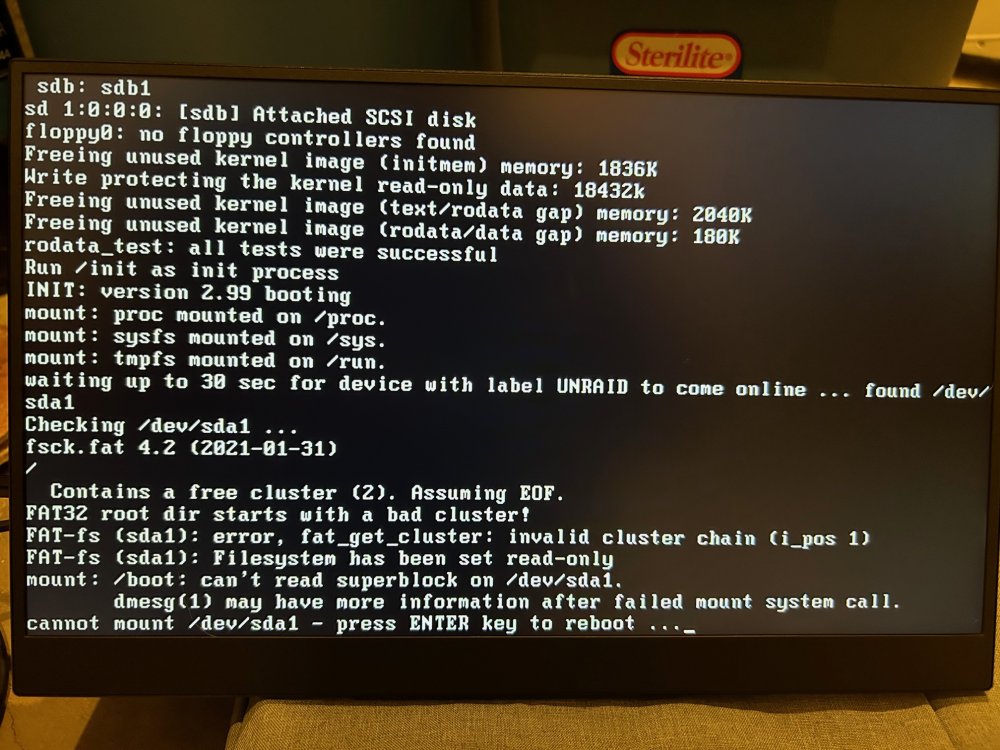
-
Just an FYI for anyone using the MySQL docker to run the Kodi database: MySQL was recently updated to version 5.7 as the "official" version. As such, my Docker updated to 5.7 a few days ago and Kodi started having issues, as described here: http://forum.kodi.tv/showthread.php?tid=247907 Rather than hack a MySQL 5.7 install to "act" like 5.6, I decided to try and get the Docker to pull down the 5.6 latest version instead of 5.7. Turns out it's as simple as setting the "Repository" value to: ...in the Docker's advanced settings view. BACK UP YOUR DATABASE FIRST, since you'll probably end up having to do a fresh MySQL install. Also, if you do a full dump backup and you're already on 5.7, you'll need to remove any entries that refer to the "sys" or "mysql" databases in the backup file.
-
BobPhoenix you're my hero, thanks! My VM XML was nearly identical to yours, so I was able to follow the instructions and pass through the 2nd NIC on the first try. No stub, no reboot of the host. Next up is the PVR software (NextPVR) using the network tuner (HDHomeRun Dual), and then things will really get interesting when I try to passthrough my extra SATA card PCI and TV Tuner card. I'll post the results here when I get around to making those changes.
-
Ok, I think I follow. So this explains why the "stub" isn't needed for other PCI devices (such as TV tuners, etc), that unRAID isn't interested in and therefore won't bind? Thanks!
-
Hopefully this is an easy question. I noticed in the "***GUIDE*** Passing Through Network Controllers to unRAID 6 Virtual Machines" a step to add this to the syslinux.cfg: http://lime-technology.com/forum/index.php?topic=39638.0 pci-stub.ids=8086:153b ...but nowhere in this guide is there mention of editing syslinux for passthrough. Can someone explain this difference and the purpose of adding the "pci-stub" to syslinux? I just finished my unRAID 6 upgrade over the weekend and so far couldn't be happier. I already have a Win10 VM running, and I'd like to pass through my second NIC (so the VM doesn't get traffic routed by the OpenVPN plugin) as well as a PCI TV tuner card. So, I'm currently studying both guides to document my next steps.

