




jeradc
Members
-
Joined
-
Last visited
-
Trying to install this, and it's asking for "Database URL:" in the template, but the instructions on this page say postgres is part of the container? do I need to supply my own instance, or not?
-
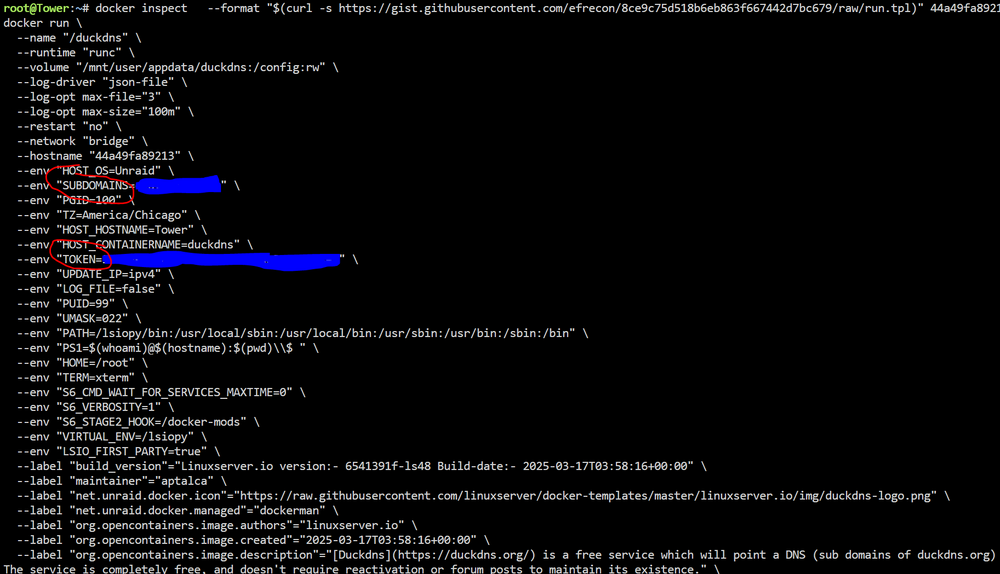
I typed a reply in my notes, but never copy/pasted here. I just found them, so for future reference: Why: Useful for docker containers like DuckDNS that have fields not list in the Unraid GUI like "Subdomain" and "Token", Plex for the "Plex Claim Token", and NordLynx "Private Key". How: Use this docker inspect library to get more details on what's running on the system: https://gist.github.com/efrecon/8ce9c75d518b6eb863f667442d7bc679 Run the following command to get a list of all docker guid's on your system (this is also available in the UI, by toggling "Basic View" on the Docker Tab) docker ps -a Then, for each container you need the details from, update the GUID appropriately and run the following full command shown below. Example: DuckDNS: docker inspect \ --format "$(curl -s https://gist.githubusercontent.com/efrecon/8ce9c75d518b6eb863f667442d7bc679/raw/run.tpl)" \ 884a92747365 Note: You will need to expose the QbitTorrent Web UI port by adding a port to the container. (reference the "--expose "xxxx/tcp" line from our docker inspect command)
-
Future me reporting in, the issue still recurs, just not as frequently as before. I'll try to get a new power supply for the system when I can. Right now this issue, seems self-correcting for the time being.
-
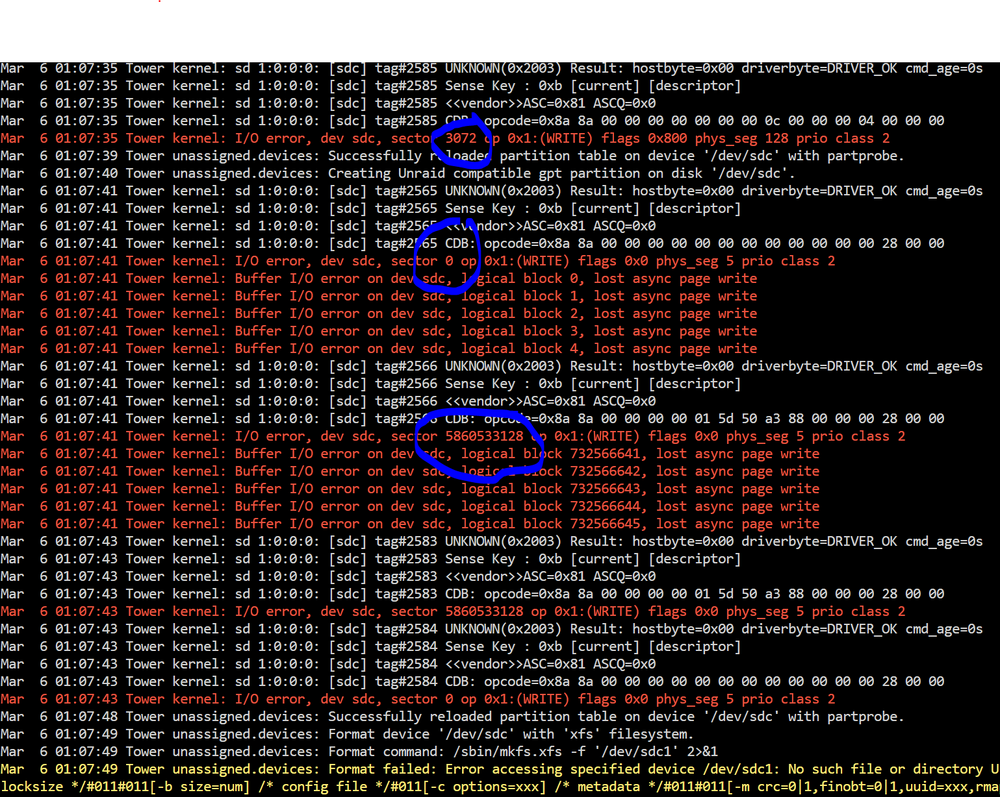
I found this reddit post: https://www.reddit.com/r/homelab/comments/jouzh7/truenas_cant_wipe_3tb_seagate_drive/ with my exact HDD Make/Model/Size: SEAGATE DKS2D-H3R0SS Using the suggested command: sg_format --format --size=512 -6 -v -e -v /dev/sdc I then tried to watch the status with the suggested command: scsi_ready /dev/sdc but that actually crashed after some time, and would not work again. I then found and used this command (sg_turs) for a status: https://manpages.ubuntu.com/manpages/xenial/man8/sg_turs.8.html which now successfully gave me a Percentage status on the drive and both commands ran for over 12 hours and then finished. The drive showed in Unraid with an available format option which I tried again. I have the same I/O errors, but now in more than just sector 0. So, I'm in the same state (unable to add to array) despite a more successful format occurring via the sg_format command. I have found other posts with the same issue, with the same drive, but no real answers. I'll keep looking. FYI tower-diagnostics-20250322-1212.zip
-
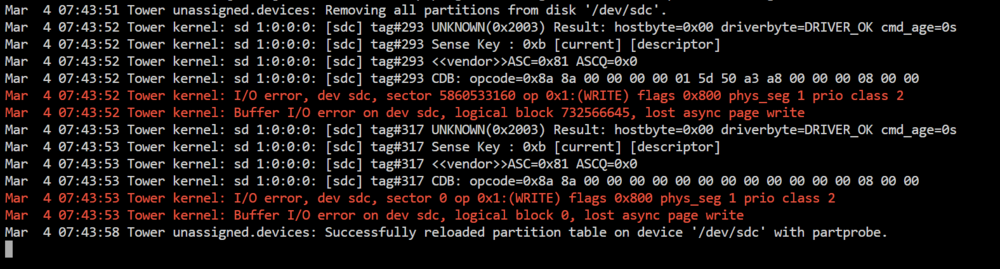
I installed Unassigned Devices Plus, and enabled Destructive Mode in the settings. I now have the option to clear the disk. I selected it, typed yes.... and the dialog box said "Success". The UI however, did not change, and this was in the log:
-
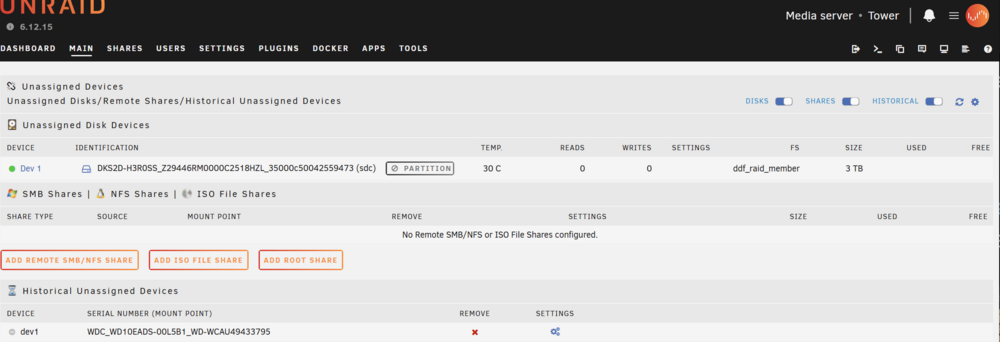
I see no options for that action:
-
There is no PSID printed on the drive for me to pass to the SEDUTIL command: All the google results tell me it would be printed in the empty box at the bottom of the label.

-
Interesting, it's not looking likely though. This is from the manual: https://www.seagate.com/www-content/product-content/constellation-fam/constellation-es/constellation-es-2/en-us/docs/100628615k.pdf and this is the from the log (screenshot posted above) I'll keep looking into it though, see what I might find.


-
Followed the documented procedure to upgrade a drive - I removed a 1 TB drive, and added in a used (new to me) 3TB. Start the array and get an error, device disabled: I try a few things, run a short smart test, run an extended Smart test - both pass. remove from array, add back to array. Reseat the drive, check the cables. Issue persists. So, I put the 1 TB drive back and Unraid now give me the message: Ideally I get the 3TB drive up and running, but honestly, I just want stability and to get things back and happy. Any suggestions? Thanks. tower-diagnostics-20250228-1905.zip

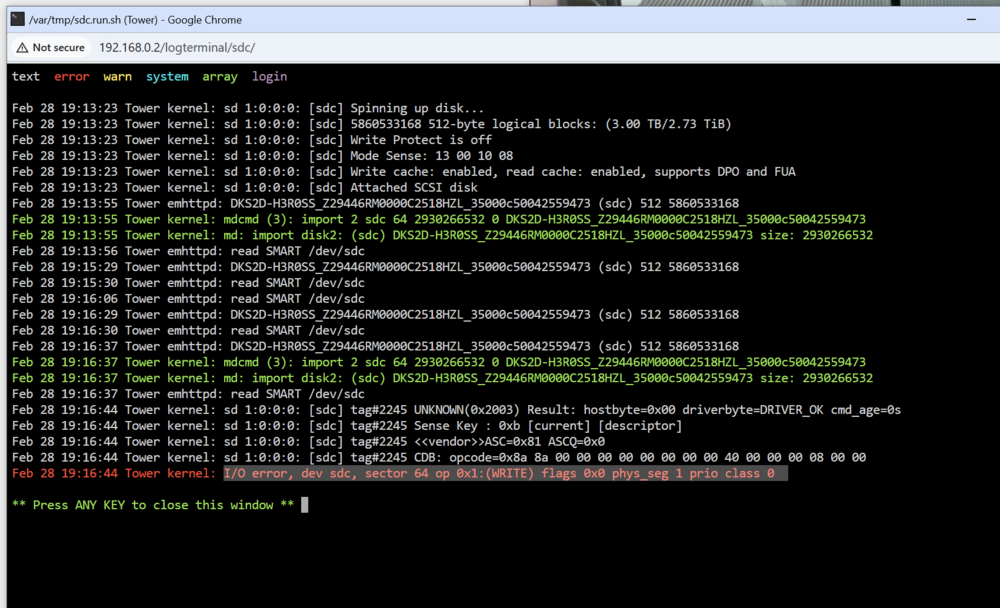
-
No recurrence, and the issue had been almost daily prior. Marking as resolved. Thank you.
-
No update yet. I noticed that both SDC and SDB were having issues prior to the SDB1 errors. Both disks connect to the same controller on the motherboard, and share a common power cord from the PSU. So far I've: Upgaded to 6.12.13 from 6.12.11 Moved one drive to different controller (and different SATA cable). On the other drive I swapped the SATA cable, leaving it connected to the same position on the motherboard. so I think, if it recurs, that leaves power supply / common power cable they share. Thanks.
-
Interesting. I'm pretty sure I've already tried different sata cables with no change (issue recurs). But I've not tried a different power plug. I'll swap both out and try again. Thanks.
-
I would just like to confirm that I need to remove (and throwaway) device SDB. Can someone point me to (or provide) the instructions to remove the disk from the Cache BTRFS array? Thank you. tower-diagnostics-20241104-1319.zip
-
how do I find that? Anything indicating that in the logs? any tests you suggest?
-
Stopped array, removed drives from cache pool, set pool drive size to (0). rebooted. started array Ran this command "wipefs -af /dev/sdx" stopped array, created pool, added both devices, started array. cache came up, but drives were unformatted. Selected the box to format, and unraid then set it up as a BTRFS cache pool by default. I enabled a daily balance and a weekly scrub on this pool. Not sure what best practice is. Started docker. moved back my AppData directory. Recreated my "Scratch Space" share, and enabled visibility on it. Reinstalled all my docker containers from "Apps -> Previous Apps" ..... and so far, I think I'm back and functional. This is my 2nd failure on this cache pool in (6) months. First failure this past summer was on a btrfs pool, so when I rebuilt it, I chose ZFS. I guess they both suck. I had no errors for years, before setting it up as a pool for redundancy last year. Wish there was more stability to this system.










