




wrenchmonkey
Members
-
Joined
-
Last visited
Everything posted by wrenchmonkey
-
Yeah, that's the conclusion I ended up coming to as well. After more playing around, I realized that it's never loading the HBA's bios options either. Thanks for confirming my suspicion. I'll order a Dell branded HBA. Hopefully it doesn't freak out about non-Dell drives.
-
I had just added the line to the bottom of the file, but I went back and moved it just in case that was causing it to not help. The original thread appears to be deleted, the thread I found it on doesn't really mention any specifics. No effect after moving the line under the Unraid OS label. This is where I placed that line.
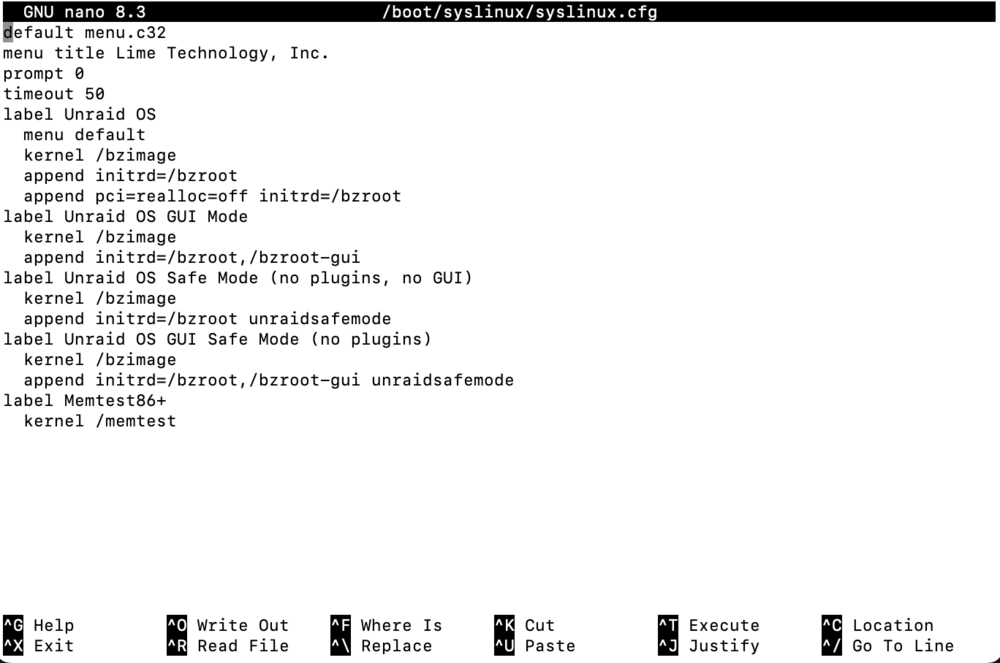
-
Hi Guys, I have been running Unraid for several years now, most recently in a Supermicro server board. The hardware has started becoming unreliable and not very power efficient, and I recently acquired a couple of R430s, which is a slight upgrade over the old hardware, and I decided to do a board transplant. After transplanting the board and installing the HBA, however, the R430 doesn't seem to detect it, and none of the SAS disks show up. I do have one SSD that is SATA, plugged directly into the board, and that's detected, but all of my other disks are SAS drives, and none of them are working anymore. It is flashed to IT mode, and has worked fine up until now. I tried adding "append pci=realloc=off initrd=/bzroot" to /boot/syslinux/syslinux.cfg, as mentioned here: But to no effect. I'm attaching my diagnostics file. I hope I haven't forgotten anything. Let me know I did. Kind of at a loss, and don't really want to have to completely undo my transplant if I don't have to! tower-diagnostics-20250405-1823.zip
-
I've been using this docker for the past several weeks, and have identified it as the culprit for filling up my Docker image. I have the storage for /Media and /Config properly pointed to shares outside of the docker image. Not sure what's misconfigured here. Has anybody else seen this?
-
So, I assume a "small file" would be anything smaller than the "chunk" size, right? I did some reading and it seems chunk size would be 1GB for data, and 256MB for metadata. Is that correct?
-
Thank you! I am doing that now. I moved a VM image to the other cache drive temporarily to clear some space, since I was getting a 'disk full' error when trying to balance. It's running now. Is this something that should be done routinely? If so, I will set it up in the user scripts to automatically perform this task. How often would you recommend running it?
-
tower-diagnostics-20210915-0935.zip
-
I'm pretty confused. A few days ago, I had an issue with a Plex docker filling my cache drive up with thumbnails/preview content. I deleted that data, and set Plex to not store that data, freeing up 172 GB of data. I have a VM that utilizes about 160GB of storage space on the drive (which is included in the 318GB total). I've been using that VM to download some large files, and then transferring them via SMB to the actual share drive later. Anyway, last night, the VM paused, and when I went to resume, I saw that the drive shows that it's 100% full, with 0bytes of available space, and 318GB in use. I rebooted the server, and it still shows that there's only 318GB of actual storage, even though it still lists the drive as a 500GB drive. (Screenshot and logfile attached). tower-syslog-20210915-1523.zip


