





905jay
Members
-
Joined
-
Last visited
Everything posted by 905jay
-
@ken-ji does this look better to you?
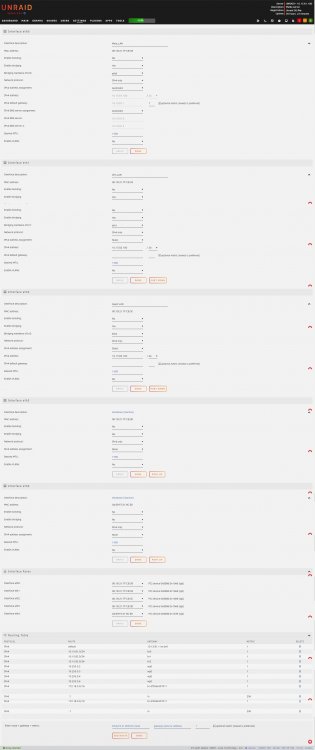
-
You're a beautiful man, Charlie Brown! I will look into doing this after "production hours" lol Thanks for your help on clarifying this for me @ken-ji
-
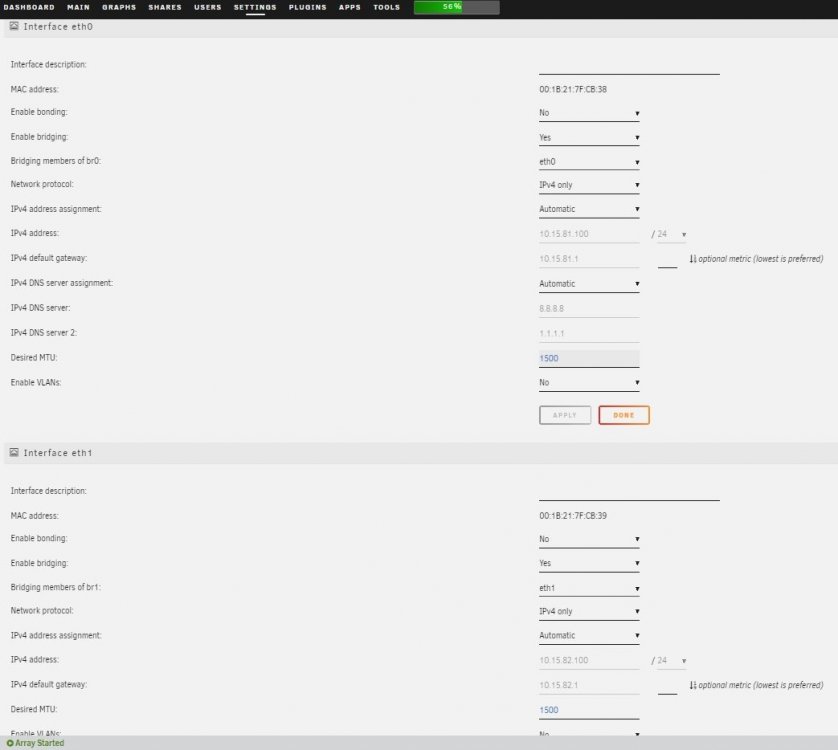
Would assigning the info based on the interface MAC in pfsense make more sense and just set it all to automatic? That way any gateway issues should be eliminated, right? I don't have a firm understanding of the networking, it's not one of my strengths.
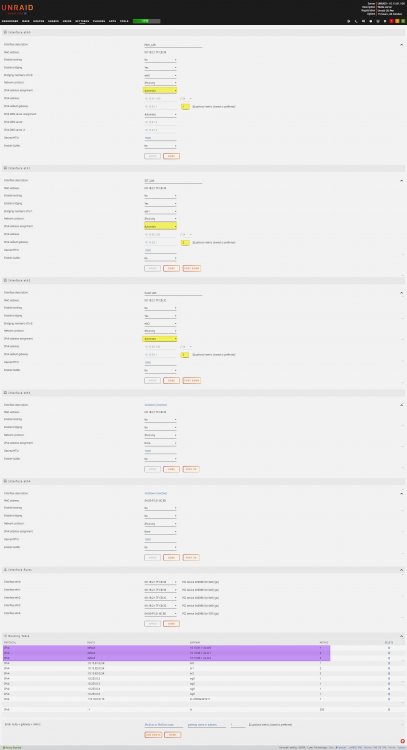
-
thanks for all the great info guys I realy appreciate it. I'm hesitant to make further changes to the configuration as I host a bitwarden as well as a confluence instance that I rely on for frequent daily use. I also don't want to not listen to you folks who know what you're talking about. Is it just a matter of me simply leaving the gateway blank for the interfaces eth1 & eth2? Should I leave it blank for all three interfaces (eth0, eth1& eth2)? I'm not using VLANs or any tagging, just 3 distinct subnets for an intended purpose.
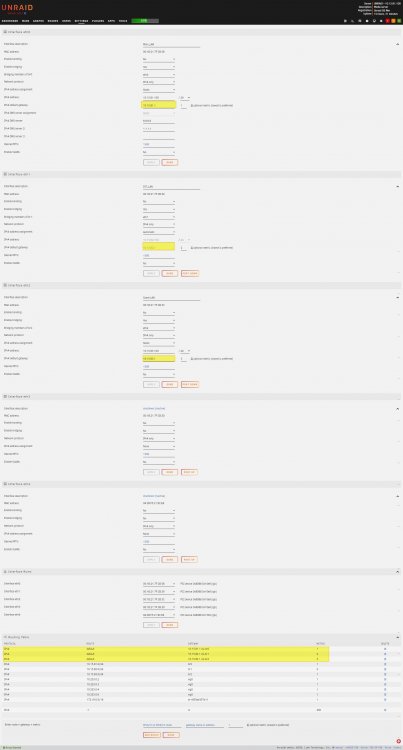
-
@kana thanks very much for your help. I spent the entire day spinning my wheels and couldn't understand where things went wrong. You've saved my sanity. Should I run anything else to further clean it up? I have a 4 port NIC 10.15.81.xxx is my Main LAN 10.15.82.xxx is for IOT devices 10.15.83.xxx is for Guest & Family LAN I am running multiple piholes on unRAID for each of those interfaces (eth0 is Main, eth1 is IOT, eth2 is Guest) so I would like o keep all 3 interfaces connected as I presently have them. I run HomeAssistant which is using br1 (eth1 interface) and I also run Wireguard on my unRAID server and use it frequently. Thanks again for saving my ass, and my sanity. Just seeking your advice so I don't screw anything up
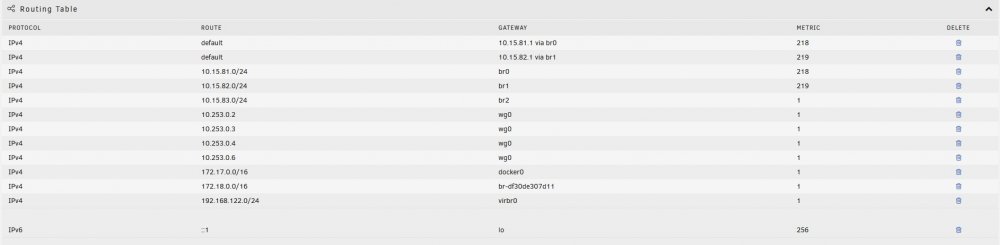
-
The routes highlighted in Yellow, can't be deleted for some reason. I have docker and vm manager off, and went back into network settings and I can't get rid of it
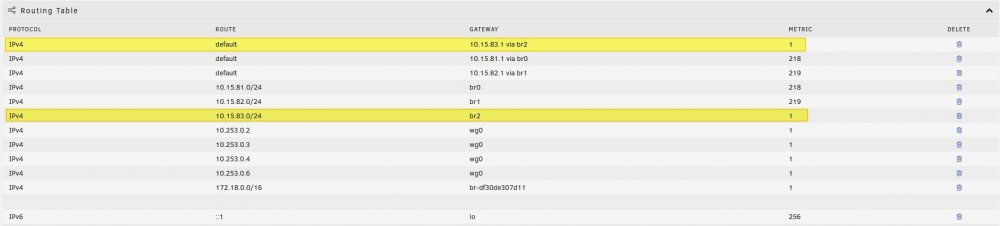
-
unraid-syslog-20200902-1913.zipI've got a similar issue unRAID and it's containers cannot access the internet. I can't ping out /nslookup /traceroute out. I was playing with some pfsense firewall settings last night and thought, perhaps I messed something up, somewhere. So I reverted to the known good working backup, but still no dice. unRAID server has internal connectivity. I can access everything on local IP:PORT piholes have been removed from the network to rule them out, pfsense is giving 8.8.8.8 /1.1.1.1 as the DNS servers I have VMs hosted on unraid that have internet access, and are assigned an IP from pfsense based on MAC address. I also have some containers hosted on unraid, that are given external SSL access (bitwarden /nextcloud /confluence /homeassistant) They can all be accessed internally with IP:PORT as well as https://service_name.com But I cannot access them from outside the network. I haven't changed anything on unRAID that I can think of beside enabling an interface on my 4 port NIC, to add to another AP for guest access, but I've reverted all those changes. MTU is set to 1500 per recommendation above I have restarted pfSense, unRAID, my AP's just to rule things out, and as mentioned, removed the piholes and am using 8.8.8.8 /1.1.1.1 as DNS for testing to see what the hell is wrong with my setup. Any help would be greatly appreciated. unraid-syslog-20200902-1913.zip
-
Left the parity to runovernight, and it is at the exact same place it was at yesterday late afternoon 98.7% 3 Hours 50 minutes remaining for at least the last 12 hours. I've given up on the process now, i've aborted and will install the LSI card and see if that helps any any i5unraid-diagnostics-20190829-1236.zip unRAID
-
@Frank1940 thanks for the follow up on this. Yes initially the server was rebooting every night for an unknown reason. That seems to have been fixed by not having docker and vm services running. The parity is taking forever to run, that is the current concern. due to the random freezing from before (unresolved) the parity was totally messed up. I see what you mean in terms of the read and writes to the disk in the screenshot, but i'm unable to isolate what is causing that, to those disks only. I thought the point of unRAID was to spread it out across all disks (read /write /data), not necessarily evenly, but better than this. Some people point to the fact that 6 disks are on the Intel controller, and 2 are on the Marvell controller on the motherboard. I am holding in my hand an LSI card that arrived today. Once the parity rebuild is complete, I intend to install this card and use it exclusively. Do you think this parity will ever rebuild? Or am I best to stop this now, install the card, and rebuild the parity again?
-
I have no explanation for that other than it is how it was shown to me, and recommended that I setup this way. But it seems like there are 10 people, who all know what they are talking about, giving me 10 variations on doing everything under the sun. Typical internet stuff...everyone is an expert on everything behind the cloak of an avatar on a forum. So far a 6TB parity drive sync has taken approx 2 days to complete and still isn't close to being finished. At 11:30pm last night it shows 93%, 1 hour to complete (approx.) This morning it shows 93% and a day left to complete (the transfer rate went down from 100MB/s to about 5MB/s) from 8am this morning to now, it has moved 3% (give or take)
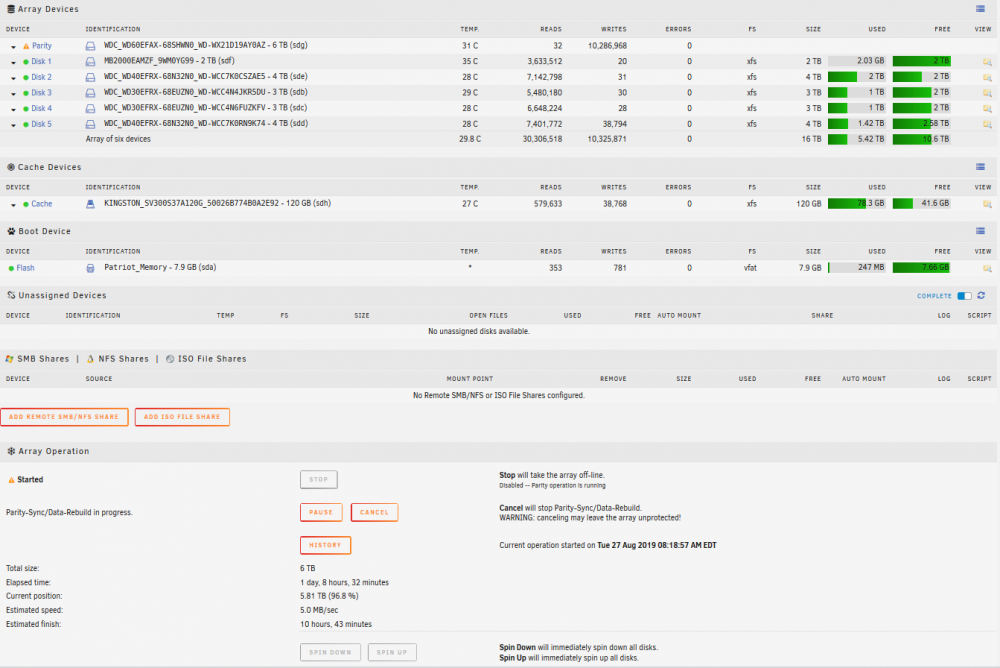
-
mover runs hourly, however there is nothing running at this time in terms of services that I am aware of docker service is disabled, as is VM service
-
Hey @trurl and @johnnie.black the parity was running for about 24 hours. I started it Monday morning and it went into Tuesday Morning. I decided to stop it yesterday morning and restart it because it was stuck at about 90% and showing 900+ days to complete. I figured something was wrong, and restarted it yesterday morning. At 11:30pm last night it shows 93%, 1 hour to complete (approx.) This morning it shows 93% and a day left to complete (the transfer rate went down from 100MB/s to about 5MB/s) Can anyone help me isolate what the issue is here? It's been stable otherwise, and hasn't crashed on me at all but that problem has lead to this problem. Diagnostics and syslog attached i5unraid-diagnostics-20190828-1309.zip unRAID(1)
-
@johnnie.black @trurl thanks very much for your input I have the docker and VM service disabled again until the rebuild is complete and I implemented the change that @johnnie.black recommended I will report back here once that is complete
-
@trurl would you be able to help me figure out if it is a container (which one, or which combination of containers) or if it is a VM that is causing all these issues that I'm seeing? I've replaced the memory on the server, (2x8GB + 2x4GB), and formatted the parity disk and am rebuilding the parity now as we speak. I feel that perhaps I've misconfigured something but i'm unsure of what it may be, and don't want to have to constantly have to go through this parity rebuild due to sudden freezing and power off situations. Is it possible that somewhere I have over-provisioned memory or CPU resources to a docker (or multiple dockers) ? Is there anything else that I can provide the community that may be able to point to where the shortcomings are with this system?
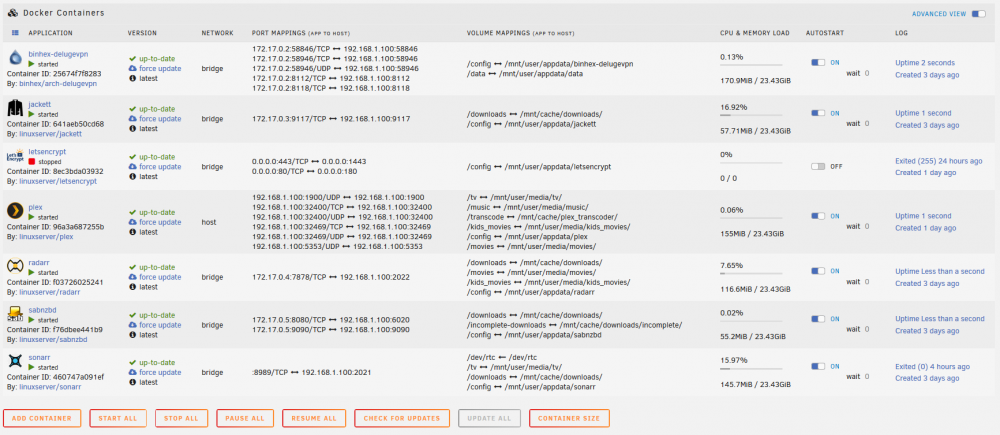
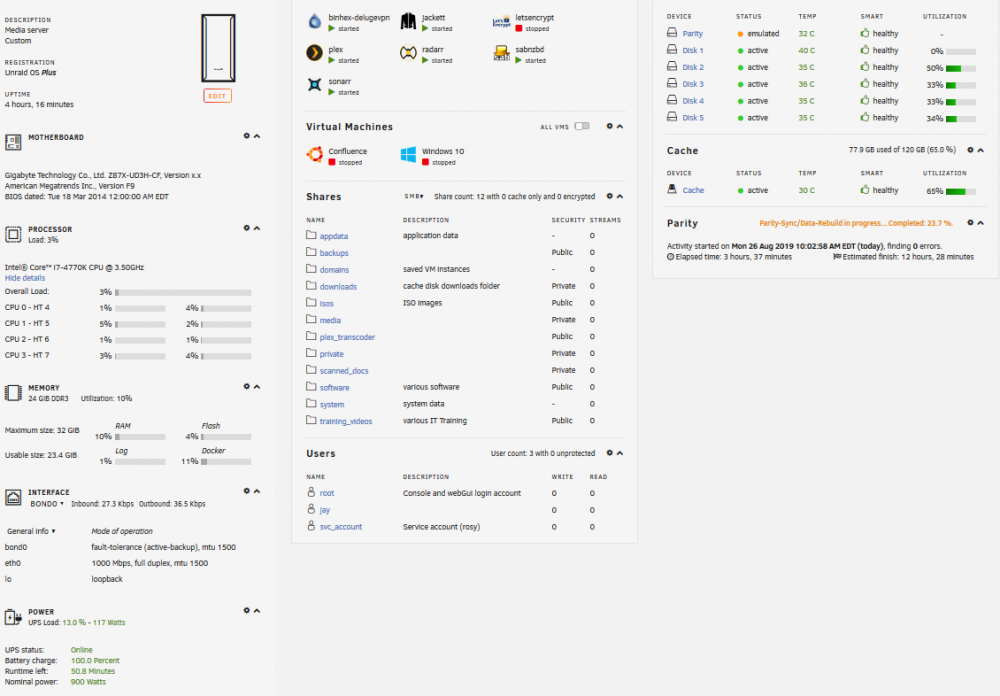
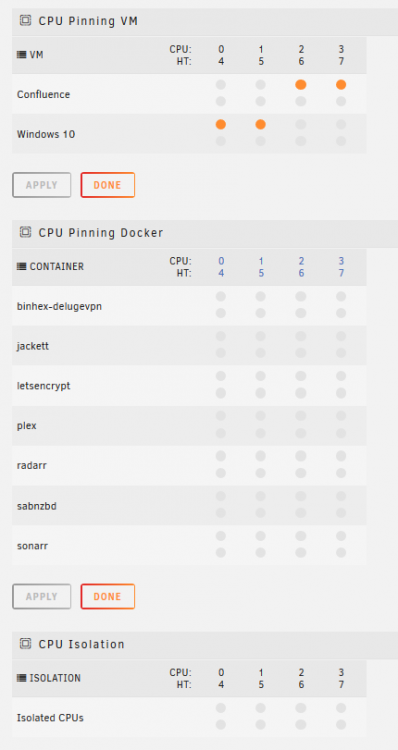
-
thanks for that info, i have made the change
-
@trurl when I get my LSI card (hopefully next week) and I plug it in and boot the server, do I have to completely reconfigure all my disks? is this a major undertaking on my part? Or will unRAID just not give a shit, as long as it can see all the disks?
-
Bios is fully up to date, yes Defaults in BIOS are being used, no overclocking Cooling is a Noctua CPU Cooler, brand new I have 2 disks hooked up to the Marvell. That can't be changed until I get my LSI Logic card delivered so I have to wait on that. I have decided that it may be best to remove the parity disk from the array, preclear it, and add it back in. See if that at least helps that situation
-
@trurl diagnostics posted just above.
-
server booted in safe mode, with docker and VM services disabled, it's still standing strong. Some observations: The parity rebuild has been increasing in time, from 20 days, to 190 days, to now over 900 days. Would it make sense for me to format and redo parity fro scratch? The parity disk was brand new for this server build 2 weeks ago. It appears that without docker containers and VM services running (and in safe mode) the server is stable for now. Would you agree that this isn't a hardware issue per-se, but rather misconfigured software (somehow /somewhere)? Diagnostics file is attached i5unraid-diagnostics-20190826-1229.zip
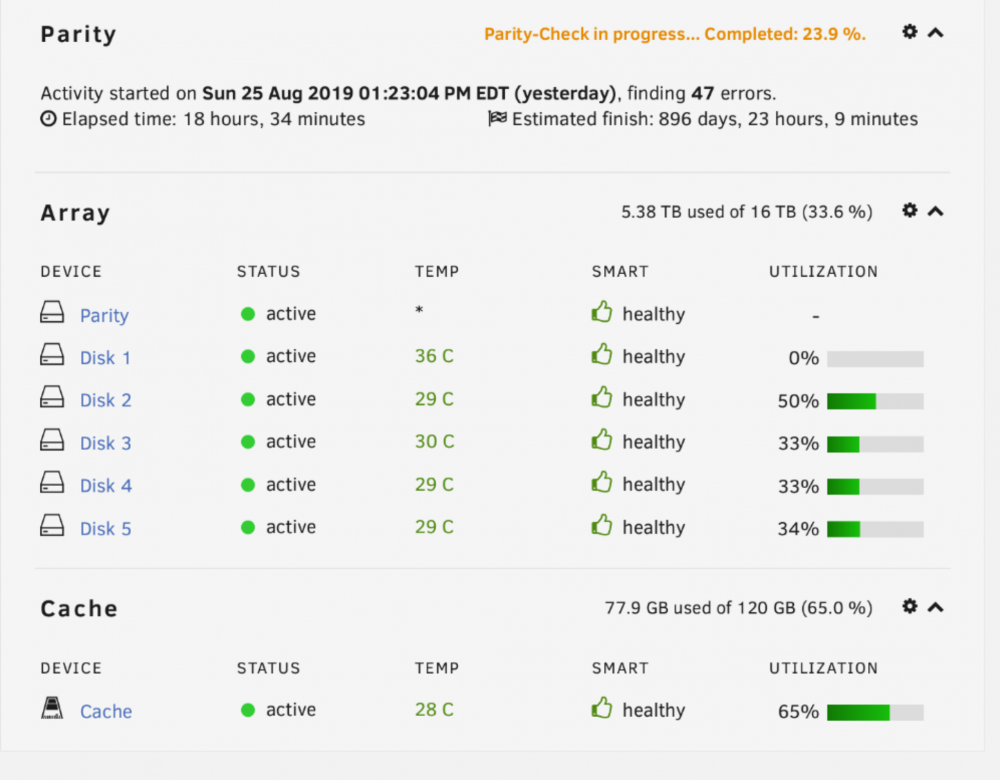
-
so....booted into safe mode and noticed docker and vm services start automatically shouldn't safemode mean that none of these services would automatically start so as to enable troubleshooting of issues? i've disabled those services and started the array, so docker and vms aren't running also, i am mirroring syslog to flash so see if something gets caught that perhaps the syslog server itself is missing
-
memtest has been running for 4.5 hours and no errors
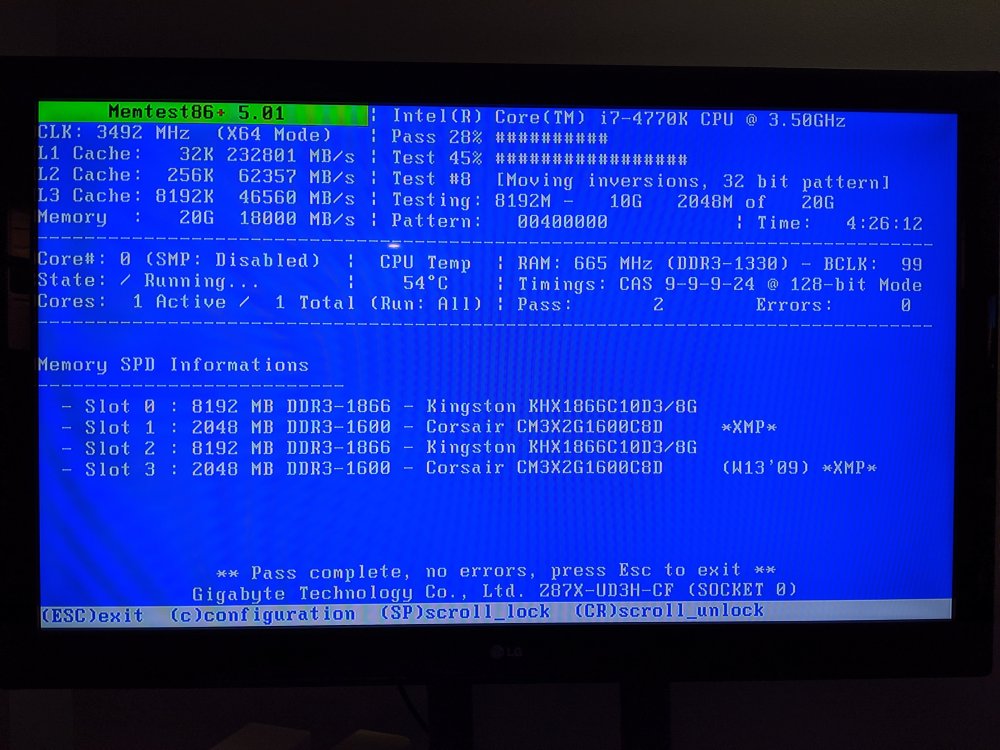
-
thanks again @trurl did you happen to see anything they may offer a clue? I'm grabbing at straws at this point
-
so the issue appeared again overnight, as it has the 3 nights before. UPS reports no issues I will be out of the house for a while today so I've decided to run the extended memtest, and assuming that passes everything, I will boot the server when I get home into safe mode and attempt to rebuild the parity again (5th time) could there be an issue with the USB flash drive that unRAID boots from perhaps? would that appear in the syslog? unRAID(5)
-
hey thanks fer getting back to me I did read your previous post and have since switched it to Cache Yes. A memtest was done, yes, and it passed. I thought of that myself earlier today and did that when it froze on me this morning. Does anything else pop out at you?
-
thanks all your efforts! @trurl what do you recommend I use for the downloads share? Cache Only? I had set it up this way on the advice of a buddy to get me going then i'd figure it all out from there so the webGUI was frozen again, wasn't accessible via ssh. It turns out that I did set this up to ship it's logs over to a qnap acting as a syslog server so I have a log here I can upload. I attempted to log into a root tty and try to run the diagnostics but no commands run at all, the tty just hangs unRAID_messages_file













