




iD4NG3R
Members
-
Joined
-
Last visited
Everything posted by iD4NG3R
-
In the end that would only be relevant the first time a (sub)folder's content is copied over to the read cache, the system already knows what files it moved to cache and what files have been added/removed to/from the array that are (also) available on the read cache. You're going to need to deal with file/folder changes, so you're going to have to somehow keep track of what files are active on the read cache anyway. At that point it makes little difference if it's one, dozens, or even thousands of files in a particular (cached) folder. Leave it up to the user if they want it and at which thresholds/limits it should do that. File was added to folder X > should files from folder X be on the read cache? if so > Copy it to cache too. That would also be beneficial assuming we can use the existing write cache for read caching, since you wouldn't need to write new files to it twice, you'd just copy it over to the array while leaving the cached file where it is. Hence user setting. For media consumption it would be extremely beneficial to have the entire show loaded in cache instead of having to fetch individual episodes or movies from the array. Leaves the disks spun down or at the very least the heads in resting position as much as possible. Anyway, probably a little too in-depth for a feature request. I'd personally be mostly interested in the ability to (preemtive) cache folders, but the caching of single files would already be a nice upgrade. 👍
-
Eh, wouldn't say that it makes things much more complicated. Simply ask the user (through settings) if they want to cache the entire folder or just single files. In regards to how old this request is, 3 months isn't that long right? Feature requests might make it through if enough people show interest! 😃
-
That really depends whether it would (preemtively) cache the rest of the folder (possibly even X levels above that folder) or just that one accessed file. If it's the latter it would be useless for my own usecase. (But still a nice to have for a lot of people!) The vast majority of my own files are only read once in a blue moon. However if a file is accessed, the rest of the folder is usually also read in a relatively short period after that.
-
A read cache would be lovely, personally I'd like to at least see the following 2 scenarios: Frequently accessed files. Speeds up repeated reads. The rest of a folder if more than X threshold of Megs was read from a file in said folder. (Allow us to select how many levels "up" it can cache) While not too interesting for moving files across the network, it's pretty insane what this could do for example in Plex or other media server. I'm somewhat surprised that this isn't a thing already, we have the write caching mechanism to keep the array idle as much as possible and speed up transfers - but as far as I'm aware there is no way to automatically move long(er) term storage (back) to the cache only when a file or folder is actually accessed. I'd much prefer to have reads more condensed at (season/[movie] series) folder level that I can actually spin the rust down knowing that it is unlikely that it'll need to be spun up again shortly. The bottom line is that I'd imagine a lot of people would like to prevent their array from being accessed as much as possible. Active disks draw a lot more power than an SSD does and most people want to minimize how often they spin disks up and down.
-
For anyone stuck; tried basically all suggested solutions to no avail. Ended up just doing a CURL from the docker's console: You can grab the token over @ https://www.plex.tv/claim Unsure if removing the PlexOnlineName, PlexOnlineToken, PlexOnlineEmail and PlexOnlineHome key/value pairs from Preferences.xml is required beforehand, but I had those removed from a previous attempt so. After like 10 seconds a big 'ol wall of text will appear in your console and it should be claimed again.
-
That still doesn't explain the static upper limit to the connection speed [per server] regardless of the amount of available connections. If available connections were the issue I'd see inconsistent maximum speeds but consistent speeds testing different ovpn servers. I'm seeing the exact opposite happen. 🤔 Has Nord started to bottleneck p2p connections in the past year? Has Nord started using slower servers in the past year? Any other changes that could relate to p2p speeds? That's what I'd like to have an answer to since available connections don't seem to be the [primary] cause.. 'm gonna take that question to a different place though considering that doesn't have much to do with DelugeVPN at this point. I appreciate the response.
-
Read the entire thing; Combined with; It doesn't explain the relatively sudden/huge drop in speed, speeds I was having for well over 3 years despite Nord never having supported P/F to begin with. I'm quite content with the 8MiB/s I'm getting right now, but would like to figure out why it dropped so harshly in the first place.
-
ItConfig can, although I have no way to actually test that for you. Refer to this post from raiditup for information on how to get it working. Funny coincidence that I even knew about that plugin, dealing with an unrelated issue and only just bumped it myself. ----------------- Has something changed on NordVPN's side which is getting me bottlenecked severely? I've tried several of their P2P servers now, which bumped me up from 3MiB/s to 5MiB/s initially. Following the above post I managed to get the speed up to 6MiB/s, but that's where I've hit another roadblock. I used to get speeds in the 10-14MiB/s range last year. It wasn't that big of a deal, so I never really bothered looking into it, but now that I have some more time I'd like to find the root cause of it. Disabling the VPN instantly sees speeds rise up to well over 25 38MiB/s, so it's not like the physical connection is too slow. Speeds have been tested with the Ubuntu ISO download for consistency, extremely popular downloads from indexers show similar speeds. I'm well aware that PIA is a lot better pick for Torrents, but with my Nord subscription still being active for another year I'd prefer not switching over right now. Edit: It was doing 20MiB/s+ back in February last year, but I remember it consistently being about 12MiB/s up until at least August/September, first time I noticed that the download speed dropped down to 2-3MiB was early this year. (I rarely have need to look at the WebUI, only noticed it when I wanted to manually add a torrent) Edit2: Gah, the more I toy around with this the more it seems to be Nord's servers being slow and inconsistent between configs. Tried like 8 more ovpn configs, fastest one so far peaks consistently around 8MiB/s, still a major improvement over what it was even a few hours ago - but nowhere near the speeds I used to have.
-
That was honestly the one thing that I didn't try, and indeed gets it working. /facepalm Strange, I've always ran in on it's own IP. Thank you!
-
I meant that with the VPN enabled, the webGUI becomes inaccessible [but with it disabled it functions]. The message was intended as a continuation of my first message. You're absolutely right, I'll make sure to make that more clear in any future messages. But back to the issue at hand, is there anything else you'd recommend me to try? All of this only started happening after I got myself a new router. Followed most of, if not all of the FAQ's on the repo. I've reinstalled the container several times now (both from scratch and from previous configurations), restarted the Docker service a few times, even went as far as to restart the entire server. Since the logs aren't throwing any obvious errors I'm kinda stuck..
-
Which is what I'm trying to say. When VPN_ENABLED is set to false, I can access the webGUI. The second I set it to true, I cannot.
-
Accessing it from 192.168.1.101, the unRAID server itself runs on 192.168.1.100. The container runs at 192.168.1.51. The container is active, and I can ping it just fine. As stated before, the second I disable the VPN I can access the webGUI, the same kinda behaviour that occurs when DelugeVPN fails to connect to the VPN. (Which according to the logs doesn't seem to happen..) Privoxy seems to function even when I cannot access the webGUI, although I have no idea if it's actually going through the VPN or my own IP.
-
Here you go: supervisord.log The last bit has been looping ever since. Interesting find almost a day later; Privoxy seems to work, despite Deluge itself not functioning at all when the VPN is enabled. 🤔
-
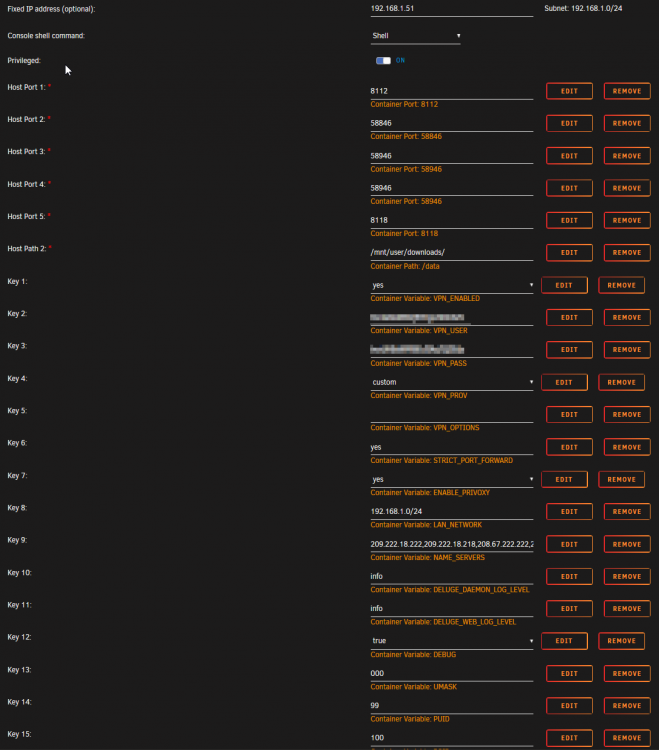
Right, just received my new router, got a new external IP and moved over to a different internal IP range (192.168.1.0/24 from 10.0.0.0/24) and now DelugeVPN utterly refuses to launch the webUI when I enable the VPN. Without it it functions just fine. I have not changed anything to the configuration besides giving it a new fixed IP and changing the LAN_NETWORK variable to the new network/mask. I'm using NordVPN, tried switching to a different P2P server to no avail. What log file can I supply for more information? Or does someone already spot the issue.. I'm kinda stuck myself.
-
Cheers, this did the trick.
-
To prevent unnecessary spin-up of my array, and not to wear down my SSD cache any further I decided to add a basic USB disk to my server and use UD to create a share on it, I somehow messed up horribly and have no idea how to fix this. Dec 6 02:01:32 Tower unassigned.devices: Adding disk '/dev/sdh1'... Dec 6 02:01:32 Tower unassigned.devices: Mount drive command: /sbin/mount -t xfs -o rw,noatime,nodiratime '/dev/sdh1' '/mnt/disks//mnt/disks/download_cache' Dec 6 02:01:32 Tower unassigned.devices: Mount of '/dev/sdh1' failed. Error message: mount: /mnt/disks/mnt/disks/download_cache: /dev/sdh1 already mounted or mount point busy. Dec 6 02:01:32 Tower unassigned.devices: Issue spin down timer for device '/dev/sdh'. Dec 6 02:01:35 Tower unassigned.devices: Format disk '/dev/sdh' with 'xfs' filesystem result: meta-data=/dev/sdh1 isize=512 agcount=4, agsize=19535700 blks = sectsz=512 attr=2, projid32bit=1 = crc=1 finobt=1, sparse=1, rmapbt=0 = reflink=1 data = bsize=4096 blocks=78142798, imaxpct=25 = sunit=0 swidth=0 blks naming =version 2 bsize=4096 ascii-ci=0, ftype=1 log =internal log bsize=4096 blocks=38155, version=2 = sectsz=512 sunit=0 blks, lazy-count=1 realtime =none extsz=4096 blocks=0, rtextents=0 Dec 6 02:01:38 Tower unassigned.devices: Reloading disk '/dev/sdh' partition table. Dec 6 02:01:38 Tower kernel: sdh: sdh1 Dec 6 02:01:38 Tower unassigned.devices: Reload partition table result: /dev/sdh: re-reading partition table Dec 6 02:01:38 Tower unassigned.devices: Adding disk '/dev/sdh1'... Dec 6 02:01:38 Tower unassigned.devices: Mount drive command: /sbin/mount -t xfs -o rw,noatime,nodiratime '/dev/sdh1' '/mnt/disks//mnt/disks/download_cache' Dec 6 02:01:38 Tower kernel: XFS (sdh1): Mounting V5 Filesystem Dec 6 02:01:38 Tower kernel: XFS (sdh1): Ending clean mount Dec 6 02:01:38 Tower unassigned.devices: Successfully mounted '/dev/sdh1' on '/mnt/disks//mnt/disks/download_cache'. Dec 6 02:01:38 Tower unassigned.devices: Issue spin down timer for device '/dev/sdh'. Dec 6 02:02:09 Tower kernel: sd 7:0:0:0: [sdh] tag#0 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08 Dec 6 02:02:09 Tower kernel: sd 7:0:0:0: [sdh] tag#0 Sense Key : 0x5 [current] Dec 6 02:02:09 Tower kernel: sd 7:0:0:0: [sdh] tag#0 ASC=0x24 ASCQ=0x0 Dec 6 02:02:09 Tower kernel: sd 7:0:0:0: [sdh] tag#0 CDB: opcode=0x2a 2a 08 12 a1 75 b2 00 00 02 00 Dec 6 02:02:09 Tower kernel: print_req_error: critical target error, dev sdh, sector 312571314 Dec 6 02:02:09 Tower kernel: print_req_error: critical target error, dev sdh, sector 312571314 Dec 6 02:02:09 Tower kernel: XFS (sdh1): metadata I/O error in "xlog_iodone" at daddr 0x12a17572 len 64 error 121 Dec 6 02:02:09 Tower kernel: XFS (sdh1): xfs_do_force_shutdown(0x2) called from line 1271 of file fs/xfs/xfs_log.c. Return address = 000000007d943554 Dec 6 02:02:09 Tower kernel: XFS (sdh1): Log I/O Error Detected. Shutting down filesystem Dec 6 02:02:09 Tower kernel: XFS (sdh1): Please umount the filesystem and rectify the problem(s) I assume it happened because I tried to mount it to "/mnt/disks/download_cache" not knowing that "/mnt/disks/" is already appended in front of it automatically...




