



dlchamp
Members
-
Joined
-
Last visited
Everything posted by dlchamp
-
Which version? SE or SA? So far, that looks 100% normal. You said you cleared everything, but did you also delete the steamcmd directory?
-
`/mnt/cache/appdata/valheim/Steam/logs/`
-
And did you add -debug to the run command and generate the debug.log?
-
I don't know if there is one available for SA yet, but there is a serverbenchmark mod that you can install and run on SE servers. Gives you some decent insight into what to expect performance-wise. https://steamcommunity.com/sharedfiles/filedetails/?id=2221733141 In my experience, the performance difference is minimal, however, the resources, mostly RAM, is the biggest difference. SE Island server is around 5GB on a fresh new install where SA, for me at least, sits around 10GB.
-
Or your password isn't configured correctly, or you mistyped it.
-
Then it looks like it's an issue with your version of the game it seems. My version purchased from Steam seems to have no issue. You could attempt connecting directly while you're testing: - ` (backtick) to open the console - type "open <your IP>:8899" (no quotes) - Enter. To see if a direct connection will work. And it's just your game being at least partially broken for using the official server list.
-
The docker container has a parameter field. It includes the listener port, by defaults it's `?Port=7777` make sure it's changed to match your updated port.
-
Gotcha. It shows for me:
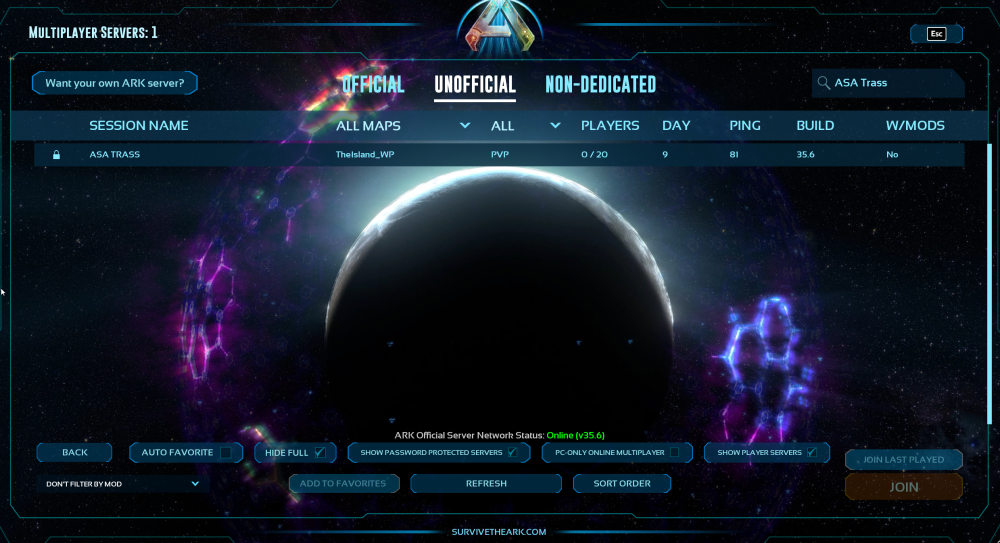
-
What do you mean?
-
If you change away from the default ports, you have to make sure to delete the existing config and re create them with the new port(s). Make sure you set the startup script to the new port as well and that you're port forwarding UDP. Testing UDP ports with something like canyouseeme.org will never show as reachable. UDP is quite a bit different than TCP and port checkers like that typically will see it as closed. Also, make sure when you're searching, you have the following checked: - HIDE FULL (checked) - SHOW PASSWORD PROTECTED SERVERS (checked) - PC-ONLY ONLINE MULTIPLAYER (unchecked) (not sure how to make this PC only - probably a config thing) - SHOW PLAYER SERVERS (checked) For what it's worth, I just spun up a new container on a non default port and had no issues getting it to appear within a couple minutes of the server coming online. Make sure the server name is correct. When you look in the logs, you should see this: [2024.02.28-03.10.27:190][ 0]LogCFCore: Warning: Couldn't load mods library from disk [2024.02.28-03.10.27:191][ 0]LogCFCore: User context not loaded from disk [2024.02.28-03.10.27:403][ 0]Primal Game Data Took 0.21 seconds [2024.02.28-03.10.27:580][ 0]Server: "your session name" has successfully started! [2024.02.28-03.10.36:494][ 0]Commandline: "TheIsland_WP?listen?SessionName=your session name?ServerPassword=somepassword?Port=8888?ServerAdminPassword=secret_password" -WinLiveMaxPlayers=20 -server -log -NoBattlEye [2024.02.28-03.10.36:494][ 0]Full Startup: 9.89 seconds [2024.02.28-03.10.36:494][ 0]Number of cores 20
-
The stupid lengths people will go to to try "hide their IP"... You're not a target.
-
The game server is hosted locally, so IPs should be local IPs. Your firewall/router should handle the port forwarding of the external IP to the local IP. Restrictions it has should have no impact on locally hosted services. Either they packet gets through or the firewall blocks it. If you research the actual game server settings - https://survivalservers.com/wiki/index.php?title=Sons_of_The_Forest_Server_Settings You'll find that the IpAddress field is the IP that the server is listening on. Leave it 0.0.0.0 or make it the local IP of the server. It looks like, yes.. you need all three ports. 8766 is for the actual game netcode to use (client/server connection) 27016, which is the typical steam query port. This is how steam lists the server for others to see. 9700 is the BlobSync port that seems like it does some backend syncing of various states between server and players. It's an unfortunate side-effect for Ich, but he provides the containers and support for them. I've seen him spend way too much time helping users with actual hosting of the games. Go do your own research on how to host the games and the settings they need and the firewall configurations to go along with it.
-
It's an unraid/ilinux command. Which is typically what it means when it says " You can change the value by executing this command on the host as root": host being the host machine, or the machine that is running docker.
-
honestly, this is kinda.. pointless. Your public IP isn't some secret identifier. Every website you visit logs it. Every botnet in the world is scanning random IPs and ports constantly and yours is one of them. As long as you don't have unnecessary ports open and are not hosting some severely out of date or insecure service on those ports, you're fine 99.99% of the time. Could someone identify your ISP? Sure. Could they identify where in the world you might be? Also, yep. Can they pinpoint the city, address, or any identifying information about you? Not a chance. best they could do is figure out within maybe 50-100 miles of where you might be, and that varies greatly by which DC you're connected to and how close to it you are.
-
You kind have to tell us what server? This forum thread is support for more than 100 games.
-
Looks like your system is having issues connecting to docker hub. Not directly related to this or any other docker images.
-
If you search this thread you'll find at least 5 comments with an answer to that.
-
Port forwarding is how your firewall knows how to map traffic coming from the internet (WAN) and direct it to an internal device (LAN) based on the port. So, you would use whatever port(s) the service you're using is expecting traffic on and then the IP would be the local IP of the server the traffic needs to be directed to.
-
It actually says `GAME_PARAMS` in the launch parameters field? Use the gus.ini to set sever name, rcon enabled/rcon password, motd, etc. Make sure everything else that needs to be a launch param is a launch param. `?Port=7785?QueryPort=27019?MaxPlayers=10?RCONEnabled=True?RCONPort=27039?customdynamicconfigurl="http://172.17.0.4/dynamicconfig.ini` Should look something like this, minus any extra params you don't need.
-
That's normal and unrelated. I had similar issues, but it's because you're likely missing launch parameters and the Arkserver service is defaulting your gus.ini For instance, I had issues with this previously and it was because I was trying to set all config options in gus.ini, but you cannot. You must at least define the passwords in the container config. https://forums.unraid.net/topic/79530-support-ich777-gameserver-dockers/?do=findComment&comment=1335242
-
Sorry to hear. I've been running that image for about 4 months now, restarting for updates, had a couple server restarts in between then for Unraid upgrades and I did not experience any of that. I didn't change anything default either, though I do backup my game servers' `appdata/game_dir` 2 times per week as part of my weekly appdata backup routine. so, unfortunately I can't say what would cause it, but it's not something the container would have done.
-
Yeah, I forgot they added that. Fortunately when I did this recently, my original save was local already.
-
You should be able to just: 1. stop the server 2. Find your local saved world in `%localappdata%low/IronGate/Valheim/worlds_local/` 3. Copy your .db and and .fwl for your server name 4. Paste it in `/mnt/user/appdata/valheim/.config/unity3d/IronGate/Valheim/worlds_local/` 5. start server. This assumes you haven't changed any defaults.
-
You don't need to forward ports for local connection, but you do need to forward them if you expect the game to know your server exists. If you don't want to forward, you should be able to go into Steam > View > Game Servers, then add your local IP and the correct port. I don't know that game specifically, but if the container has a Steam UDP or similar port (not a game port) that is the one you should use in the Steam. Edit: Yes. You should be able to add your server in steam using {local_ip}:27015 since that is the assigned query port for steam.

-
Make sure that you deleted and recreated the UDP and Game port items so you can correctly map the new ports. Also, Hasheim is showing 0.0.0.0 because the container isn't running, so there's no IP yet.



