



-Reddit.png.1a2908815c05bd678f6c8b6397b00407.png)
tr3bjockey
Members
-
Joined
-
Last visited
Everything posted by tr3bjockey
-
How do you even manually delete it? I tried with VNC and it doesn't delete it.
-
Didn't know I could browse from the share menu. Very cool. Now where's the delete button? I tried right clicking on the folder and opening the folder and also right clicking but no delete button.

-
Hello, can anyone help with this? I aborted the backup because it was getting huge (I had to exclude some things). After making the changes, it created a backup. I then tried to delete the bad backup that is +14gb with the "-failed" name and it won't let me delete it. It has the r-x permissions. How do I delete this? I'm using binhex-krusader as a file editor.

-
Thanks for the tip. My shutdown time-out was set to 90. I bumped it up to 120. I timed stopping the array and it too 45 seconds. (my cache stats showed 10+gb). What's weird is that it had been over an hour since I copied a large file to the array (which gets copied first to the ssd raid 1 cache drive, the manually I press move to move it to the mechanical drives. I assumed that when I stopped the array, it finally dumped the cache of the move to the mechanical drive. When I restarted the array, the cache stats showed less than 4gb. Any ideas why it holds the data hostage in cache instead of writing it to the array immediately? I don't have the server on a UPS, so now I'm even more paranoid about corruption in case of power failure. Please correct me if I'm wrong but to make sure that there are no corruption issues, every time I copy data to the array to the array I will have to: 1. after copying, press the move to move it from the SSD cache to the mechanical drives. 2. after the move is done, stop all dockers. 3. once all dockers are stopped, then stop the array and wait for the array operation section to tell me "stopped. configuration valid" 4. If I'm not done for the day using the server, restart the array. 5. If I'm done for the day, then go to the power menu and do a shutdown. Thank you for responding JorgeB. I did a non correct one and no errors. Is there a command besides "stop array" that I can run to flush the cache without needing to stop the array, to save me some steps as detailed above?
-
Should I perform another parity check? If yes, should I check/uncheck the box?
-
Is there a way to find out which drive/folder/files were affected by the parity error?
-
For next time I'll stop the array before the next shutdown. 1. Is there anything in the diagnostics that point to anything being wrong? 2. Should I perform another parity check? If yes, should I check/uncheck the box? 3. When do I know it's safe, to shutdown after I stop the array? 4. Is there a setting that I can turn on to tell Unraid to flush the cache instantly without needing to shutdown the array to force it? 5. Is there a version of unraid, that is later than my current version, that automatically flushes the cache when a shutdown command is given, and does not power off the server until it's done writing?
-
The same issue is happening again that happen 7 months ago. I've been making sure there's clean shutdowns by clicking the spin-down button first, waiting for all the disks to show that they've spin-down, and then clicking the shutdown button. I still get all of a sudden 4355 errors on a parity check. The only that has changed since the last parity check on 9/18/23, is that after that parity check, I upgraded from 6.10.3 to 6.12.4. So this is the first Parity check I've done after upgrading OS. What do you suggest I do for troubleshooting? FYI, I don't use VM's. I just use unraid for plex. I don't leave the server up 24x7, I only turn it on to backup my PC, add movies to plex, and watch movies on plex. My disks have power on hours ranging from 2 to 6 months, but load cycles vary from 611, to 25000. tower-diagnostics-20231029-1102.zip
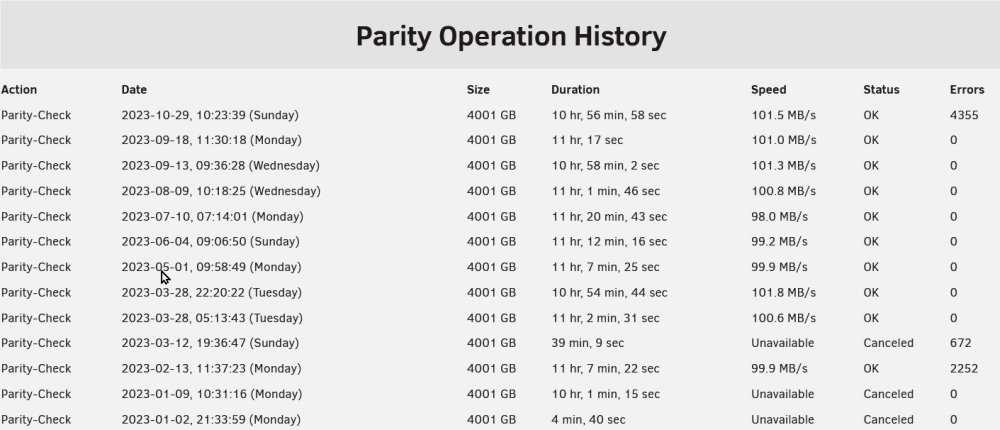
-
No unclean shutdowns. The only thing that comes to mind is that I did a clean shutdown during a parity check without first cancelling the parity check. I'm not sure how a clean shutdown proceeds to stop process like a parity check in progress. Could the shutdown process timeouts be to short and not allow enough time for the parity check process to end cleanly? Should I cancel parity check first, then do a clean shutdown? Again, thank you very much for taking the time to assist me with this issue. 🙂
-
Here's the final diagnostic. Also 0 errors. Any idea what happened? tower-diagnostics-20230328-2335.zip
-
Thank you very much for your assistance in this. I appreciate it. I ran a correcting check last night, shows 0 errors. Have not shutdown or rebooted. Now running a non correcting check that completes in 10 hours from now. Regardless of the result, I will post another diag as instructed. I've very puzzled that the correcting check that finished this morning shows 0 now. I'm guessing this might be what you were expecting to happen, or are you as puzzled as I am without further analysis of the new diag after completion?
-
Thanks for the tip! Some people say they're supported others not.
-
I purchased 3 WDC_WD40EZAZ drives a few years ago. Made one of them my parity drive, and the other 2 my data drive. Two of the drive are showing around 20 thousand load cycles and the 3rd is only showing 414. The power on time for the 3 drives are about 9 months total. It's only used for plex for a few hours a week. My parity drive is showing excessive load cycles (head parking) 193 Load cycle count 0x0032 194 194 000 Old age Always Never 19907 My data drive is showing high levels also. 193Load cycle count0x0032193193000Old ageAlwaysNever23004 This data drive is showing normal levels. 193Load cycle count0x0032200200000Old ageAlwaysNever414
-
For the past month, I'm seeing thousands of errors reported when I click on the parity check button. Some history... The IO CREST Internal 5 Port Non-Raid SATA III 6GB/SJMB585 SI-PEX40139 is installed but no cables are plugged into it. ( stopped using it before 12/1/22 because I was still getting UDMA CRC errors pointing to bad cables, which were all replaced, and I never bothered removing it from the PCIE slot) I instead use the JEYI NVMe M.2 to 5 Sata Adapter, Internal 5 Port Non-RAID SATA III 6GB/s plugged into GLOTRENDS M.2 PCIe X1 Adapter that was installed before 12/1/22 and it fixed the UDMA CRC errors I was seeing with the io crest card above. I even did a complete (100%) parity check 12/23/22 and there were 0 errors. On 1/2/23, parity check had started, but I cancelled it after 4 minutes. On 1/9/23, ran another parity check for 10 hours (about 90% done), but I also cancelled it accidentally (due to shut down without knowing a parity check was running). Still 0 errors. On 2/12/23 ran a full parity check, got 2252 errors, that I did not noticed was showing in the parity check history. On 3/12/23, noticed the 2252 errors on the history (never ever had this happen before in the past years), and started a parity check again. Within 39 min, 672 errors were showing and I cancelled it. I only use the server about once or twice a week for a couple hours. So the smart power on total is about 7 months >>9Power on hours0x0012100100000Old ageAlwaysNever5159 (7m, 2d, 23h) I recently upgraded unraid from 6.9.2 to 6.10.3, and there errors might have started happening after? If there's some log that has that date of upgrade, it would be good to know if there's any correlation. Yes, I know correlation is not causation, lol. I have attached tower diagnostics. Questions: 1. Does running further parity checks with the write corrections to parity, cause my currently stored data files to corrupt more or is this only affecting parity data stored for recovery? I.E. should I not do this until a cause is found? 2. Are the errors happening on the actual drives, or is something else failing? 3. Should I not be adding anymore files to these hard drives? 3. Suggestion for troubleshooting this? tower-diagnostics-20230326-1515.zip
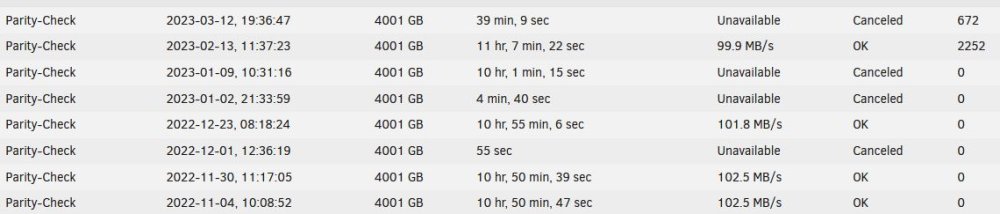

-
I'm only using the card with unraid. I did not test this card with any microsoft operating system. Maybe ask someone in a microsoft forum?
-
I combined this https://www.amazon.com/dp/B09N8MCDTZ?psc=1&ref=ppx_yo2ov_dt_b_product_details with this https://www.amazon.com/dp/B09VGTMX7W I didn't think this would work at all, but so far it's working (past hour). UPDATE: This has worked flawlessly and no more UDMA CRC error counts. Going to toss this IO CREST Internal 5 Port Non-Raid SATA III in the trash which was causing my problems.

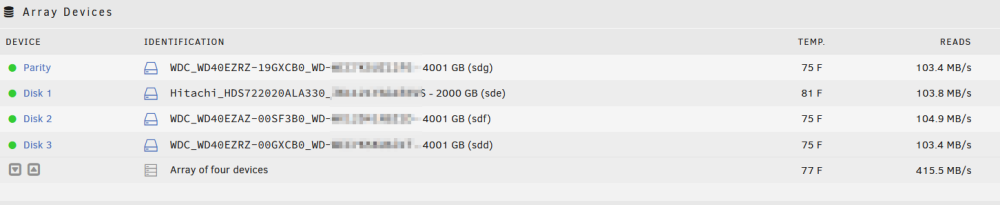


-
According to an article on the unraid forum, it's configured correctly. Do you think I should change it in some other way? "There are two tweaks to be made in order to move your transcoding into RAM. One is to the Docker Container you are running and the other is a setting from within the Plex web client itself. Step 1: Changing your Plex Container Properties From within the webGui, click on "Docker" and click on the name of the PlexMediaServer container. From here, add a new volume mapping: /transcode to /tmp Click "Apply" and the container will be started with the new mapping. Step 2: Changing the Plex Media Server to use the new transcode directory Connect to the Plex web interface from a browser (e.g. http://tower:32400/web). From there, click the wrench in the top right corner of the interface to get to settings. Now click the "Server" tab at the top of this page. On the left, you should see a setting called "Transcoder." Clicking on that and then clicking the "Show Advanced" button will reveal the magical setting that let's you redirect the transcoding directory. Type "/transcode" in there and click apply and you're all set. You can tweak some of the other settings if desired to see if that improves your media streaming experience."
-
I was not watching plex at the time this happened. I know it still runs in the background. FYI Did you see any errors related to every single drive including unraid usb disappearing? Would the system do this if the USB was going bad and disappeared from the system or would it behave completely differently if that were the case? Still on pass 1/4 for memtest. 30 minutes in and no errors... I also noticed I was getting a few errors on the parity drive related to bad cable. I switched out all the sata cables with new cables from https://www.amazon.com/gp/product/B01IBA335Y/ last week. With one of the admin's help, I had an SSD disappear and reappear and it was corrupt. Got that added back in to the cache pool as a raid 1. So far (besides the data loss I had from a partition getting corrupted on my rust spinner), it looked like it was stable. Do you think I need to do the full 4/4 passes of memtest or by now we should have seen something, before I reboot with my unraid usb? BTW, thanks for the lightning fast response!
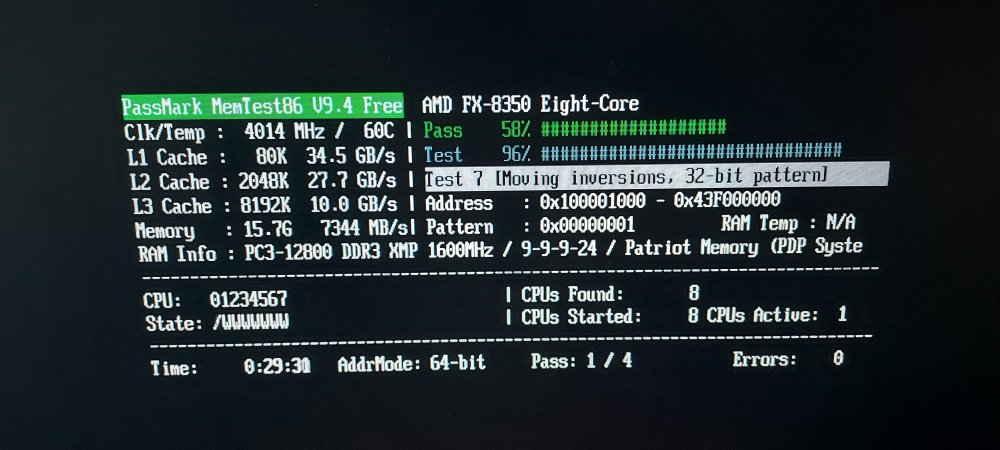
-
Perfect timing...didn't think it created one because of the error...but it did on the flash drive. Thanks Squid. tower-diagnostics-20220419-1407.zip
-
Downloaded memtest86 and running it off of a usb slot... So far no memory errors on pass 1/4. Will post a pic of the finished test. Just don't understand why I can't catch a break. LOL Sorry admins for being such a pain in the butt. I know I've had 3 different issues in the past two weeks. On the positive side, I think it ran fine for over a year without issues. (using it about 16 hours a week)
-
Everything was going fine except that all of a sudden, my drives all disappeared from the array. 4 of the rust spinners are connected to the add-on card (see signature) 2 of the SSD's connected to MB. Watched a movie from plex yesterday and didn't have any issues. Copied more stuff to the drive and right after the copy job...I get the screen below. 1st screen...everything is gone including the unraid thumbdrive. Then a few seconds later, I see the drives come back, but they are all unassigned. Then they all disappear again, and then again show up as unassigned. So I go into the diagnostics to make a diagnostic log file for you guys and I get an error trying to do that. This week I replacement my 16GB of ram which weren't working with the Patriot Viper memory sent to me by patriot as part of a lifetime warranty exchange. Yup, I bought the ram in 2008 and they sent me brand new sticks to replace them under warranty.
-
Now that actually explains it and makes sense. You are absolutely correct. I did attempt a repair of the drive (see above diagnostics) first. I wrongly assumed that formatting is preparing the drive to be made usable after an unmountable condition. I'll know better for next time, but still will consult with admins here to make sure I'm doing the steps correctly. Thank you explaining what happened. 🙂 Quick question to clarify. 1. How can you tell if the disk with the partition damage is being emulated, I know the disk could have had 50-150gb of stuff on it but the files I save there gets also saved to another disk so now way to know what was lost. I don't think I saw the folder icon next to the disk to check. 2. Is it possible that if the partition is damaged that the disk is not being emulated? 3. If the drive was being emulated, how could you copy just the files from the bad drive to a USB drive? 4. After shutting down the array, then removing the bad drive, then you restart array, is the drive still being emulated?
-
I unassigned the disk from array, reassigned it, it said it needed to be formatted, formatted it, then it started rebuilding, but it rebuild a blank disk instead of my 1TB of stuff. ;-( I think I screwed up or something...maybe I needed to move the disk out of the array and format it there. Not sure. Would like to know your opinion for next time on what I might have done wrong.
-
Thanks for the tip! I tried to use gparted, and told it to repair but it seemed like it froze. Then i walked away for 2 hours, came back, the monitor was on sleep mode. No moving of mouse or keyboard woke up gparted. So I went ahead with the recovery procedure but I messed up. Lost about a TB of stuff because I didn't pay attention.
-
What would cause a partition problem? Would the rebuild take the same amount of time as a parity check? (all the drives are shingled variety) Are there issues with doing a rebuild on shingled drives?
-Reddit.thumb.png.bd61cce15378879038978fc5fc1e2daf.png)













