




Keichi
Members
-
Joined
-
Last visited
Everything posted by Keichi
-
Thanks! But, this is for Homepage (https://github.com/gethomepage/homepage) which uses Glances integration (https://github.com/nicolargo/glances). I will ask directly on Glances' Github for more information. I just wanted to understand better the issue and from you gave me, something is possible : root@Yggdrasil:~# zfs get -Hp -o value available,used /mnt/cache 966035955456 963024068864 Values seem correct to me. Thanks again JorgeB! K.
-
Ok, i understand. So it is impossible to report the full size of a ZFS cache pool, with the tool i use. Thanks for the help, and as always, you clear answer. K.
-
Hello JorgeB, Indeed, it is by dataset. But why the main one (cache) did not report the full size of the pool array ? It seems to only report one drive of the three. That is more that i did not understand. Maybe i could have done better configuring it ? Thanks, K.
-
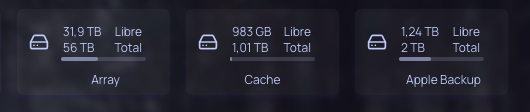
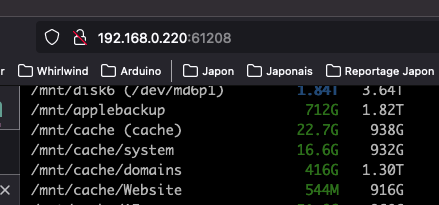
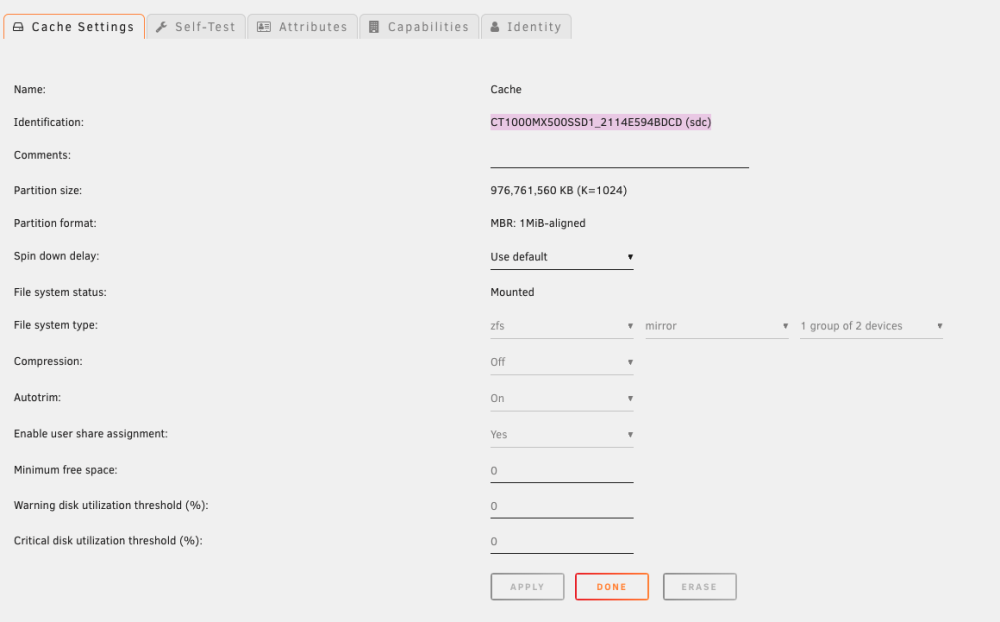
Hello, On my unraid server, i have this cache pool : It is 3x 1TB drives, with one mirror, for a total of 1.9 Tb useable capacity. On the unraid console, when i do : df -h I have this output : root@Yggdrasil:~# df -h Filesystem Size Used Avail Use% Mounted on rootfs 24G 1.6G 22G 7% / tmpfs 32M 2.2M 30M 7% /run /dev/sda1 58G 2.5G 55G 5% /boot overlay 24G 1.6G 22G 7% /lib overlay 24G 1.6G 22G 7% /usr devtmpfs 8.0M 0 8.0M 0% /dev tmpfs 24G 0 24G 0% /dev/shm tmpfs 128M 1.5M 127M 2% /var/log tmpfs 1.0M 0 1.0M 0% /mnt/disks tmpfs 1.0M 0 1.0M 0% /mnt/remotes tmpfs 1.0M 0 1.0M 0% /mnt/addons tmpfs 1.0M 0 1.0M 0% /mnt/rootshare (array disks here) cache 939G 23G 916G 3% /mnt/cache cache/system 933G 17G 916G 2% /mnt/cache/system cache/domains 1.4T 417G 916G 32% /mnt/cache/domains cache/appdata 916G 2.3M 916G 1% /mnt/cache/appdata cache/appdata/mosquitto 916G 256K 916G 1% /mnt/cache/appdata/mosquitto cache/appdata/grafana 916G 1.3M 916G 1% /mnt/cache/appdata/grafana cache/appdata/homeassistant 916G 93M 916G 1% /mnt/cache/appdata/homeassistant cache/appdata/mysql 916G 119M 916G 1% /mnt/cache/appdata/mysql cache/appdata/nginx 916G 1.0M 916G 1% /mnt/cache/appdata/nginx (etc for others containers) The "cache" is reported to be 939GB with only 23Gb used. I dont really understand this value. Is it because of ZFS ? I use Glances (with Homepage), and i can't show the correct size of the cache pool : It seems to be reported as the df command line. Really not a big deal, but maybe i can use this to learn something more. Thanks all, K.

-
Hello, I faced the same issue. I added /mnt/user to the in Glances, but i am unable to see it inside Glances. Did anyone figure it out ? Thanks
-
Thanks mgutt, i will read that !
-
Hello, For some folder, i have lines like cd..t...... StableDiffusion/Models/ cd..t...... StableDiffusion/Models/codeformer/ cd..t...... StableDiffusion/Models/controlnet/ cd..t...... StableDiffusion/Models/embeddings/ Is it possible to know what it means ? I can't find. Thanks!
-
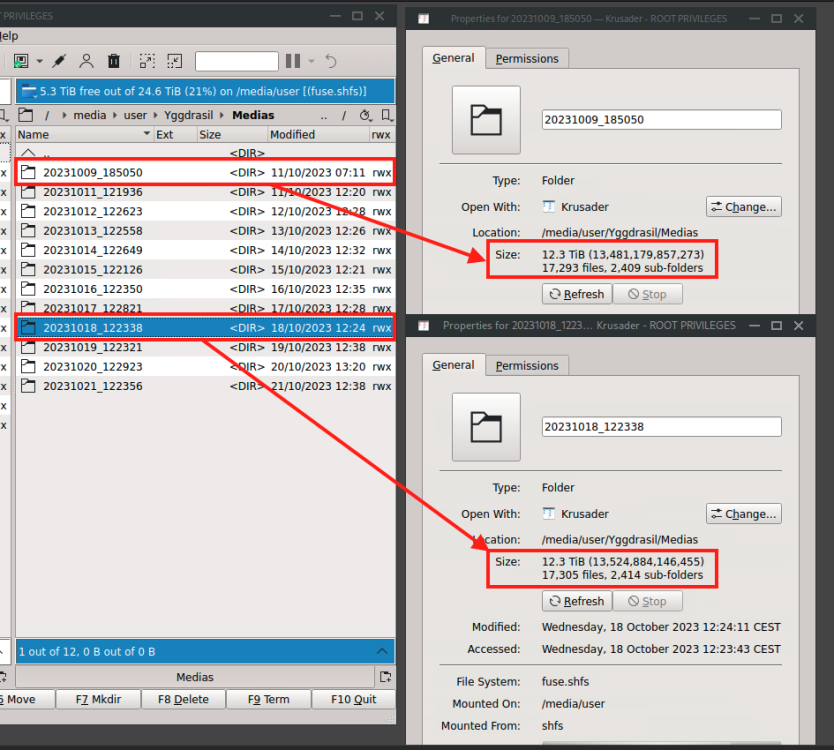
I configure the script like that : backup_jobs=( # source # destination (...) "[email protected]:/mnt/user/Medias" "/mnt/user/Yggdrasil/Medias" (...) ) In File Explorer (Krusader here), it looks like : Every folder seems to have the same size, but the script do symlink, so if you check that, you can see it is incremental : root@Helheim:~# du -d1 -h /mnt/user/Yggdrasil/Medias | sort -k2 13T /mnt/user/Yggdrasil/Medias 13T /mnt/user/Yggdrasil/Medias/20231009_185050 18G /mnt/user/Yggdrasil/Medias/20231011_121936 2.4G /mnt/user/Yggdrasil/Medias/20231012_122623 1.1G /mnt/user/Yggdrasil/Medias/20231013_122558 12G /mnt/user/Yggdrasil/Medias/20231014_122649 1.7M /mnt/user/Yggdrasil/Medias/20231015_122126 18G /mnt/user/Yggdrasil/Medias/20231016_122350 1.7M /mnt/user/Yggdrasil/Medias/20231017_122821 1.7M /mnt/user/Yggdrasil/Medias/20231018_122338 25G /mnt/user/Yggdrasil/Medias/20231019_122321 115G /mnt/user/Yggdrasil/Medias/20231020_122923 19G /mnt/user/Yggdrasil/Medias/20231021_122356 Just delete the old folder, and if the files were only present in that one, it will be deleted. K.
-
Hello, I faced this situation a few weeks ago. I can't find the email error, but the short answer is : no. You will receive a notification saying "can't write on destination, disk is full". The script is pretty dumb (probably even for keeping backups, based only on date, not on unicity of file), but still, i love it and use it every day K.
-
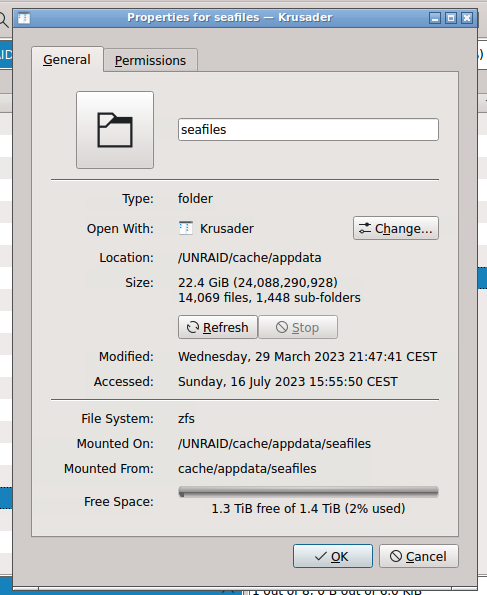
Hello, I use your Seafile docker for four months : I love it. Thanks ! Right now, i use "Backup/Restore Appdata" to make a backup of the container, which require to stop Seafile. As i am the only user and store small amount of data, it took less than 10min, which i do overnight : I think it is time to move forward. I would like to store more data, and also open it to my family, mainly to store photos/videos of my nephews, as no one in the family really understand the word "MAKE BACKUPS" or "A file in one place is a dead file". So, the total amount of data will grow, and i think stopping the container and make an archive of 1 Tb+ won't be a right solution. What is recommandation ? To give you some context : - appdata (and seafile container) is on a zfs pool : - I kept my Appdata backup on the array inside /mnt/disk5/Backup/UNRAID/appdata - Every day, a second UNRAID server is turn on and use this script to backup the main server : On the backup server, inside a array, i have a zfs disk waiting for some snapshots : I think i can manage something with that, but i don't know if zfs snapshot or rsync is a good solution, as Seafile data can be updated at any time. Thanks you for your time, and for the container ! K.





-
Hello again. Ok, i see and i am convinced, so i installed rsync-server and follow your support thread. From the main server : root@Yggdrasil:~# rsync --dry-run --itemize-changes --archive -e 'ssh -p 5533' root@Yggdrasil:/mnt/user/system/ /tmp .d..tpog... ./ cd+++++++++ docker/ >f+++++++++ docker/docker.img cd+++++++++ libvirt/ >f+++++++++ libvirt/libvirt.img From the backup server : root@Helheim:~# rsync --dry-run --itemize-changes --archive -e 'ssh -p 5533' [email protected]:/mnt/user/system/ /tmp .d..tpog... ./ cd+++++++++ docker/ >f+++++++++ docker/docker.img cd+++++++++ libvirt/ >f+++++++++ libvirt/libvirt.img And if i test : root@Helheim:~# ssh -p 5533 [email protected] Welcome to Alpine! The Alpine Wiki contains a large amount of how-to guides and general information about administrating Alpine systems. See <http://wiki.alpinelinux.org/>. You can setup the system with the command: setup-alpine You may change this message by editing /etc/motd. I guess it is working. Back to the script : # user-defined rsync command # alias rsync='sshpass -p "mypassword" rsync -e "ssh -o StrictHostKeyChecking=no"' # user-defined ssh command # alias ssh='sshpass -p "mypassword" ssh -o "StrictHostKeyChecking no"' My guess is that i need to edit these lines. But right now, ssh connection did not user any specific port, so it will "ssh normally" in the server, right ? How do i add the port, in order to user the read-only path ? I think it is : # user-defined rsync command alias rsync='rsync -e "ssh -p 5533 -o StrictHostKeyChecking=no"' # user-defined ssh command alias ssh='ssh -p 5533 -o StrictHostKeyChecking=no' Thanks K.
-
Hello, I added the script on the backup server with : # ##################################### # Settings # ##################################### # backup source to destination backup_jobs=( # source # destination "[email protected]:/mnt/user/Public" "/mnt/user/Yggdrasil/Public" ) (...) # user-defined rsync command alias rsync='sshpass -p "mystrongpassword" rsync -e "ssh -o StrictHostKeyChecking=no"' # user-defined ssh command alias ssh='sshpass -p "mystrongpassword" ssh -o "StrictHostKeyChecking no"' And it seems to work : root@Helheim:/boot/extra# du -d1 -h /mnt/disk3/Yggdrasil/Public | sort -k2 1.2M /mnt/disk3/Yggdrasil/Public 1.2M /mnt/disk3/Yggdrasil/Public/20230811_194104 4.0K /mnt/disk3/Yggdrasil/Public/20230811_194204 4.0K /mnt/disk3/Yggdrasil/Public/20230811_194225 Thank you for the quick answer ! K.
-
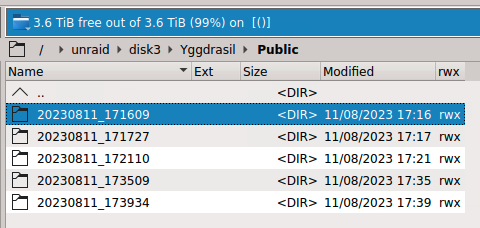
Hello, I made some test with the folder Public but hardlink seems broken : root@Helheim:/mnt/disk3/Yggdrasil/Public/20230811_171609# ls 20230811_171609.log* log-cut.txt* log.txt* root@Helheim:/mnt/disk3/Yggdrasil/Public/20230811_174553# ls 20230811_174553.log* log-cut.txt* log.txt* root@Helheim:~# du -d1 -h /mnt/disk3/Yggdrasil/Public | sort -k2 6.9M /mnt/disk3/Yggdrasil/Public 1.2M /mnt/disk3/Yggdrasil/Public/20230811_171609 (...) 1.2M /mnt/disk3/Yggdrasil/Public/20230811_174553 I use Unassigned Devices to mount a SMB share (which is another local UNRAID server) : Then, i run the script with : # backup source to destination backup_jobs=( # source # destination "/mnt/user/Public" "/mnt/remotes/HELHEIM_Yggdrasil/Public" ) The destination folder is "disk3" formatted as BTRFS : Here is the log when i run the script : Script location: /tmp/user.scripts/tmpScripts/00 - Backup Yggdrasil to Helheim/script Note that closing this window will abort the execution of this script # ##################################### last_backup: '20230811_173934/' Create incremental backup from /mnt/user/Public to /mnt/remotes/HELHEIM_Yggdrasil/Public/20230811_174553 by using last backup /mnt/remotes/HELHEIM_Yggdrasil/Public/20230811_173934/ created directory /mnt/remotes/HELHEIM_Yggdrasil/Public/.20230811_174553 cd..t...... ./ cf...p..... .DS_Store cf...po.... log-cut.txt cf...pog... log.txt Number of files: 5 (reg: 3, dir: 2) Number of created files: 0 Number of deleted files: 0 Number of regular files transferred: 0 Total file size: 1.19M bytes Total transferred file size: 0 bytes Literal data: 0 bytes Matched data: 0 bytes File list size: 0 File list generation time: 0.001 seconds File list transfer time: 0.000 seconds Total bytes sent: 183 Total bytes received: 113 sent 183 bytes received 113 bytes 197.33 bytes/sec total size is 1.19M speedup is 4,017.89 File count of rsync is 5 Make backup visible ... ... through local mv renamed '/mnt/remotes/HELHEIM_Yggdrasil/Public/.20230811_174553' -> '/mnt/remotes/HELHEIM_Yggdrasil/Public/20230811_174553' # ##################################### Clean up outdated backups Keep daily backup: 20230811_174553 Keep multiple backups per day: 20230811_173934 Keep multiple backups per day: 20230811_173509 Keep multiple backups per day: 20230811_172110 Keep multiple backups per day: 20230811_171727 Keep multiple backups per day: 20230811_171609 In my case hardlink seems broken (i did not edit the content of Public) : root@Helheim:~# du -d1 -h /mnt/disk3/Yggdrasil/Public | sort -k2 6.9M /mnt/disk3/Yggdrasil/Public 1.2M /mnt/disk3/Yggdrasil/Public/20230811_171609 1.2M /mnt/disk3/Yggdrasil/Public/20230811_171727 1.2M /mnt/disk3/Yggdrasil/Public/20230811_172110 1.2M /mnt/disk3/Yggdrasil/Public/20230811_173509 1.2M /mnt/disk3/Yggdrasil/Public/20230811_173934 1.2M /mnt/disk3/Yggdrasil/Public/20230811_174553 Do you know how i can troubleshoot the situation ? Thanks, K.


-
Thanks itimpi, i will do that. This forum is great because I always found solutions here, this is the first time i did not K.
-
No answer ? Even to say "no sorry, we don't know" from UNRAID's team ? K.
-
Can i put a little up, as the issue persists ? Thanks K.
-
Hello, I'm setting up a second unraid server whose sole role is to back up my main one. I recently discovered that btrfs can do snapshots and that a plugin exists (https://forums.unraid.net/topic/114600-plugin-snapshots/). This would be perfect for my pool disks. However, my array is in xfs and is not seen by the plugin. So I came across this script that lets you make incremental rsync backups: And finally, I've switched my "appdata" disk to zfs, so I figure I can host a zfs disk on the backup server and transfer the snapshots to it. So in the end I'll have : - array xfs => incremental script rsync - btrfs pool : Snapshots plugin - zfs pool: zfs snapshots on a zfs disk. This seems a bit complicated to me, do you have any feedback on the best way to build an unraid incremental backup server? Thanks K.
-
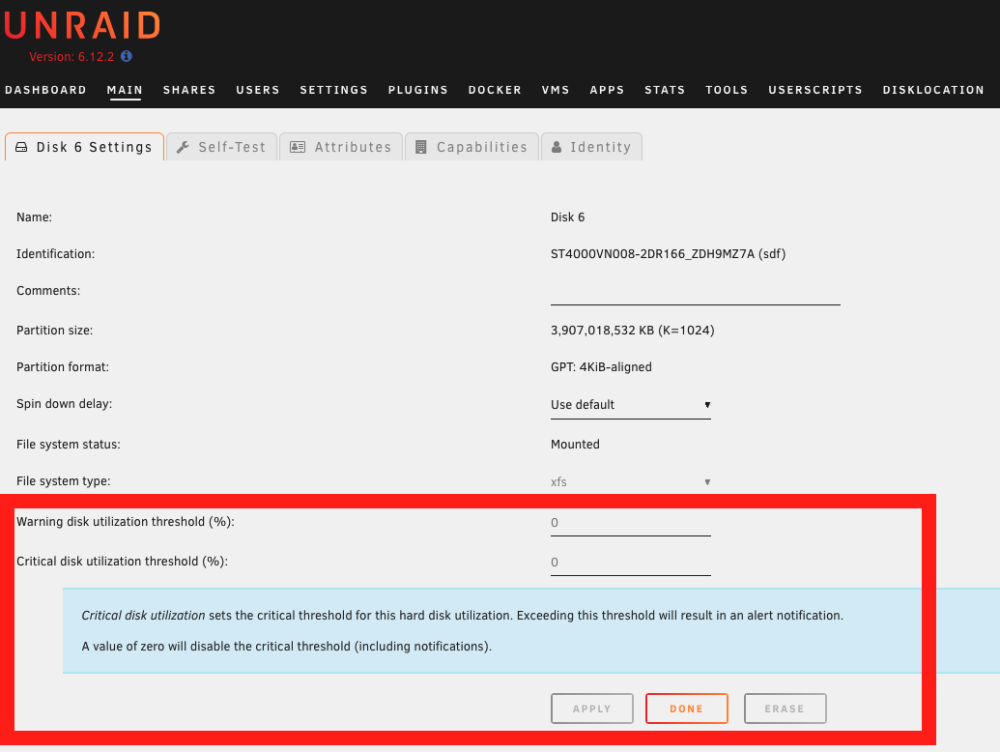
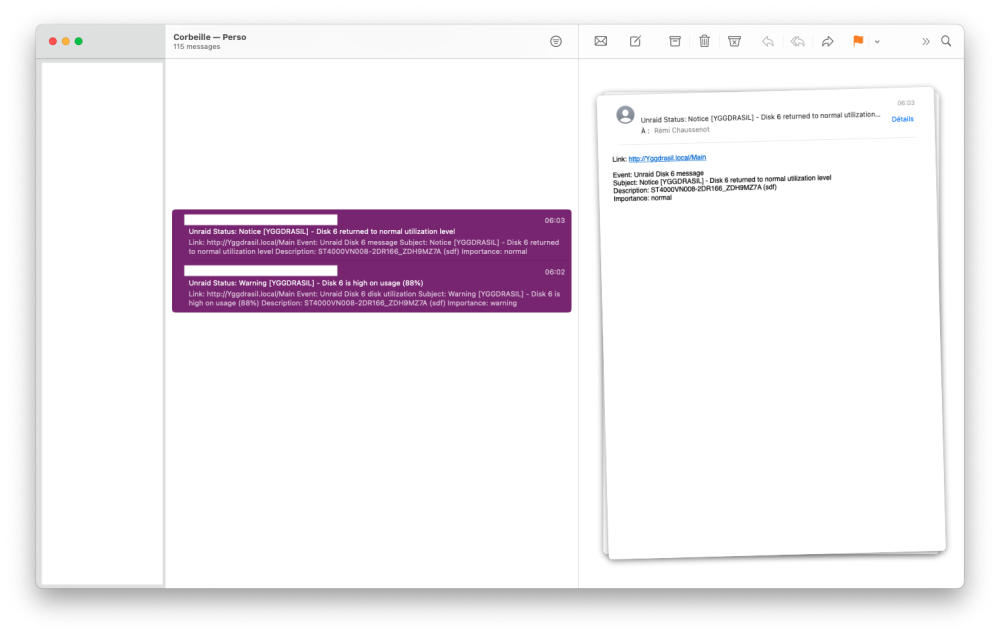
That is pretty strange, in the GUI, the value is greyed, meaning i did not change it : I changed yesterday from 90/95% to 0/0 (globally, did not touch per disk setting). Nothing changed : I still received two notifications ("Disk 6 is high on usage (88%)" and after a minute " Disk 6 returned to normal utilization level") twice a day (at 6 in the morning and 10 in the evening, french time). I can easily activate these notifications by putting a disk above 70%, even if the global setting is 90/95% or since yesterday 0/0. So it seems to me, that UNRAID completely ignore my settings and stick to 70% (default setting ?). If you tell me that in the diag, SSDs have custom limit, and from the GUI, i did not see that, maybe there is something to investigate. K.
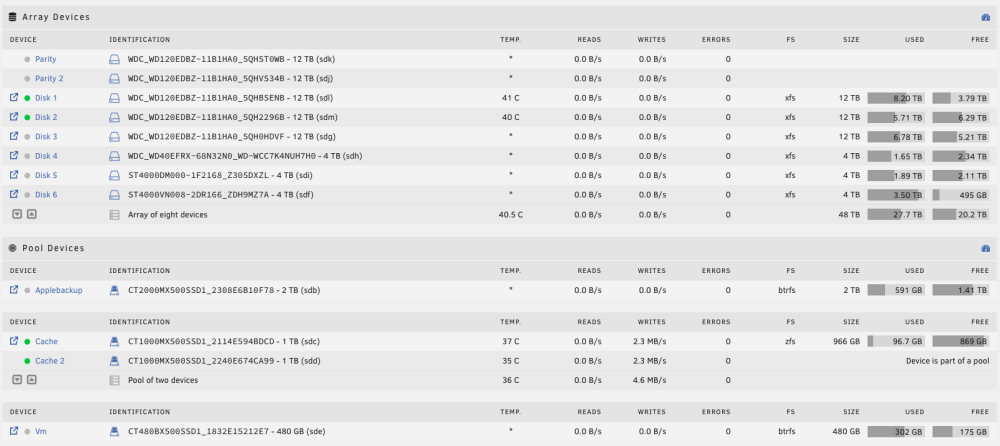
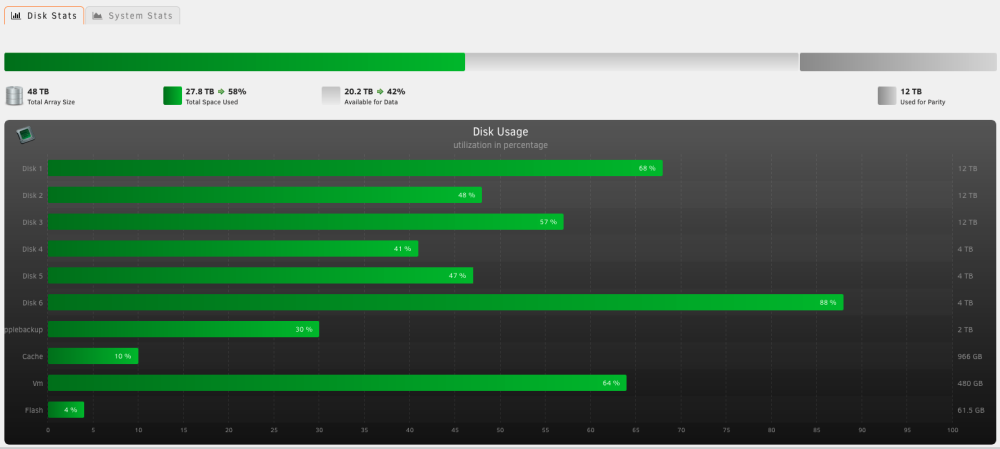
-
Indeed disk1 (HDD) was set to 90/95. I deleted the values, and now, all disks (8 HDDs array + 4 SSDs pool) are supposed to follow the general rule. Here the new diag : yggdrasil-diagnostics-20230715-1728.zip But it is still not 70% (i did a lot of tries, the notification kick at 70% no matter what config i choose). disk6 generating the notification is at 88% right now, so still under the 90/95 of disk1, and still do not follow the "do not send notification". My goal is to keep notification 90/95%, not disabled it. I just ended up trying to disable it, in order to not receive the false notification. I will have the evening notification in few hours, if i did not receive it, i will try putting back my 90/95 settings. But the main issue here is : notification kick at 70% no matter what threshold i define. Thanks -- EDIT The issue continue, still receive notifications :
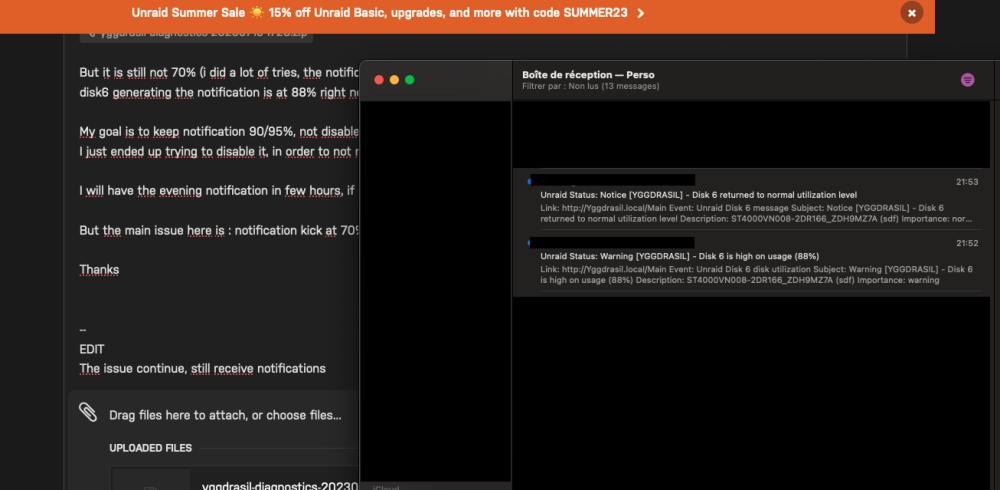
-
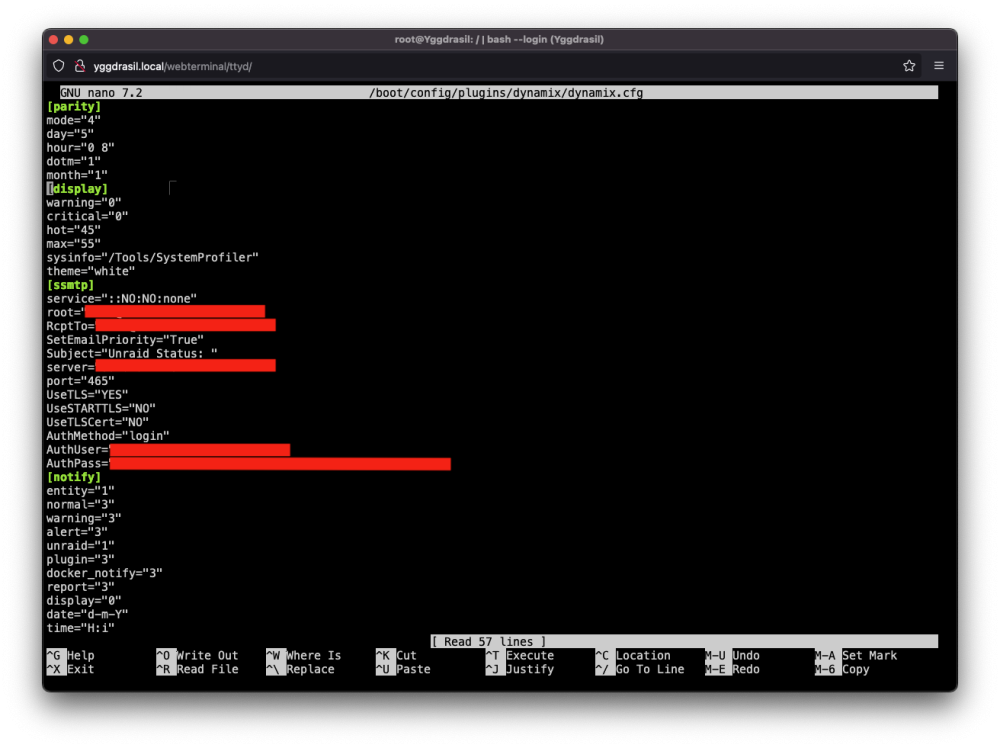
Hello, I'm currently building a second UNRAID (backup) server and I'd like to solve a "bug" I have with the current one. If the disk usage exceeds 70%, I receive an email, then, the next minute, a second email saying that in fact no, the limit has not been exceeded. I know this thread exists: But obviously, the last message was from me, more than a year ago, and the situation hasn't improved with UNRAID v6.12 In Setting / Disk Settings, i have disable notification : For the disk concerned, also : I've also checked the /boot/config/plugins/dynamix/dynamix.cfg file: However, I still receive two e-mails, twice a day, informing me that the limit has been exceeded : I've also tried setting 90% and 95%, but still get an e-mail as soon as it exceeds 70%. Would it be possible for someone to help me investigate the problem? Here the diagnostic : yggdrasil-diagnostics-20230715-1515.zip Thank you very much, K.
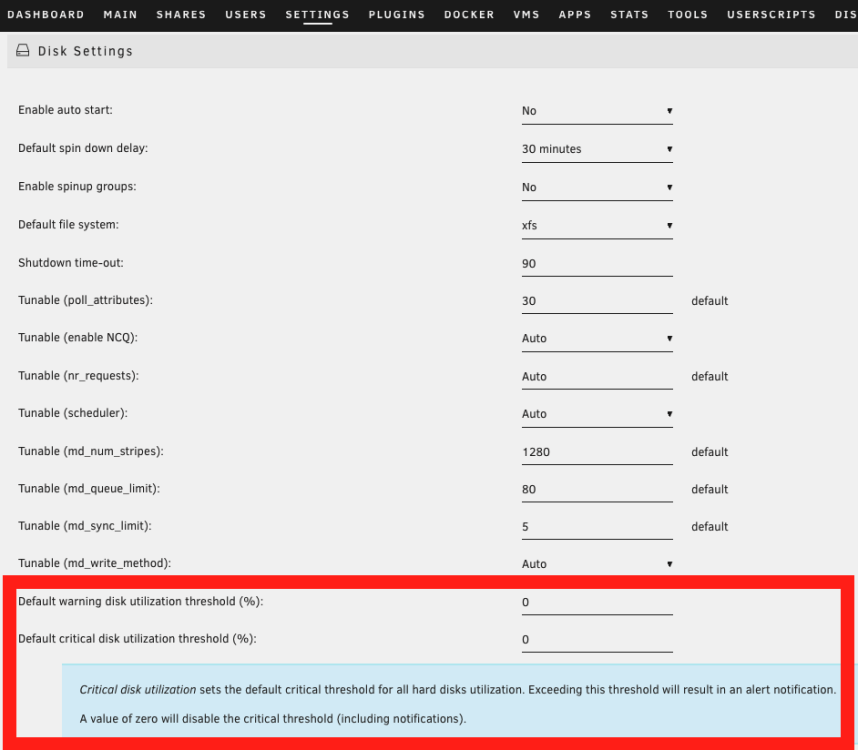
-
I had the same issue, and it was it too, thanks!
-
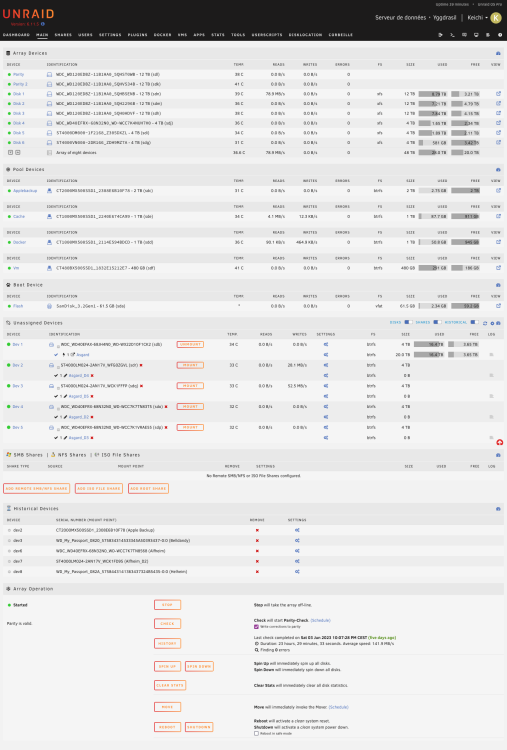
Good evening JorgeB, Thank you very much, that was indeed the problem! I've made the necessary changes, and everything works perfectly. Thanks again for your time, I'd never have found it! K.
-
Hello JorgeB, Sorry to disturb you again. On last resort, i ordered https://www.amazon.fr/dp/B099ZJ8V7W It is a ASM 1064, but still have the same issue... Do you have any advice left for me ? Thanks K. yggdrasil-diagnostics-20230608-1904.zip
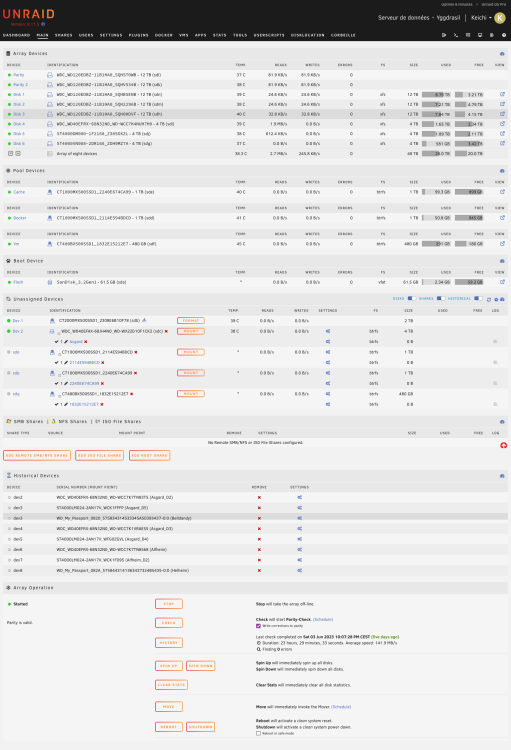
-
Hello all, Thanks for the replies. Today, i try, same setup but after BIOS update ("test1") : same issue. After BIOS update, but with IOCrest card ("test2") : same issue. So... i think i should give up. By any chance, JorgeB, do you know some add-on controller with PCIe 1x ? I only see 4x, and there is no more 4x on my motherboard. K. yggdrasil-diagnostics-20230606-2009-test1.zip yggdrasil-diagnostics-20230606-2021 - test2.zip
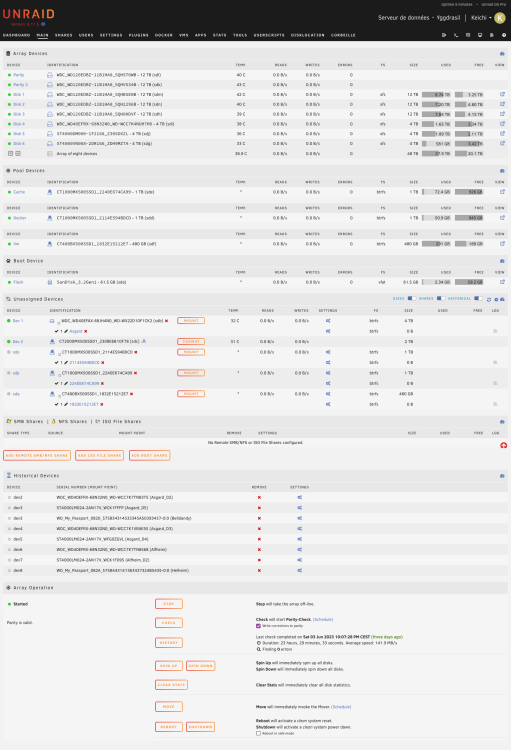
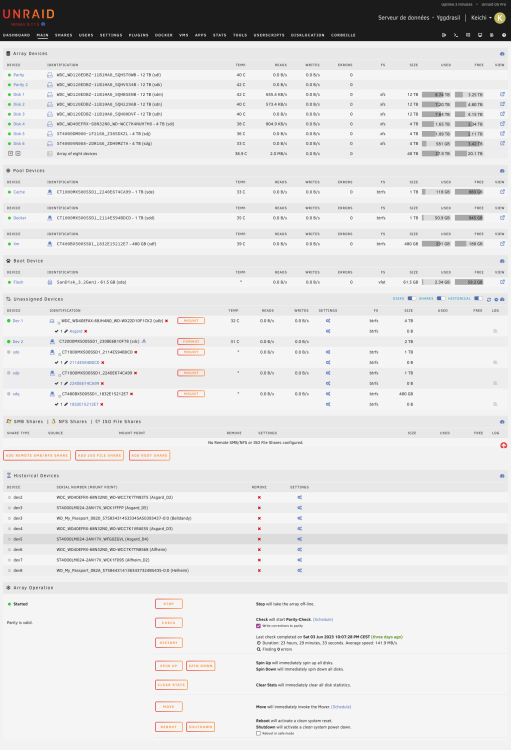
-
Hello, Thanks for the reply. This controller seems to be the one from AMD, so the 6 SATA ports on the motherboard. Did you know what can i do to solve the issue ? Thanks




























