




RadOD
Members
-
Joined
-
Last visited
-
https://forums.unraid.net/topic/181758-disabled-drives-during-unbalanced-operation/#comment-1494887 https://forums.unraid.net/topic/181785-parity-drive-disabled-but-extended-self-test-is-ok/#comment-1494949 https://forums.unraid.net/topic/181601-disk-disabled-contents-emulated/#comment-1494245 https://forums.unraid.net/topic/181461-disabled-contents-emulated-and-new-parity-drive/#comment-1493551 Seems to be a commmon problem... Also seems unlikely two drives would fail simultaneously, but I just rebuilt the entire system othr than the drives because of this error. This showed up after rebooting from th GUI while unbalance was running.
-
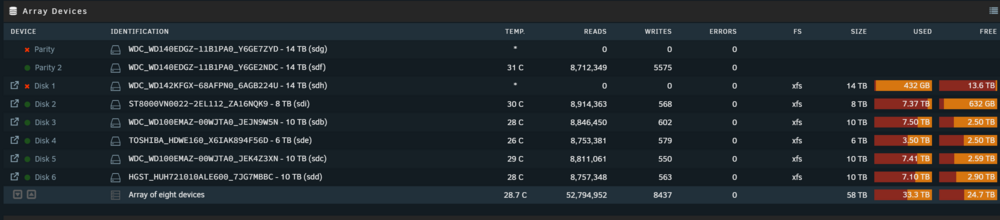
The two drives are present in the BIOS and show up in the SMART testing in th diagnostics. Disk1 appears to be present under /mnt but perhaps this is just emulated? How do I get Unraid to enable drives? homenas-diagnostics-20241210-0910.zip
-
Yes, nearly empty. I recently replaced Disk1. Unbalanced was running to copy files back onto Disk1 and I think a couple GB (out of 4-5TB) had been moved.
-
Started array and ran diagnostics.... homenas-diagnostics-20240402-1751.zip
-
One of two parity drives and one array drive say that they are disabled after accidental reboot, forgetting that Unbalanced was running. It was 'gathering' files to disk1 when the restart occurred. Both drives were installed and working fine until the restart. I can run a SMART test on both without error. How do I get them re-enabled? homenas-diagnostics-20240402-1325.zip
-
The server BIOS still knows to boot to the USB drive. Before starting, I tried backing up everything. The bzfirmware file kept giving errors when trying to read the file. Multiple attempts to run chkdsk however did not find any errors but I suspect the USB drive is going bad. I copied all the bz* files over - the 6.12 bz files would not boot but the 6.11 files worked and I got things started up. Before attempting to backup the flash drive from within the GUI, I updated the OS to I think 6.12.6 thinking that was a good idea. Later I came back to do the backup and there was an upgrade to 6.12.8 or something. After running that the USB drive was no longer detected even after multiple reboots with drive drive in every port. Is this what I want to do next: https://docs.unraid.net/unraid-os/manual/changing-the-flash-device/ ?
-
My Unraid server has been in storage for over a year. Now I get "This is not a bootable disk." when booting to the original USB drive. It boots if I insert another USB drive on which I had just installed a new clean copy of Unraid. How do I repair the original USB drive? Or can I copy my key and config to the new USB? The new USB has the current version of Unraid -- is that going to cause a problem with the Unraid version? I don't know what version I was running, but obviously it is not current.
-
I have not used my Unraid server for over a year due to illness and it has endured a couple moves. I am trying to get it up and running again but I cannot make a network connection to either the MB NIC or PCIE card NIC (Intel x540). I deleted the network.cfg and rebooted but nothing happens - no /config/network.cfg file is autogenerated. Is there a way to get it to create the file? Is there a log file somewhere that will tell me if there is some further system corruption causing the problem? Is there a way to repair or create a new USB drive without loss of data?
-
Rarely something causes the Unraid GUI to freeze up and the only way to fix (clean shutdown and reboot) is from the console. It is kinda important when I need it but rare enough that I don't want to hook up its own monitor and keyboard. Conveniently I have a workstation close by so I have set up a cheap HDMI switch. The console displays correctly for a while but eventually goes black and the monitor gives a "1920x1080 resolution is recommended" notification. This sounds like the HDMI switch is screwing up the EDID somehow. Is there a way to add a boot time config setting or run a script to manually override the resolution? Is there an xranr command in Unraid somewhere? I don't see anything I recognize in the nerd tools and dev pack plug ins.
-
I get this from a 2 port NIC that tries to swap MAC addresses between port 1 and 2. Check of the MAC is the same except for the last octal. I think it is safe to ignore but I'm looking for a way to get it to stop clogging up my logs.
-
I plan to replace one at a time, rebuilding the first before replacing the second. I just want to be certain that this intermediate step is not going to result in something like the 1st new larger disk getting a smaller partition to match the older drive, and then after I add the second larger parity drive which matches the first, and in the end I have two larger drive not being fully used. Or does unraid do all this automatically?
-
After a kernel panic and crash which I suspect was related somehow to assigning custom IP addresses on BR0 similar what is described here... Many dockers have nothing under the "port mappings" column even though they used to. I cannot access any docker at all via http://IP:port even those that still list the IP:port mappings. I am left with two 'versons' of BR: br-9c2cde536e88 and br-03ece3ee359d that I didn't create and cannot delete. At this point, I am over my head and totally confused. Is there an easy way to wipe all the docker network setting and just start over from scratch?
-
Can anyone tell me where to start looking for a "Error when trying to connect (Error occurred in the document service: Error while downloading the document file to be converted.) (version 6.3.1.32)" when I try to add the hostname for the document server to nextcloud? Searching the internets, I have found some recommended fixes such as changing the following config files: Onlyoffice: default.json -> “rejectUnauthorized” to false. local.json -> “header”: “AuthorizationJwt” from “header”: “Authorization” supervisorctl restart all Nexcloud: config/config.php -> ‘onlyoffice’ => array ( ‘verify_peer_off’ => true, ‘jwt_header’ => “AuthorizationJwt” ) ... but this is basically a new install and it doesn't look like default.json is meant to be edited outside of the docker. But /healthcheck/ returns true for both the IP address and when I try to connect via the external domain name so I think the container is up and running but the above fix suggests some part of the forwarding is broken and I don't know what tools might help me find it. My firewall forwards 443 to NginxProxyManager docker on Unraid. NPM has a wildcard SSL cert for the domain and is set to forward nextcloud.domain.name and docserver.domain.name to the appropriate ports for their respective unraid dockers. All 3 dockers are running on a docker proxynet (docker create network proxynet). Both nextcloud and document server are accessible on the local network via IP:port and on the internet via domain name. Both cert and key PEM's are copied to .crt files I get the following in the docker log: If I manually cut and paste https://nextcloud.domain.name/apps/onlyoffice/empty?doc=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJhY3Rpb24iOiJlbXB0eSJ9.la3XO9qn6tmmWaNhPtzJXk2kMb0u_-gh6ZnwW-iFnY0 it downloads a 7kb file new.docx that looks blank to me. As far as I can tell, everything seems to be working except the file won't transfer from inside the nextcloud docker.
-
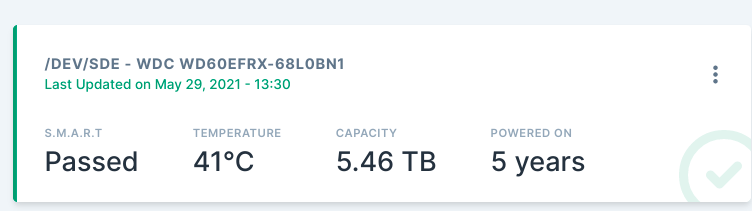
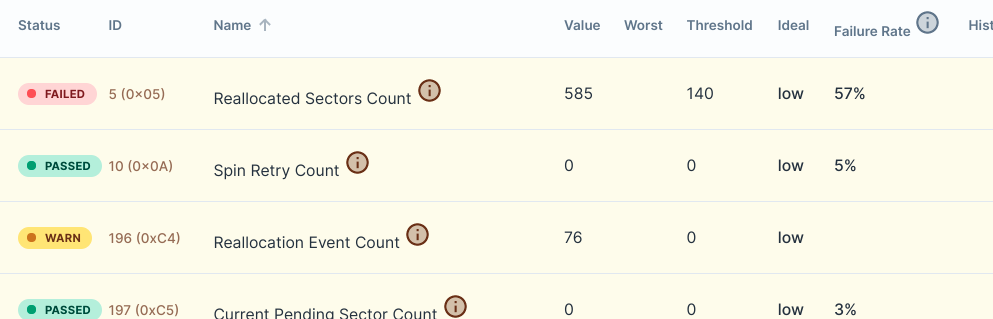
The main page shows everything to look good: everything is green and says passed. I have to actually open each one to see any signs of problems -- such as a failed Reallocated Sectors Count. Is that expected behavior? Seems like those failures and warnings should be out in front.
-
Mover has been running for hours but I only see a couple GB actually moved. iotop -o Total DISK READ : 0.00 B/s | Total DISK WRITE : 177.10 K/s Actual DISK READ: 0.00 B/s | Actual DISK WRITE: 0.00 B/s TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND 30785 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.02 % [kworker/u8:5-events_power_efficient] 15906 be/4 root 0.00 B/s 3.85 K/s 0.00 % 0.00 % shfs /mnt/user -disks 31 -o noatime,allow_other -o remember=0 17443 be/4 root 0.00 B/s 34.65 K/s 0.00 % 0.00 % shfs /mnt/user -disks 31 -o noatime,allow_other -o remember=0 31806 be/4 root 0.00 B/s 7.70 K/s 0.00 % 0.00 % shfs /mnt/user -disks 31 -o noatime,allow_other -o remember=0 22041 be/4 root 0.00 B/s 11.55 K/s 0.00 % 0.00 % shfs /mnt/user -disks 31 -o noatime,allow_other -o remember=0 17696 be/4 root 0.00 B/s 7.70 K/s 0.00 % 0.00 % shfs /mnt/user -disks 31 -o noatime,allow_other -o remember=0 17796 be/4 root 0.00 B/s 53.90 K/s 0.00 % 0.00 % shfs /mnt/user -disks 31 -o noatime,allow_other -o remember=0 16781 be/4 root 0.00 B/s 11.55 K/s 0.00 % 0.00 % shfs /mnt/user -disks 31 -o noatime,allow_other -o remember=0 16782 be/4 root 0.00 B/s 7.70 K/s 0.00 % 0.00 % shfs /mnt/user -disks 31 -o noatime,allow_other -o remember=0 19995 be/4 root 0.00 B/s 15.40 K/s 0.00 % 0.00 % shfs /mnt/user -disks 31 -o noatime,allow_other -o remember=0 16836 be/4 root 0.00 B/s 23.10 K/s 0.00 % 0.00 % shfs /mnt/user -disks 31 -o noatime,allow_other -o remember=0 Docker and VM are off. Where do I look to see what mover is trying to do to figure out why it does not seem to be making progress?


