




RadOD
Members
-
Joined
-
Last visited
Everything posted by RadOD
-
https://forums.unraid.net/topic/181758-disabled-drives-during-unbalanced-operation/#comment-1494887 https://forums.unraid.net/topic/181785-parity-drive-disabled-but-extended-self-test-is-ok/#comment-1494949 https://forums.unraid.net/topic/181601-disk-disabled-contents-emulated/#comment-1494245 https://forums.unraid.net/topic/181461-disabled-contents-emulated-and-new-parity-drive/#comment-1493551 Seems to be a commmon problem... Also seems unlikely two drives would fail simultaneously, but I just rebuilt the entire system othr than the drives because of this error. This showed up after rebooting from th GUI while unbalance was running.
-
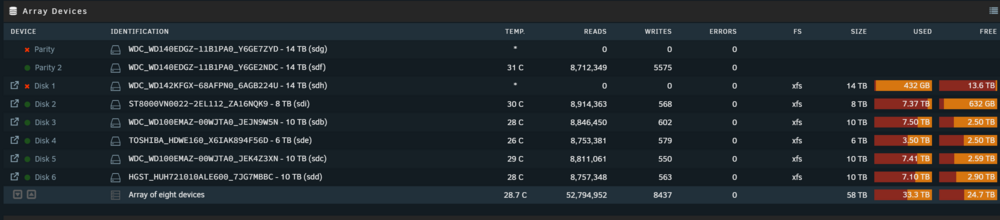
The two drives are present in the BIOS and show up in the SMART testing in th diagnostics. Disk1 appears to be present under /mnt but perhaps this is just emulated? How do I get Unraid to enable drives? homenas-diagnostics-20241210-0910.zip
-
Yes, nearly empty. I recently replaced Disk1. Unbalanced was running to copy files back onto Disk1 and I think a couple GB (out of 4-5TB) had been moved.
-
Started array and ran diagnostics.... homenas-diagnostics-20240402-1751.zip
-
One of two parity drives and one array drive say that they are disabled after accidental reboot, forgetting that Unbalanced was running. It was 'gathering' files to disk1 when the restart occurred. Both drives were installed and working fine until the restart. I can run a SMART test on both without error. How do I get them re-enabled? homenas-diagnostics-20240402-1325.zip
-
The server BIOS still knows to boot to the USB drive. Before starting, I tried backing up everything. The bzfirmware file kept giving errors when trying to read the file. Multiple attempts to run chkdsk however did not find any errors but I suspect the USB drive is going bad. I copied all the bz* files over - the 6.12 bz files would not boot but the 6.11 files worked and I got things started up. Before attempting to backup the flash drive from within the GUI, I updated the OS to I think 6.12.6 thinking that was a good idea. Later I came back to do the backup and there was an upgrade to 6.12.8 or something. After running that the USB drive was no longer detected even after multiple reboots with drive drive in every port. Is this what I want to do next: https://docs.unraid.net/unraid-os/manual/changing-the-flash-device/ ?
-
My Unraid server has been in storage for over a year. Now I get "This is not a bootable disk." when booting to the original USB drive. It boots if I insert another USB drive on which I had just installed a new clean copy of Unraid. How do I repair the original USB drive? Or can I copy my key and config to the new USB? The new USB has the current version of Unraid -- is that going to cause a problem with the Unraid version? I don't know what version I was running, but obviously it is not current.
-
I have not used my Unraid server for over a year due to illness and it has endured a couple moves. I am trying to get it up and running again but I cannot make a network connection to either the MB NIC or PCIE card NIC (Intel x540). I deleted the network.cfg and rebooted but nothing happens - no /config/network.cfg file is autogenerated. Is there a way to get it to create the file? Is there a log file somewhere that will tell me if there is some further system corruption causing the problem? Is there a way to repair or create a new USB drive without loss of data?
-
Rarely something causes the Unraid GUI to freeze up and the only way to fix (clean shutdown and reboot) is from the console. It is kinda important when I need it but rare enough that I don't want to hook up its own monitor and keyboard. Conveniently I have a workstation close by so I have set up a cheap HDMI switch. The console displays correctly for a while but eventually goes black and the monitor gives a "1920x1080 resolution is recommended" notification. This sounds like the HDMI switch is screwing up the EDID somehow. Is there a way to add a boot time config setting or run a script to manually override the resolution? Is there an xranr command in Unraid somewhere? I don't see anything I recognize in the nerd tools and dev pack plug ins.
-
I get this from a 2 port NIC that tries to swap MAC addresses between port 1 and 2. Check of the MAC is the same except for the last octal. I think it is safe to ignore but I'm looking for a way to get it to stop clogging up my logs.
-
I plan to replace one at a time, rebuilding the first before replacing the second. I just want to be certain that this intermediate step is not going to result in something like the 1st new larger disk getting a smaller partition to match the older drive, and then after I add the second larger parity drive which matches the first, and in the end I have two larger drive not being fully used. Or does unraid do all this automatically?
-
After a kernel panic and crash which I suspect was related somehow to assigning custom IP addresses on BR0 similar what is described here... Many dockers have nothing under the "port mappings" column even though they used to. I cannot access any docker at all via http://IP:port even those that still list the IP:port mappings. I am left with two 'versons' of BR: br-9c2cde536e88 and br-03ece3ee359d that I didn't create and cannot delete. At this point, I am over my head and totally confused. Is there an easy way to wipe all the docker network setting and just start over from scratch?
-
Can anyone tell me where to start looking for a "Error when trying to connect (Error occurred in the document service: Error while downloading the document file to be converted.) (version 6.3.1.32)" when I try to add the hostname for the document server to nextcloud? Searching the internets, I have found some recommended fixes such as changing the following config files: Onlyoffice: default.json -> “rejectUnauthorized” to false. local.json -> “header”: “AuthorizationJwt” from “header”: “Authorization” supervisorctl restart all Nexcloud: config/config.php -> ‘onlyoffice’ => array ( ‘verify_peer_off’ => true, ‘jwt_header’ => “AuthorizationJwt” ) ... but this is basically a new install and it doesn't look like default.json is meant to be edited outside of the docker. But /healthcheck/ returns true for both the IP address and when I try to connect via the external domain name so I think the container is up and running but the above fix suggests some part of the forwarding is broken and I don't know what tools might help me find it. My firewall forwards 443 to NginxProxyManager docker on Unraid. NPM has a wildcard SSL cert for the domain and is set to forward nextcloud.domain.name and docserver.domain.name to the appropriate ports for their respective unraid dockers. All 3 dockers are running on a docker proxynet (docker create network proxynet). Both nextcloud and document server are accessible on the local network via IP:port and on the internet via domain name. Both cert and key PEM's are copied to .crt files I get the following in the docker log: If I manually cut and paste https://nextcloud.domain.name/apps/onlyoffice/empty?doc=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJhY3Rpb24iOiJlbXB0eSJ9.la3XO9qn6tmmWaNhPtzJXk2kMb0u_-gh6ZnwW-iFnY0 it downloads a 7kb file new.docx that looks blank to me. As far as I can tell, everything seems to be working except the file won't transfer from inside the nextcloud docker.
-
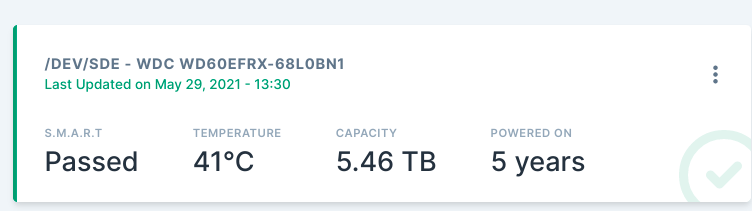
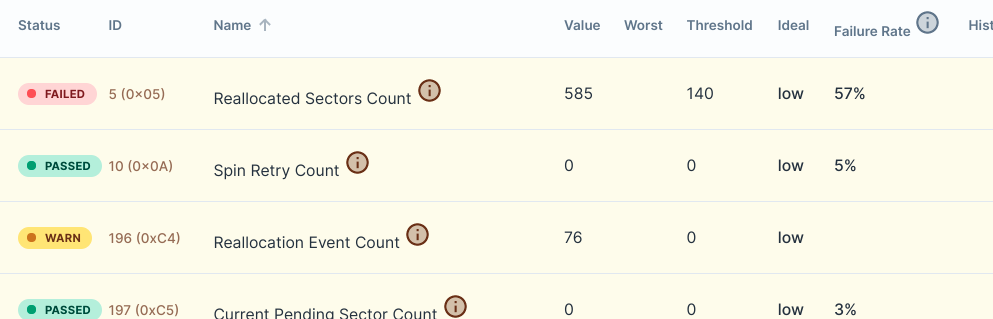
The main page shows everything to look good: everything is green and says passed. I have to actually open each one to see any signs of problems -- such as a failed Reallocated Sectors Count. Is that expected behavior? Seems like those failures and warnings should be out in front.
-
Mover has been running for hours but I only see a couple GB actually moved. iotop -o Total DISK READ : 0.00 B/s | Total DISK WRITE : 177.10 K/s Actual DISK READ: 0.00 B/s | Actual DISK WRITE: 0.00 B/s TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND 30785 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.02 % [kworker/u8:5-events_power_efficient] 15906 be/4 root 0.00 B/s 3.85 K/s 0.00 % 0.00 % shfs /mnt/user -disks 31 -o noatime,allow_other -o remember=0 17443 be/4 root 0.00 B/s 34.65 K/s 0.00 % 0.00 % shfs /mnt/user -disks 31 -o noatime,allow_other -o remember=0 31806 be/4 root 0.00 B/s 7.70 K/s 0.00 % 0.00 % shfs /mnt/user -disks 31 -o noatime,allow_other -o remember=0 22041 be/4 root 0.00 B/s 11.55 K/s 0.00 % 0.00 % shfs /mnt/user -disks 31 -o noatime,allow_other -o remember=0 17696 be/4 root 0.00 B/s 7.70 K/s 0.00 % 0.00 % shfs /mnt/user -disks 31 -o noatime,allow_other -o remember=0 17796 be/4 root 0.00 B/s 53.90 K/s 0.00 % 0.00 % shfs /mnt/user -disks 31 -o noatime,allow_other -o remember=0 16781 be/4 root 0.00 B/s 11.55 K/s 0.00 % 0.00 % shfs /mnt/user -disks 31 -o noatime,allow_other -o remember=0 16782 be/4 root 0.00 B/s 7.70 K/s 0.00 % 0.00 % shfs /mnt/user -disks 31 -o noatime,allow_other -o remember=0 19995 be/4 root 0.00 B/s 15.40 K/s 0.00 % 0.00 % shfs /mnt/user -disks 31 -o noatime,allow_other -o remember=0 16836 be/4 root 0.00 B/s 23.10 K/s 0.00 % 0.00 % shfs /mnt/user -disks 31 -o noatime,allow_other -o remember=0 Docker and VM are off. Where do I look to see what mover is trying to do to figure out why it does not seem to be making progress?
-
Is there any wait to push data from outside sources into the influxDB within the GUS container? It would be nice to be able to push from a opnsense or pfsense firewall too and have it all in the same place.
-
Agree! That is a particularly complicated sounding error for such a little thing. and it is easy to lose one of those little console windows behind everything else. Maybe an option to open console and log windows as a new tab instead?
-
I don't have an answer to your specific question, but hopefully this is helpful: I found DupeGuru's all-or-nothing results to be too unreliable and require too much user interaction. Instead, if you install the nerd pack plug in, there are two command line dupe checkers - fdupes and jdupes. Install either (reportedly jdupes is faster) and the user scripts plug in. Write a script to delete dupes and set it to run periodically. Or, a little more complicated, but you can create a script to move the dupes and create a log of what it did and you can review everything and manually delete. I can't access them right now, but I can post mine if anyone wants them.
-
A question about Zabbix-Server and Zabbix-Webinterface - but perhaps a question more about dockers in general: I installed both. Server logs looks like it is running and the DB is being used. However I can't configure anything at http://ip/zabbix as the page does not load. I assume that is the webinterface docker's job - and if I look at the logs I see: 2020/04/18 13:07:19 [emerg] 25051#25051: bind() to 0.0.0.0:80 failed (98: Address in use) nginx: [emerg] bind() to 0.0.0.0:80 failed (98: Address in use) Obviously port 80 is already in use elsewhere. The webinterface docker does not give me any port options when setting it up, but configures itself to listen on 80 and 443. This doesn't conflict with any other docker, but Unraid itself is using those and (thankfully) must keep them from the container. Here is where things get more unclear to me: Zabbix is using a subdirectory and not its own port or a subdomain. Is this where I would setup nginx to route traffic to the proper place? Or is the container network type just setup differently - as bridge? Or both: setup let's encrypt with nginx and zabbix-webinterface both on their own proxy-net?
-
"GUI address is overridden by startup options" means you set the address:port to access the syncthing docker when you create the docker. You cannot modify that in the GUI itself.
-
Thanks for this plug-in. Super helpful. Feature request: -Ability to sort by name or scheduled frequency. -Also it would be helpful to be able to tag them with user created categories. Mine are starting to get too many to keep organized.
-
Clean install into alternate config directory and syncthing still seems unable to modify index.db folder contents. I installed xamindar syncthing overtop into same config directory (syncthing not Syncthing) then installed this one again. Once db files written out by the other version, this one works fine.
-
My syncthing docker is reporting "insufficient space on disk for database (/config/index-v0.14.0.db): 1.0 % < 1 %" for any and all folders. This is an almost-new Unraid install and there is plenty of space in appdata according to Unraid's GUI. From within the docker: Filesystem 1K-blocks Used Available Use% Mounted on /dev/loop2 20971520 3231044 17510492 16% / tmpfs 65536 0 65536 0% /dev tmpfs 16491516 0 16491516 0% /sys/fs/cgroup shm 65536 0 65536 0% /dev/shm shfs 9764349900 69093472 9695256428 1% /sync /dev/loop2 20971520 3231044 17510492 16% /etc/hosts tmpfs 16491516 0 16491516 0% /proc/acpi tmpfs 16491516 0 16491516 0% /sys/firmware So my guess is this is some sort of file permission issue. But I don't know how to fix it. (Oh also - I have a nearly identical unraid server which has no such issues. As far as I can see the docker and pretty much everything are set up the same.)
-
I found a workaround - I was able to save the results quickly then it immediately froze. Restarting the container and loading the results works with none of the previous issues and a was able to mark, move and delete without any issues. As far as errors in the container's log - unless I'm mistaken, that was the container's log that I posted. And before setting the memory variable I did see lots of malloc errors there. But I see nothing in that log that helps.
-
The dupeguru docker freezes after a fairly large task: 7.5 TiB, 534,090 files, 1,298 sub-folders -- all photos. Initially the task would cause the entire Unraid system to slow to a crawl and eventually hang. Logs showed memory allocation errors. I have 32GB so I added ran it with 16GB with the --memory option. The task ran without a hitch but hangs upon trying to take action at the end. Docker log (below) does not seem to show anything useful -- mainly VNC type stuff not dupeguru itself. System logs show nothing related. At the time of freeze up just a lot of 'Monitor: No array operation currently in progress'. It takes >24h to run, so trial and error here is not a good option. Is there a log someplace within the docker I should look to find errors thrown off by the dupeguru process itself? ErrorWarningSystemArrayLogin 14/01/2020 09:28:23 Protocol version sent 3.8, using 3.8 14/01/2020 09:28:23 rfbProcessClientSecurityType: executing handler for type 1 14/01/2020 09:28:23 rfbProcessClientSecurityType: returning securityResult for client rfb version >= 3.8 14/01/2020 09:28:23 Pixel format for client 127.0.0.1: 14/01/2020 09:28:23 32 bpp, depth 24, little endian 14/01/2020 09:28:23 true colour: max r 255 g 255 b 255, shift r 16 g 8 b 0 14/01/2020 09:28:23 no translation needed 14/01/2020 09:28:23 Enabling NewFBSize protocol extension for client 127.0.0.1 14/01/2020 09:28:23 Enabling full-color cursor updates for client 127.0.0.1 14/01/2020 09:28:23 Using image quality level 6 for client 127.0.0.1 14/01/2020 09:28:23 Using JPEG subsampling 0, Q79 for client 127.0.0.1 14/01/2020 09:28:23 Using compression level 9 for client 127.0.0.1 14/01/2020 09:28:23 Enabling LastRect protocol extension for client 127.0.0.1 14/01/2020 09:28:23 rfbProcessClientNormalMessage: ignoring unsupported encoding type Enc(0xFFFFFECC) 14/01/2020 09:28:23 Using tight encoding for client 127.0.0.1 14/01/2020 09:28:24 client 1 network rate 119.5 KB/sec (30840.4 eff KB/sec) 14/01/2020 09:28:24 client 1 latency: 1.5 ms 14/01/2020 09:28:24 dt1: 0.0043, dt2: 0.1240 dt3: 0.0015 bytes: 15237 14/01/2020 09:28:24 link_rate: LR_BROADBAND - 1 ms, 119 KB/s 14/01/2020 09:28:24 client_set_net: 127.0.0.1 0.0000 14/01/2020 09:28:24 created xdamage object: 0x40002c 14/01/2020 09:28:32 created selwin: 0x40002d 14/01/2020 09:28:32 called initialize_xfixes() 14/01/2020 09:28:33 copy_tiles: allocating first_line at size 41 14/01/2020 09:28:53 increased wireframe timeouts for slow network connection. 14/01/2020 09:28:53 netrate: 119 KB/sec, latency: 1 ms 14/01/2020 09:33:24 idle keyboard: turning X autorepeat back on. 14/01/2020 10:27:30 Got connection from client 127.0.0.1 14/01/2020 10:27:30 other clients: 14/01/2020 10:27:30 127.0.0.1 14/01/2020 10:27:30 Got 'ws' WebSockets handshake 14/01/2020 10:27:30 Got protocol: binary 14/01/2020 10:27:30 - webSocketsHandshake: using binary/raw encoding 14/01/2020 10:27:30 - WebSockets client version hybi-13 14/01/2020 10:27:30 incr accepted_client=2 for 127.0.0.1:33966 sock=11 14/01/2020 10:27:30 Client Protocol Version 3.8 14/01/2020 10:27:30 Protocol version sent 3.8, using 3.8 14/01/2020 10:27:30 rfbProcessClientSecurityType: executing handler for type 1 14/01/2020 10:27:30 rfbProcessClientSecurityType: returning securityResult for client rfb version >= 3.8 14/01/2020 10:27:30 Pixel format for client 127.0.0.1: 14/01/2020 10:27:30 32 bpp, depth 24, little endian 14/01/2020 10:27:30 true colour: max r 255 g 255 b 255, shift r 16 g 8 b 0 14/01/2020 10:27:30 no translation needed 14/01/2020 10:27:30 Enabling NewFBSize protocol extension for client 127.0.0.1 14/01/2020 10:27:30 Using image quality level 6 for client 127.0.0.1 14/01/2020 10:27:30 Using JPEG subsampling 0, Q79 for client 127.0.0.1 14/01/2020 10:27:30 Using compression level 9 for client 127.0.0.1 14/01/2020 10:27:30 Enabling LastRect protocol extension for client 127.0.0.1 14/01/2020 10:27:30 rfbProcessClientNormalMessage: ignoring unsupported encoding type Enc(0xFFFFFECC) 14/01/2020 10:27:30 Using tight encoding for client 127.0.0.1 14/01/2020 10:27:30 client 2 network rate 217.9 KB/sec (38794.9 eff KB/sec) 14/01/2020 10:27:30 client 2 latency: 2.7 ms 14/01/2020 10:27:30 dt1: 0.0090, dt2: 0.0937 dt3: 0.0027 bytes: 22084 14/01/2020 10:27:30 link_rate: LR_BROADBAND - 2 ms, 119 KB/s 14/01/2020 10:27:30 client_set_net: 127.0.0.1 0.0001 14/01/2020 10:27:31 active keyboard: turning X autorepeat off. 14/01/2020 10:29:14 client_count: 1 14/01/2020 10:29:14 Client 127.0.0.1 gone 14/01/2020 10:29:14 Statistics events Transmit/ RawEquiv ( saved) 14/01/2020 10:29:14 FramebufferUpdate : 105 | 0/ 0 ( 0.0%) 14/01/2020 10:29:14 LastRect : 1 | 12/ 12 ( 0.0%) 14/01/2020 10:29:14 tight : 193 | 73124/ 4117772 ( 98.2%) 14/01/2020 10:29:14 TOTALS : 299 | 73136/ 4117784 ( 98.2%) 14/01/2020 10:29:14 Statistics events Received/ RawEquiv ( saved) 14/01/2020 10:29:14 PointerEvent : 43 | 258/ 258 ( 0.0%) 14/01/2020 10:29:14 FramebufferUpdate : 106 | 1060/ 1060 ( 0.0%) 14/01/2020 10:29:14 SetEncodings : 1 | 52/ 52 ( 0.0%) 14/01/2020 10:29:14 SetPixelFormat : 1 | 20/ 20 ( 0.0%) 14/01/2020 10:29:14 TOTALS : 151 | 1390/ 1390 ( 0.0%) 14/01/2020 10:29:53 got closure, reason 1001 14/01/2020 10:29:53 rfbProcessClientNormalMessage: read: Connection reset by peer 14/01/2020 10:29:53 client_count: 0 14/01/2020 10:29:53 Restored X server key autorepeat to: 1 14/01/2020 10:29:53 Client 127.0.0.1 gone 14/01/2020 10:29:53 Statistics events Transmit/ RawEquiv ( saved) 14/01/2020 10:29:53 ServerCutText : 1 | 8/ 8 ( 0.0%) 14/01/2020 10:29:53 FramebufferUpdate : 2738 | 0/ 0 ( 0.0%) 14/01/2020 10:29:53 copyRect : 1 | 16/ 691824 (100.0%) 14/01/2020 10:29:53 LastRect : 43 | 516/ 516 ( 0.0%) 14/01/2020 10:29:53 tight : 2997 | 1844512/ 13936412 ( 86.8%) 14/01/2020 10:29:53 RichCursor : 1 | 1374/ 1374 ( 0.0%) 14/01/2020 10:29:53 TOTALS : 5781 | 1846426/ 14630134 ( 87.4%) 14/01/2020 10:29:53 Statistics events Received/ RawEquiv ( saved) 14/01/2020 10:29:53 PointerEvent : 1687 | 10122/ 10122 ( 0.0%) 14/01/2020 10:29:53 FramebufferUpdate : 2741 | 27410/ 27410 ( 0.0%) 14/01/2020 10:29:53 SetEncodings : 1 | 56/ 56 ( 0.0%) 14/01/2020 10:29:53 SetPixelFormat : 1 | 20/ 20 ( 0.0%) 14/01/2020 10:29:53 TOTALS : 4430 | 37608/ 37608 ( 0.0%) 14/01/2020 10:29:53 destroyed xdamage object: 0x40002c 14/01/2020 18:29:20 Got connection from client 127.0.0.1 14/01/2020 18:29:20 other clients: 14/01/2020 18:29:20 Got 'ws' WebSockets handshake 14/01/2020 18:29:20 Got protocol: binary 14/01/2020 18:29:20 - webSocketsHandshake: using binary/raw encoding 14/01/2020 18:29:20 - WebSockets client version hybi-13 14/01/2020 18:29:20 Disabled X server key autorepeat. 14/01/2020 18:29:20 to force back on run: 'xset r on' (3 times) 14/01/2020 18:29:20 incr accepted_client=3 for 127.0.0.1:48316 sock=10 14/01/2020 18:29:20 Client Protocol Version 3.8 14/01/2020 18:29:20 Protocol version sent 3.8, using 3.8 14/01/2020 18:29:20 rfbProcessClientSecurityType: executing handler for type 1 14/01/2020 18:29:20 rfbProcessClientSecurityType: returning securityResult for client rfb version >= 3.8 14/01/2020 18:29:21 Pixel format for client 127.0.0.1: 14/01/2020 18:29:21 32 bpp, depth 24, little endian 14/01/2020 18:29:21 true colour: max r 255 g 255 b 255, shift r 16 g 8 b 0 14/01/2020 18:29:21 no translation needed 14/01/2020 18:29:21 Enabling NewFBSize protocol extension for client 127.0.0.1 14/01/2020 18:29:21 Enabling full-color cursor updates for client 127.0.0.1 14/01/2020 18:29:21 Using image quality level 6 for client 127.0.0.1 14/01/2020 18:29:21 Using JPEG subsampling 0, Q79 for client 127.0.0.1 14/01/2020 18:29:21 Using compression level 9 for client 127.0.0.1 14/01/2020 18:29:21 Enabling LastRect protocol extension for client 127.0.0.1 14/01/2020 18:29:21 rfbProcessClientNormalMessage: ignoring unsupported encoding type Enc(0xFFFFFECC) 14/01/2020 18:29:21 Using tight encoding for client 127.0.0.1 14/01/2020 18:29:25 client_set_net: 127.0.0.1 0.0000 14/01/2020 18:29:25 created xdamage object: 0x40002e 14/01/2020 18:34:21 idle keyboard: turning X autorepeat back on. 14/01/2020 19:29:21 got closure, reason 1001 14/01/2020 19:29:21 rfbProcessClientNormalMessage: read: Connection reset by peer 14/01/2020 19:29:21 client_count: 0 14/01/2020 19:29:21 Client 127.0.0.1 gone 14/01/2020 19:29:21 Statistics events Transmit/ RawEquiv ( saved) 14/01/2020 19:29:21 FramebufferUpdate : 2726 | 0/ 0 ( 0.0%) 14/01/2020 19:29:21 LastRect : 1 | 12/ 12 ( 0.0%) 14/01/2020 19:29:21 tight : 2780 | 2546996/ 10724048 ( 76.2%) 14/01/2020 19:29:21 RichCursor : 1 | 1374/ 1374 ( 0.0%) 14/01/2020 19:29:21 TOTALS : 5508 | 2548382/ 10725434 ( 76.2%) 14/01/2020 19:29:21 Statistics events Received/ RawEquiv ( saved) 14/01/2020 19:29:21 FramebufferUpdate : 2728 | 27280/ 27280 ( 0.0%) 14/01/2020 19:29:21 SetEncodings : 1 | 56/ 56 ( 0.0%) 14/01/2020 19:29:21 SetPixelFormat : 1 | 20/ 20 ( 0.0%) 14/01/2020 19:29:21 TOTALS : 2730 | 27356/ 27356 ( 0.0%) 14/01/2020 19:29:21 destroyed xdamage object: 0x40002e 14/01/2020 21:00:06 Got connection from client 127.0.0.1 14/01/2020 21:00:06 other clients: 14/01/2020 21:00:06 Got 'ws' WebSockets handshake 14/01/2020 21:00:06 Got protocol: binary 14/01/2020 21:00:06 - webSocketsHandshake: using binary/raw encoding 14/01/2020 21:00:06 - WebSockets client version hybi-13 14/01/2020 21:00:06 Disabled X server key autorepeat. 14/01/2020 21:00:06 to force back on run: 'xset r on' (3 times) 14/01/2020 21:00:06 incr accepted_client=4 for 127.0.0.1:52812 sock=10 14/01/2020 21:00:06 Client Protocol Version 3.8 14/01/2020 21:00:06 Protocol version sent 3.8, using 3.8 14/01/2020 21:00:06 rfbProcessClientSecurityType: executing handler for type 1 14/01/2020 21:00:06 rfbProcessClientSecurityType: returning securityResult for client rfb version >= 3.8 14/01/2020 21:00:06 Pixel format for client 127.0.0.1: 14/01/2020 21:00:06 32 bpp, depth 24, little endian 14/01/2020 21:00:06 true colour: max r 255 g 255 b 255, shift r 16 g 8 b 0 14/01/2020 21:00:06 no translation needed 14/01/2020 21:00:06 Enabling NewFBSize protocol extension for client 127.0.0.1 14/01/2020 21:00:06 Enabling full-color cursor updates for client 127.0.0.1 14/01/2020 21:00:06 Using image quality level 6 for client 127.0.0.1 14/01/2020 21:00:06 Using JPEG subsampling 0, Q79 for client 127.0.0.1 14/01/2020 21:00:06 Using compression level 9 for client 127.0.0.1 14/01/2020 21:00:06 Enabling LastRect protocol extension for client 127.0.0.1 14/01/2020 21:00:06 rfbProcessClientNormalMessage: ignoring unsupported encoding type Enc(0xFFFFFECC) 14/01/2020 21:00:06 Using tight encoding for client 127.0.0.1 14/01/2020 21:00:10 client_set_net: 127.0.0.1 0.0000 14/01/2020 21:00:10 active keyboard: turning X autorepeat off. 14/01/2020 21:00:10 created xdamage object: 0x40002f 14/01/2020 21:05:08 idle keyboard: turning X autorepeat back on. 14/01/2020 21:10:09 got closure, reason 1001 14/01/2020 21:10:09 rfbProcessClientNormalMessage: read: Connection reset by peer 14/01/2020 21:10:09 client_count: 0 14/01/2020 21:10:09 Client 127.0.0.1 gone 14/01/2020 21:10:09 Statistics events Transmit/ RawEquiv ( saved) 14/01/2020 21:10:09 FramebufferUpdate : 388 | 0/ 0 ( 0.0%) 14/01/2020 21:10:09 LastRect : 1 | 12/ 12 ( 0.0%) 14/01/2020 21:10:09 tight : 421 | 408370/ 4929724 ( 91.7%) 14/01/2020 21:10:09 RichCursor : 1 | 1374/ 1374 ( 0.0%) 14/01/2020 21:10:09 TOTALS : 811 | 409756/ 4931110 ( 91.7%) 14/01/2020 21:10:09 Statistics events Received/ RawEquiv ( saved) 14/01/2020 21:10:09 FramebufferUpdate : 389 | 3890/ 3890 ( 0.0%) 14/01/2020 21:10:09 SetEncodings : 1 | 56/ 56 ( 0.0%) 14/01/2020 21:10:09 SetPixelFormat : 1 | 20/ 20 ( 0.0%) 14/01/2020 21:10:09 TOTALS : 391 | 3966/ 3966 ( 0.0%) 14/01/2020 21:10:09 destroyed xdamage object: 0x40002f 14/01/2020 21:11:02 Got connection from client 127.0.0.1 14/01/2020 21:11:02 other clients: 14/01/2020 21:11:02 Got 'ws' WebSockets handshake 14/01/2020 21:11:02 Got protocol: binary 14/01/2020 21:11:02 - webSocketsHandshake: using binary/raw encoding 14/01/2020 21:11:02 - WebSockets client version hybi-13 14/01/2020 21:11:02 Disabled X server key autorepeat. 14/01/2020 21:11:02 to force back on run: 'xset r on' (3 times) 14/01/2020 21:11:02 incr accepted_client=5 for 127.0.0.1:53144 sock=10 14/01/2020 21:11:02 Client Protocol Version 3.8 14/01/2020 21:11:02 Protocol version sent 3.8, using 3.8 14/01/2020 21:11:02 rfbProcessClientSecurityType: executing handler for type 1 14/01/2020 21:11:02 rfbProcessClientSecurityType: returning securityResult for client rfb version >= 3.8 14/01/2020 21:11:02 Pixel format for client 127.0.0.1: 14/01/2020 21:11:02 32 bpp, depth 24, little endian 14/01/2020 21:11:02 true colour: max r 255 g 255 b 255, shift r 16 g 8 b 0 14/01/2020 21:11:02 no translation needed 14/01/2020 21:11:02 Enabling NewFBSize protocol extension for client 127.0.0.1 14/01/2020 21:11:02 Enabling full-color cursor updates for client 127.0.0.1 14/01/2020 21:11:02 Using image quality level 6 for client 127.0.0.1 14/01/2020 21:11:02 Using JPEG subsampling 0, Q79 for client 127.0.0.1 14/01/2020 21:11:02 Using compression level 9 for client 127.0.0.1 14/01/2020 21:11:02 Enabling LastRect protocol extension for client 127.0.0.1 14/01/2020 21:11:02 rfbProcessClientNormalMessage: ignoring unsupported encoding type Enc(0xFFFFFECC) 14/01/2020 21:11:02 Using tight encoding for client 127.0.0.1 14/01/2020 21:11:02 client 5 network rate 320.7 KB/sec (52646.6 eff KB/sec) 14/01/2020 21:11:02 client 5 latency: 1.2 ms 14/01/2020 21:11:02 dt1: 0.0112, dt2: 0.0641 dt3: 0.0012 bytes: 23965 14/01/2020 21:11:02 link_rate: LR_LAN - 1 ms, 320 KB/s 14/01/2020 21:11:03 client_set_net: 127.0.0.1 0.0001 14/01/2020 21:11:03 active keyboard: turning X autorepeat off. 14/01/2020 21:11:03 created xdamage object: 0x400030 14/01/2020 21:16:03 idle keyboard: turning X autorepeat back on. 14/01/2020 21:21:05 got closure, reason 1001 14/01/2020 21:21:05 rfbProcessClientNormalMessage: read: Connection reset by peer 14/01/2020 21:21:05 client_count: 0 14/01/2020 21:21:05 Client 127.0.0.1 gone 14/01/2020 21:21:05 Statistics events Transmit/ RawEquiv ( saved) 14/01/2020 21:21:05 FramebufferUpdate : 611 | 0/ 0 ( 0.0%) 14/01/2020 21:21:05 LastRect : 1 | 12/ 12 ( 0.0%) 14/01/2020 21:21:05 tight : 644 | 510341/ 5196848 ( 90.2%) 14/01/2020 21:21:05 RichCursor : 1 | 1374/ 1374 ( 0.0%) 14/01/2020 21:21:05 TOTALS : 1257 | 511727/ 5198234 ( 90.2%) 14/01/2020 21:21:05 Statistics events Received/ RawEquiv ( saved) 14/01/2020 21:21:05 FramebufferUpdate : 612 | 6120/ 6120 ( 0.0%) 14/01/2020 21:21:05 SetEncodings : 1 | 56/ 56 ( 0.0%) 14/01/2020 21:21:05 SetPixelFormat : 1 | 20/ 20 ( 0.0%) 14/01/2020 21:21:05 TOTALS : 614 | 6196/ 6196 ( 0.0%) 14/01/2020 21:21:05 destroyed xdamage object: 0x400030 14/01/2020 21:22:16 Got connection from client 127.0.0.1 14/01/2020 21:22:16 other clients: 14/01/2020 21:22:16 Got 'ws' WebSockets handshake 14/01/2020 21:22:16 Got protocol: binary 14/01/2020 21:22:16 - webSocketsHandshake: using binary/raw encoding 14/01/2020 21:22:16 - WebSockets client version hybi-13 14/01/2020 21:22:16 Disabled X server key autorepeat. 14/01/2020 21:22:16 to force back on run: 'xset r on' (3 times) 14/01/2020 21:22:16 incr accepted_client=6 for 127.0.0.1:53480 sock=10 14/01/2020 21:22:16 Client Protocol Version 3.8 14/01/2020 21:22:16 Protocol version sent 3.8, using 3.8 14/01/2020 21:22:16 rfbProcessClientSecurityType: executing handler for type 1 14/01/2020 21:22:16 rfbProcessClientSecurityType: returning securityResult for client rfb version >= 3.8 14/01/2020 21:22:17 Pixel format for client 127.0.0.1: 14/01/2020 21:22:17 32 bpp, depth 24, little endian 14/01/2020 21:22:17 true colour: max r 255 g 255 b 255, shift r 16 g 8 b 0 14/01/2020 21:22:17 no translation needed 14/01/2020 21:22:17 Enabling NewFBSize protocol extension for client 127.0.0.1 14/01/2020 21:22:17 Enabling full-color cursor updates for client 127.0.0.1 14/01/2020 21:22:17 Using image quality level 6 for client 127.0.0.1 14/01/2020 21:22:17 Using JPEG subsampling 0, Q79 for client 127.0.0.1 14/01/2020 21:22:17 Using compression level 9 for client 127.0.0.1 14/01/2020 21:22:17 Enabling LastRect protocol extension for client 127.0.0.1 14/01/2020 21:22:17 rfbProcessClientNormalMessage: ignoring unsupported encoding type Enc(0xFFFFFECC) 14/01/2020 21:22:17 Using tight encoding for client 127.0.0.1 14/01/2020 21:22:17 client_set_net: 127.0.0.1 0.0001 14/01/2020 21:22:17 active keyboard: turning X autorepeat off. 14/01/2020 21:22:17 created xdamage object: 0x400031 14/01/2020 21:27:17 idle keyboard: turning X autorepeat back on. 14/01/2020 21:32:52 got closure, reason 1001 14/01/2020 21:32:52 rfbProcessClientNormalMessage: read: Connection reset by peer 14/01/2020 21:32:52 client_count: 0 14/01/2020 21:32:52 Client 127.0.0.1 gone 14/01/2020 21:32:52 Statistics events Transmit/ RawEquiv ( saved) 14/01/2020 21:32:52 FramebufferUpdate : 880 | 0/ 0 ( 0.0%) 14/01/2020 21:32:52 LastRect : 1 | 12/ 12 ( 0.0%) 14/01/2020 21:32:52 tight : 909 | 678200/ 5614620 ( 87.9%) 14/01/2020 21:32:52 RichCursor : 1 | 1374/ 1374 ( 0.0%) 14/01/2020 21:32:52 TOTALS : 1791 | 679586/ 5616006 ( 87.9%) 14/01/2020 21:32:52 Statistics events Received/ RawEquiv ( saved) 14/01/2020 21:32:52 PointerEvent : 71 | 426/ 426 ( 0.0%) 14/01/2020 21:32:52 FramebufferUpdate : 881 | 8810/ 8810 ( 0.0%) 14/01/2020 21:32:52 SetEncodings : 1 | 56/ 56 ( 0.0%) 14/01/2020 21:32:52 SetPixelFormat : 1 | 20/ 20 ( 0.0%) 14/01/2020 21:32:52 TOTALS : 954 | 9312/ 9312 ( 0.0%) 14/01/2020 21:32:52 destroyed xdamage object: 0x400031 Corrupt JPEG data: 524288 extraneous bytes before marker 0xdb 15/01/2020 07:31:12 Got connection from client 127.0.0.1 15/01/2020 07:31:12 other clients: 15/01/2020 07:31:12 Got 'ws' WebSockets handshake 15/01/2020 07:31:12 Got protocol: binary 15/01/2020 07:31:12 - webSocketsHandshake: using binary/raw encoding 15/01/2020 07:31:12 - WebSockets client version hybi-13 15/01/2020 07:31:12 Disabled X server key autorepeat. 15/01/2020 07:31:12 to force back on run: 'xset r on' (3 times) 15/01/2020 07:31:12 incr accepted_client=7 for 127.0.0.1:44222 sock=10 15/01/2020 07:31:12 Client Protocol Version 3.8 15/01/2020 07:31:12 Protocol version sent 3.8, using 3.8 15/01/2020 07:31:12 rfbProcessClientSecurityType: executing handler for type 1 15/01/2020 07:31:12 rfbProcessClientSecurityType: returning securityResult for client rfb version >= 3.8 15/01/2020 07:31:12 Pixel format for client 127.0.0.1: 15/01/2020 07:31:12 32 bpp, depth 24, little endian 15/01/2020 07:31:12 true colour: max r 255 g 255 b 255, shift r 16 g 8 b 0 15/01/2020 07:31:12 no translation needed 15/01/2020 07:31:12 Enabling NewFBSize protocol extension for client 127.0.0.1 15/01/2020 07:31:12 Using image quality level 6 for client 127.0.0.1 15/01/2020 07:31:12 Using JPEG subsampling 0, Q79 for client 127.0.0.1 15/01/2020 07:31:12 Using compression level 9 for client 127.0.0.1 15/01/2020 07:31:12 Enabling LastRect protocol extension for client 127.0.0.1 15/01/2020 07:31:12 rfbProcessClientNormalMessage: ignoring unsupported encoding type Enc(0xFFFFFECC) 15/01/2020 07:31:12 Using tight encoding for client 127.0.0.1 15/01/2020 07:31:14 client_set_net: 127.0.0.1 0.0000 15/01/2020 07:31:14 active keyboard: turning X autorepeat off. 15/01/2020 07:31:14 created xdamage object: 0x400032 15/01/2020 07:31:35 client 7 network rate 793.3 KB/sec (9893.3 eff KB/sec) 15/01/2020 07:31:35 client 7 latency: 2.3 ms 15/01/2020 07:31:35 dt1: 0.0027, dt2: 0.0174 dt3: 0.0023 bytes: 15096 15/01/2020 07:31:35 link_rate: LR_LAN - 2 ms, 793 KB/s 15/01/2020 07:38:00 idle keyboard: turning X autorepeat back on. 15/01/2020 07:45:03 got closure, reason 1001 15/01/2020 07:45:03 rfbProcessClientNormalMessage: read: Connection reset by peer 15/01/2020 07:45:03 client_count: 0 15/01/2020 07:45:03 Client 127.0.0.1 gone 15/01/2020 07:45:03 Statistics events Transmit/ RawEquiv ( saved) 15/01/2020 07:45:03 FramebufferUpdate : 546 | 0/ 0 ( 0.0%) 15/01/2020 07:45:03 LastRect : 35 | 420/ 420 ( 0.0%) 15/01/2020 07:45:03 tight : 1553 | 831284/ 11704724 ( 92.9%) 15/01/2020 07:45:03 TOTALS : 2134 | 831704/ 11705144 ( 92.9%) 15/01/2020 07:45:03 Statistics events Received/ RawEquiv ( saved) 15/01/2020 07:45:03 KeyEvent : 70 | 560/ 560 ( 0.0%) 15/01/2020 07:45:03 PointerEvent : 1112 | 6672/ 6672 ( 0.0%) 15/01/2020 07:45:03 FramebufferUpdate : 547 | 5470/ 5470 ( 0.0%) 15/01/2020 07:45:03 SetEncodings : 1 | 52/ 52 ( 0.0%) 15/01/2020 07:45:03 SetPixelFormat : 1 | 20/ 20 ( 0.0%) 15/01/2020 07:45:03 TOTALS : 1731 | 12774/ 12774 ( 0.0%) 15/01/2020 07:45:06 destroyed xdamage object: 0x400032 15/01/2020 07:46:11 Got connection from client 127.0.0.1 15/01/2020 07:46:11 other clients: 15/01/2020 07:46:11 Got 'ws' WebSockets handshake 15/01/2020 07:46:11 Got protocol: binary 15/01/2020 07:46:11 - webSocketsHandshake: using binary/raw encoding 15/01/2020 07:46:11 - WebSockets client version hybi-13 15/01/2020 07:46:11 Disabled X server key autorepeat. 15/01/2020 07:46:11 to force back on run: 'xset r on' (3 times) 15/01/2020 07:46:11 incr accepted_client=8 for 127.0.0.1:44680 sock=10 15/01/2020 07:46:11 Client Protocol Version 3.8 15/01/2020 07:46:11 Protocol version sent 3.8, using 3.8 15/01/2020 07:46:11 rfbProcessClientSecurityType: executing handler for type 1 15/01/2020 07:46:11 rfbProcessClientSecurityType: returning securityResult for client rfb version >= 3.8 15/01/2020 07:46:11 Pixel format for client 127.0.0.1: 15/01/2020 07:46:11 32 bpp, depth 24, little endian 15/01/2020 07:46:11 true colour: max r 255 g 255 b 255, shift r 16 g 8 b 0 15/01/2020 07:46:11 no translation needed 15/01/2020 07:46:11 Enabling NewFBSize protocol extension for client 127.0.0.1 15/01/2020 07:46:11 Using image quality level 6 for client 127.0.0.1 15/01/2020 07:46:11 Using JPEG subsampling 0, Q79 for client 127.0.0.1 15/01/2020 07:46:11 Using compression level 9 for client 127.0.0.1 15/01/2020 07:46:11 Enabling LastRect protocol extension for client 127.0.0.1 15/01/2020 07:46:11 rfbProcessClientNormalMessage: ignoring unsupported encoding type Enc(0xFFFFFECC) 15/01/2020 07:46:11 Using tight encoding for client 127.0.0.1 15/01/2020 07:46:12 client_set_net: 127.0.0.1 0.0000 15/01/2020 07:46:12 active keyboard: turning X autorepeat off. 15/01/2020 07:46:12 created xdamage object: 0x400033


