sworcery
Members
-
Joined
-
Last visited
Everything posted by sworcery
-
@rgreen83 Thanks for reporting this. I believe I found both issues. Image pull error: Somehow the GHCR package visibility got set to private — not sure how that happened since the repo itself is public. Should have inherited public visibility. Either way, I've flipped it to public now so ghcr.io/sworcery/mem-zero:latest should pull without authentication going forward. Dashboard username/password required: You're right, those fields were incorrectly marked as required in the template. I've updated them to optional so you can leave them blank to disable dashboard auth as intended. This fix will be in the next image push — if you want it immediately you can edit the container in Unraid and toggle the fields from "required" to "not required" manually, or just put dummy values in for now and clear them later. Let me know if you're still hitting issues after re-pulling.
-
mem-zero is a self-hosted memory server for AI coding assistants. It stores, searches, and manages persistent context across sessions so your tools remember what happened last week without stuffing everything into the context window. Each project gets its own isolated vector collection with automatic fact extraction and deduplication — all inside a single Docker container with no external dependencies. GitHub: https://github.com/sworcery/mem-zero Docker image: ghcr.io/sworcery/mem-zero:latest How It Works When you store text, an LLM extracts atomic facts (e.g. "User prefers Python over R"), checks each one against existing memories for duplicates, and embeds novel facts into a vector database for semantic search. When you search, only relevant memories are returned — not entire conversation logs. The project slug in the URL creates isolated collections, so memories from one project never leak into another. Connecting Your Tools mem-zero exposes both an MCP transport and a REST API. Any MCP client (Claude Code, Cursor, Windsurf, Claude Desktop, etc.) can connect by adding the server URL to its configuration: http://YOUR-UNRAID-IP:8765/mcp/your-project-slug/http/your-user-id For Claude Code specifically: claude mcp add mem-zero --transport http "http://YOUR-UNRAID-IP:8765/mcp/your-project-slug/http/your-user-id" -s local Anything that can make HTTP requests can also use the REST API directly — store memories with POST, search with POST, list/delete with GET/DELETE. Full endpoint reference is in the GitHub README. LLM Backends mem-zero supports three backends for fact extraction and deduplication: Bundled (default) — Ships with a quantized Qwen2.5-3B model that runs on CPU. Zero configuration, no external dependencies. Handles embeddings well and provides basic fact extraction. First startup downloads ~2 GB of models. Ollama (recommended) — Point it at an existing Ollama instance on your network with the OLLAMA_BASE_URL variable. A 7B+ model on GPU produces significantly better extraction — qwen2.5:14b is the sweet spot. If Ollama becomes unreachable, the bundled model automatically takes over as a fallback. OpenAI (beta) — Works with any OpenAI-compatible API (OpenAI, Groq, Together, etc.) via OPENAI_API_KEY and optional OPENAI_BASE_URL. Backend is auto-detected based on which environment variables are set, or you can force it with LLM_BACKEND. Web Dashboard A management UI is served at the container's root URL. From the dashboard you can monitor system health and uptime, browse all projects and their memory counts, view/search/delete individual memories, consolidate similar fragments into clean summaries, delete entire projects, and add memories manually. Enable DIAGNOSTICS_ENABLED=true to see performance metrics, accuracy stats, and score distributions. Optionally protect with basic auth via DASHBOARD_USER and DASHBOARD_PASS. Authentication API key auth is available for all MCP and REST endpoints. Set the API_KEY variable and requests must include it as a Bearer token. If not set, all endpoints are open — suitable for trusted networks. The dashboard has its own separate basic auth since browsers need a login prompt rather than Bearer tokens. Features Project-isolated memory — each project slug maps to its own Qdrant vector collection Semantic search with configurable top-k results Automatic fact extraction and deduplication via LLM Web dashboard with project browsing, memory search, and health monitoring Memory consolidation — merge similar fragments into clean summaries Cleanup tool for garbled text and multi-fact entries Re-embed tool to regenerate all embeddings after model changes MCP transport compatible with Claude Code, Cursor, Windsurf, Claude Desktop, and any MCP client Full REST API with endpoints for store, search, list, delete, reembed, cleanup, and consolidate Three LLM backends: bundled (zero config), Ollama (GPU-accelerated), OpenAI-compatible Automatic Ollama-to-bundled fallback when Ollama is unreachable API key authentication for MCP/REST endpoints (optional) Dashboard basic auth (optional) Diagnostics mode with performance and accuracy metrics Embedded Qdrant vector database — no external database required s6-overlay process supervision for all internal services Configurable embedding dimensions, collection prefix, and server bind settings Dark and light mode dashboard Requirements Docker ~2 GB disk for initial model download ~2 GB RAM minimum (bundled backend, more recommended for Ollama) Post here for support, bug reports, or feature requests.

-
@CyklonDX You were right, this was a bug. The download delay timer was a single shared timer, so concurrent downloads were all stepping on each other instead of staggering independently. Fixed now. If you have 3 concurrent slots and a 15 second delay, downloads will kick off at T+0, T+15, and T+30 regardless of how long each one takes. The queue also fills all available slots at once now instead of picking up one at a time. Limit Scrape by Year Done! Each channel now has a "Download From Year" field in the Download Settings section. Set it to something like 2023 and it'll only grab videos from 2023 onward. Anything older gets skipped during scans. Leave it blank to download everything like before. 480p Without Premium Cookies This one is actually a YouTube restriction, not something on our end. Without cookies from a Premium account, YouTube throttles the available streams, and for some content you'll only get 480p even though higher quality exists on the page. If you want full quality access, make sure your cookies are coming from a browser that's logged into YouTube Premium. You can check if your cookies are working under Settings > Authentication.
-
That's my fault -- the orphan cleanup I added in v1.7.15 had a typo in a table name. Fixed in v1.7.16, just pushed. Update and it should start right up. Sorry about that!
-
@alicecantsleep Found it -- this is the same orphan record issue from before the foreign key fix. When the channel was originally deleted, the 7 video records were left behind in the database. Since video IDs are globally unique, re-adding the channel sees those orphan records and thinks the videos already exist, so it skips all of them. Fixed in v1.7.15 (just pushed). Update and delete/re-add the channel one more time -- the orphan records will be cleaned up automatically on startup, and the scan should pick up all 7 videos.
-
@alicecantsleep Two things going on here: SPLIFF RADIO showing 0/0 with "internal service error": Your logs show the channel getting scanned twice within 4 seconds (manual scan + scheduled scan colliding). The second scan tried to insert the same 7 videos and crashed on a duplicate key constraint, which rolled back the whole thing. Fixed in v1.7.14 -- concurrent scans on the same channel are now prevented. Update to v1.7.14 and either use the Force Re-scan button (next to Scan Now) to clear out the stuck state and start fresh, or just hit Scan Now -- it should work cleanly now that the race condition is fixed. Playlist addition failing: The error "YouTube said: The playlist does not exist" is coming from YouTube itself rejecting that playlist ID. That specific playlist may be private, deleted, or the URL might have extra characters. Can you double-check the playlist URL works when you open it in a browser? If it does, share the URL format you're using (with the list ID redacted if you prefer) and I'll take a look.
-
@alicecantsleep This should be fixed in v1.7.13 (just released). There's a new Force Re-scan button on the channel detail page under the Monitoring section, next to "Scan Now." It will wipe all the video records for that channel and re-scan from scratch, which should clear out whatever is stuck. Update to v1.7.13 and give that a try on the stuck channel. Let me know if it sorts it out!
-
@alicecantsleep - For bug tracking, GitHub issues work best - I can link fixes directly to releases. The forum is great for feature requests and discussion though. All the issues you reported have been addressed in v1.7.11: Re-added channels failing to sync - fixed Settings not persisting - fixed Channel delete options (keep files vs delete everything) - added File permissions (chmod/chown like Sonarr) - added Update your container and let me know how it goes!
-
v1.7.10 Update Big update with Sonarr-style episode management and several new features: Monitored/Unmonitored episodes - Toggle monitoring per episode or in bulk. Download All only queues monitored videos. Status icons - Colored icons showing download state at a glance (downloaded, missing, queued, failed, skipped, etc.) Collapsible seasons - Videos grouped by year with per-season Download Missing and Monitor buttons Quality cutoff - Set minimum quality per channel and search for upgrades on existing downloads Per-episode actions - Three-dot menu with Re-download, Rename File, Delete File, and Skip Subtitle download - Toggle in Settings to download captions with videos Min duration filter - Per-channel setting to skip videos below a configurable length Playlist support fix - Playlists now properly index all videos Completion percentages - Skipped/unmonitored videos no longer count against channel progress In-app help links - "Learn more" links throughout settings that go directly to the relevant documentation Update to v1.7.10 to get everything!
-
@alicecantsleep Great testing, really appreciate the thorough feedback! Pushed v1.7.2 with fixes for both issues you found: Fixed: Playlist scanning - Playlists now properly index all videos within. Previously it was only pulling the playlist name but not discovering the videos. Episode renamer orphan files - .info.json files are now renamed alongside the .mp4, .nfo, and thumbnail files. The leftover files you saw with the old names should no longer happen on future renames. Also added in-app help tooltips throughout the settings pages - hover the question mark icons for setup guides. Update to v1.7.2 and try re-adding your playlist. For the renamed episodes, you may want to manually delete the orphan .info.json files from that Season 2016 folder since they were created before the fix. Let me know how the rest of your testing goes! Just saw suggestions portion: Shorts filter - The current filter already catches any video under 60 seconds in length, regardless of whether it was posted as a YouTube Short or as a regular video. So if a channel posts a 45-second video on their main page, it will still be detected and skipped (if shorts filtering is enabled for that channel). That said, I can see how some channels post slightly longer "short content" (trailers, teasers, 90-second clips) that you'd also want to filter out. I'm looking into adding a configurable minimum duration setting per channel so you can set your own threshold (e.g. skip anything under 3 minutes). That would give more control than the fixed 60-second cutoff. Channel percentages - Agreed, skipped episodes shouldn't count against the completion percentage. Adding this to the list. Subtitles/captions - Great idea. yt-dlp already supports downloading subtitles and auto-generated captions, just needs a toggle in the settings to enable it. On the list for a future update.
-
@alicecantsleep Thanks again for the detailed feedback! I've pushed v1.7.0 that addresses your list. Bug Fixes: Episode numbering - Episodes are now numbered chronologically by upload date within each year (oldest = E001). There's also a new "Fix Episode Numbers" button on each channel's detail page that lets you preview what would change and apply the fix, including renaming files on disk. Skip queued episodes - You can now skip videos that are already in the download queue. Cookie invalidation loop - Fixed the issue where a failing download would immediately invalidate freshly uploaded cookies. Livestream detection - Upcoming livestreams are now automatically skipped instead of retrying. New Features: Playlist support - You can now add YouTube playlist URLs directly (e.g. https://www.youtube.com/playlist?list=PLxxxx). Delete individual episodes - Each video in the channel detail page now has a delete button (trash icon) that removes the video, NFO, and thumbnail from disk. Auto-download toggle - When adding a channel, uncheck "Auto-download new videos" to browse the channel first without automatically queuing everything. This persists for future scans too. Season posters - Plex season poster images are now automatically created in each Season folder. Channel logo - Can you give me more details on this one? Is it showing a gray placeholder? Which channel does it happen on? The channel logo/thumbnail issue is now fixed in v1.7.1. The logos are now fetched via the YouTube Data API instead of yt-dlp (which was returning 404 errors for channel pages). If you have a YouTube API key configured in Settings, all existing channels will have their thumbnails backfilled automatically on the next container restart. Update your container to v1.7.0 to get everything. Let me know how it goes!
-
Thanks for reporting this! I found the bug and just pushed a fix in v1.4.4. The database initialization was missing a required import, so tables never got created on fresh installs. To fix it, just update the container: Go to the Docker tab in Unraid Click the ChannelHoarder icon and select "Force Update" Start the container If the old database file is still there from the failed attempts, delete it first: remove everything in your /config appdata folder before starting the updated container so it gets a clean slate. Let me know if you run into anything else!
-
ChannelHoarder is a self-hosted video channel archiver with a modern web UI. It monitors channels across YouTube, Rumble, Twitch, Dailymotion, Vimeo, and Odysee and automatically downloads new videos in Plex-compatible format - all inside a single Docker container. GitHub: https://github.com/sworcery/ChannelHoarder Docker Image: ghcr.io/sworcery/channelhoarder:latest How It Works Add a channel URL or playlist, and ChannelHoarder will scan it for videos and queue them for download. New videos are checked on a configurable schedule (default: 3 AM daily). Downloaded videos are organized in Plex TV Show format - each channel is a "show", each year is a "season", and videos are numbered as episodes in upload order. Point your Plex TV Shows library at the download folder and everything just works. Episode Management Sonarr-style episode handling with per-episode monitored/unmonitored toggles, colored status icons, collapsible season groups with per-season actions, quality cutoff with upgrade detection, and a per-episode action menu (re-download, rename, delete file, skip). Authentication ChannelHoarder includes a built-in PO token server so most YouTube videos download without any account or cookies. When cookies are available they take priority over PO tokens. For cookie management you have three options: Upload a cookies.txt file manually through the Settings page Use the included Tampermonkey userscript - install it from Settings for automatic browser cookie sync Use the Firefox cookie exporter script for scheduled cookie refresh on a Windows machine Features Automatic channel scanning and downloading on a configurable schedule Playlist support - add YouTube playlists by URL Plex-compatible TV Show naming (Channel / Season Year / S01E01 - Title) Monitored/unmonitored per episode with bulk actions Sonarr-style status icons (downloaded, missing, queued, failed, skipped) Collapsible season groups with per-season download and monitor controls Quality cutoff with upgrade detection and search Per-episode file management (re-download, rename, delete file, skip) Auto-download toggle - browse a channel before downloading Subtitle/caption download support Minimum duration filter per channel Built-in PO token server - no YouTube account required Smart auth - cookies take priority over PO tokens when available YouTube Shorts detection and filtering Real-time download progress via WebSocket Per-channel quality settings (best, 1080p, 720p, 480p) Per-channel custom download directories Standalone video download by URL (no channel required) Import existing video libraries with fuzzy title matching Telegram and Pushover notifications Multi-platform: YouTube, Rumble, Twitch, Dailymotion, Vimeo, Odysee Error diagnostics with classification and suggested fixes Anti-detection settings (configurable delays, jitter, user-agent rotation) In-app help links to documentation Config import/export for backup and migration Dark and light mode Plex Setup Add your downloads folder as a TV Shows library in Plex. ChannelHoarder generates tvshow.nfo and episode .nfo metadata files along with poster images and season posters so channels appear with proper artwork and descriptions. Since these are YouTube channels and not traditional TV shows, Plex won't find metadata from its online sources - you may need to set the library agent to "Personal Media" or manually edit show/episode metadata like descriptions and artwork to your liking. Requirements Docker and Docker Compose 50 GB+ disk space (plan 500 MB - 1 GB per video at best quality) Post here for support, bug reports, or feature requests.

-
The insecure login did fix for me.
-
I did but it is resetting itself when the container restarts. might be because I imported the xml you linked in the original post. I'm able to get into the interface now but having trouble starting a server. Is there an eta when this will be released to unraid apps?
-
so I tried this out with a custom docker container and I can get it running but every time I login it immediately expires my session and I can't change any settings.
-
Is there a way to export a world out to a .mcworld or even zip format? I want to delete the chunks with MCC ToolChest that aren't in use in order to get the newer stuff from caves and cliffs and such, but this world is from 1.17.
-
Could it be that having my P2200 in a higher PCI-e slot that it is overriding the GPU variable? I have the RTX 2080 on my bottom slot because otherwise I would blocking a needed PCI-e slot. I could get a riser cable and try placing the 2080 in a higher slot. The GPU variable was working before until a recent update however. The most recent one I have a record of was on May 15 and the GPU variable was working before a reboot about 5 days ago and updates are done nightly.
-
I haven't been able to play for a few days now. kept getting the out of date client message. I had to add :1.18.33.02-01 to repo field and I'm back up and running. it had me on 1.19 even thought I don't have anything marked for beta.
-
I've also tried wiping on the config file that gets created, and both with or without the NVIDIA_VISIBLE_DEVICES variable defined, I end up with the same issues.
-
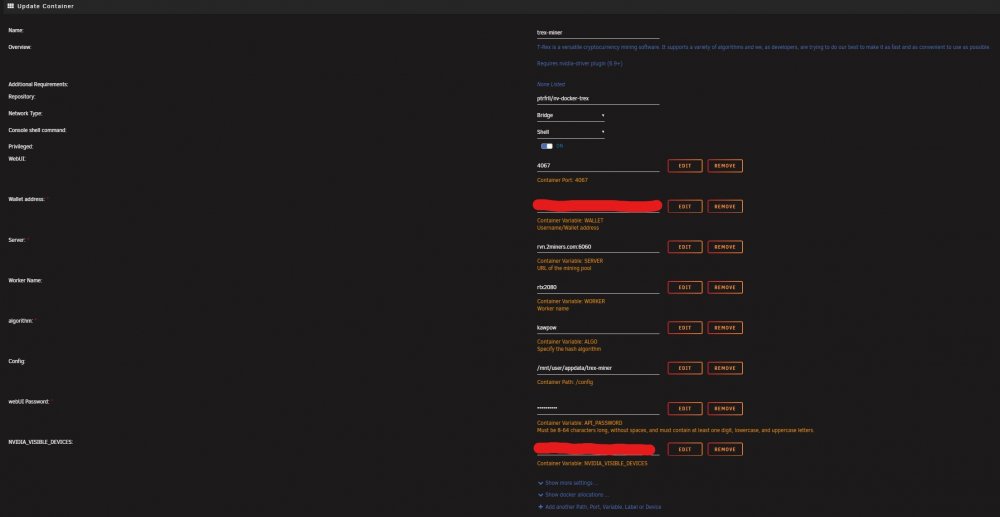
I'm having an issue. I've defined the NVIDIA_VISIBLE_DEVICES variable and targeted only one of the 2 GPU I have in my system, a Quadro P2200 and an RTX 2080. I would like to only target the RTX 2080 for mining, however even after defining the GPU to target in the docker variables, both the P2200 and RTX 2080 show. When I try to disable the P2200 in Trex settings, I received an error message of: Edit config error (number of specified LHR tuning values in config doesn't match the number of GPUs) This error happens with or without the NVIDIA_VISIBLE_DEVICES defined in the docker settings. I've thought about manually pausing the P2200 but then I run the same error above when I try to limit power on the 2080.
-
ok great, thanks. This just finished for me, v1 db was 74GB, v2 db is 39GB. are we safe to delete v1 db at this point? I can see the sqlite-shm and sqlite-wal are for v2 after a container restart.
-
@guy.davis do we need to run this db upgrade command on all forks or just chia?
-
iirc @guy.davis said on discord that flora isn't ready just yet, he's working on fixes on the :develop branch.
-
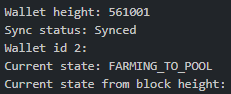
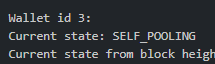
just wanted to make sure this was correct. I have a standard wallet and 2 pooling wallets. My pool I joined is on wallet ID 2, and it appears to be functioning properly. Wasn't sure if wallet ID 3 should be any concern. I had joined and left another pool previously before figuring out how to properly setup my pool and plotting. Only wallet ID 2 and 3 show up on my pooling page. I'm seeing frequent partials as well on my pool.