




fysmd
Members
-
Joined
-
Last visited
Everything posted by fysmd
-
so I had an HDD with lots of write errors and chose to replace it. While rebuilding on a replacement drive, a different one has gone offline, unraid rebooted and it continues to rebuild but whith another failed HDD (I have dual parity). Unraid 7.2.3 and diag attached. Can somebody help me find any clues regarding why Disk11 ST12000NM001G-2MV103_ZL22S92B (sdm) went offline? I know it's old but did it just die or is there something happening whcih I've not seen? server-diagnostics-20260222-1200.zip
-
Hello - I have a cache dirive and a second pool, I selected the 2nd for the cache for a new share but the files went to cache drive anyway. Did I miss a step somewhere? Unraid Pro 7.1.2
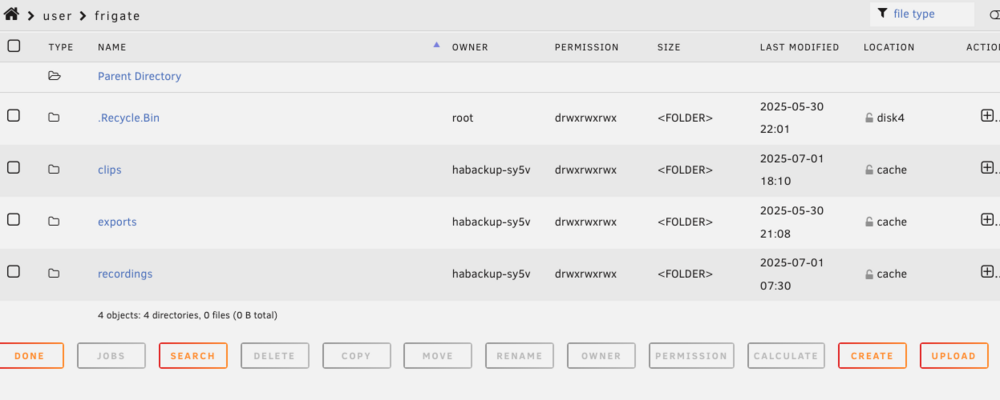

-
I find that this drive is not in my array - should my array be safe once the rebuild finishes? .. and safe to let it finish building? The suspect drive hs spun down now so the errors stopped..
-
Brilliant, thank you for the help - how did you find that?
-
Nothing leaped out as an error, no popups or anyhting but looking at the log while rebuilding onto a larger disk I notice a LOT of below, do I need to stop it and replace something? I dont know how to read below to ID the disk ec 6 14:50:00 Server kernel: ata4.00: exception Emask 0x0 SAct 0x0 SErr 0x0 action 0x0 Dec 6 14:50:00 Server kernel: ata4.00: irq_stat 0x40000001 Dec 6 14:50:00 Server kernel: ata4.00: failed command: READ DMA Dec 6 14:50:00 Server kernel: ata4.00: cmd c8/00:08:00:00:00/00:00:00:00:00/e0 tag 29 dma 4096 in Dec 6 14:50:00 Server kernel: res 53/04:08:00:00:00/00:00:00:00:00/e0 Emask 0x1 (device error) Dec 6 14:50:00 Server kernel: ata4.00: status: { DRDY SENSE ERR } Dec 6 14:50:00 Server kernel: ata4.00: error: { ABRT } Dec 6 14:50:00 Server kernel: ata4.00: configured for UDMA/133 (device error ignored) Dec 6 14:50:00 Server kernel: ata4: EH complete Dec 6 14:50:00 Server kernel: ata4.00: exception Emask 0x0 SAct 0x0 SErr 0x0 action 0x0 Dec 6 14:50:00 Server kernel: ata4.00: irq_stat 0x40000001 Dec 6 14:50:00 Server kernel: ata4.00: failed command: READ DMA Dec 6 14:50:00 Server kernel: ata4.00: cmd c8/00:08:00:00:00/00:00:00:00:00/e0 tag 0 dma 4096 in Dec 6 14:50:00 Server kernel: res 53/04:08:00:00:00/00:00:00:00:00/e0 Emask 0x1 (device error) Dec 6 14:50:00 Server kernel: ata4.00: status: { DRDY SENSE ERR } Dec 6 14:50:00 Server kernel: ata4.00: error: { ABRT } Dec 6 14:50:00 Server kernel: ata4.00: configured for UDMA/133 (device error ignored) Dec 6 14:50:00 Server kernel: ata4: EH complete Dec 6 14:50:00 Server kernel: ata4.00: exception Emask 0x0 SAct 0x0 SErr 0x0 action 0x0 Dec 6 14:50:00 Server kernel: ata4.00: irq_stat 0x40000001 Dec 6 14:50:00 Server kernel: ata4.00: failed command: READ DMA Dec 6 14:50:00 Server kernel: ata4.00: cmd c8/00:08:00:00:00/00:00:00:00:00/e0 tag 2 dma 4096 in Dec 6 14:50:00 Server kernel: res 53/04:08:00:00:00/00:00:00:00:00/e0 Emask 0x1 (device error) Dec 6 14:50:00 Server kernel: ata4.00: status: { DRDY SENSE ERR } Dec 6 14:50:00 Server kernel: ata4.00: error: { ABRT } Dec 6 14:50:00 Server kernel: ata4.00: configured for UDMA/133 (device error ignored) Dec 6 14:50:00 Server kernel: ata4: EH complete Dec 6 14:50:00 Server kernel: ata4.00: exception Emask 0x0 SAct 0x0 SErr 0x0 action 0x0 Dec 6 14:50:00 Server kernel: ata4.00: irq_stat 0x40000001 Dec 6 14:50:00 Server kernel: ata4.00: failed command: READ DMA Dec 6 14:50:00 Server kernel: ata4.00: cmd c8/00:08:00:00:00/00:00:00:00:00/e0 tag 4 dma 4096 in Dec 6 14:50:00 Server kernel: res 53/04:08:00:00:00/00:00:00:00:00/e0 Emask 0x1 (device error) Dec 6 14:50:00 Server kernel: ata4.00: status: { DRDY SENSE ERR } Dec 6 14:50:00 Server kernel: ata4.00: error: { ABRT } Dec 6 14:50:00 Server kernel: ata4.00: configured for UDMA/133 (device error ignored) Dec 6 14:50:00 Server kernel: ata4: EH complete Dec 6 14:50:00 Server kernel: ata4.00: exception Emask 0x0 SAct 0x0 SErr 0x0 action 0x0 Dec 6 14:50:00 Server kernel: ata4.00: irq_stat 0x40000001 Dec 6 14:50:00 Server kernel: ata4.00: failed command: READ DMA Dec 6 14:50:00 Server kernel: ata4.00: cmd c8/00:08:00:00:00/00:00:00:00:00/e0 tag 20 dma 4096 in Dec 6 14:50:00 Server kernel: res 53/04:08:00:00:00/00:00:00:00:00/e0 Emask 0x1 (device error) Dec 6 14:50:00 Server kernel: ata4.00: status: { DRDY SENSE ERR } Dec 6 14:50:00 Server kernel: ata4.00: error: { ABRT } Dec 6 14:50:00 Server kernel: ata4.00: configured for UDMA/133 (device error ignored) Dec 6 14:50:00 Server kernel: ata4: EH complete server-diagnostics-20241206-1452.zip
-
Hello all! I have attached a diag. My server no longer understands that it once ran a VM for me and there are some cache disk errors logged.. I am part way throiugh upgrading a bunch of disks and this morning I stopped the array in order to include only the new, larger drives in shares so I can use unbalanced to empty the small ones (I plan to remove all those empty HDDs at some point in the future). One such unbalance move was in progress when the errors were logged I think. Should I be worried about my cache disk? It´s a sngle SSD. Any tips on what I should do next greatfully received and appreciated. server-diagnostics-20240407-1531.zip
-
Can you explain how you determine power issues from logs - what to look for for me please? I'd like to me able to identify such myself.
-
Ahh - OK, I did read about losing trim but I thought that was related to the devices which allow four drive to user one host port. Will make some changes, Thanks!
-
I have three USB devices which I pass through to HOmeassistant in a VM, these have been working well and conneect on boot sucessfully for a long time now, They are all assigned to the VM: Dec 29 10:15:53 Server kernel: usb 1-13: USB disconnect, device number 8 Dec 29 10:15:53 Server kernel: usb 1-13.1: USB disconnect, device number 9 Dec 29 10:15:54 Server kernel: usb 1-13: clear tt 1 (90a2) error -110 Dec 29 10:15:54 Server kernel: usb 1-13.4: USB disconnect, device number 10 Dec 29 10:15:54 Server usb_manager: Info: rc.usb_manager usb_remove /dev/bus/usb/001/010 001 010 Dec 29 10:15:54 Server usb_manager: Info: rc.usb_manager Device Match 001/010 vm: HomeAssistant 001 010 Dec 29 10:15:54 Server usb_manager: Info: rc.usb_manager usb_remove /dev/bus/usb/001/009 001 009 Dec 29 10:15:54 Server kernel: usb 1-13: new high-speed USB device number 11 using xhci_hcd Dec 29 10:15:54 Server usb_manager: Info: virsh called HomeAssistant 001 010 Device detached successfully Dec 29 10:15:54 Server usb_manager: Info: rc.usb_manager Disconnect 001/010 vm: HomeAssistant running 001 010 Dec 29 10:15:54 Server usb_manager: Info: rc.usb_manager Removed 001/010 vm: HomeAssistant running 001 010 Dec 29 10:15:54 Server kernel: hub 1-13:1.0: USB hub found Dec 29 10:15:54 Server kernel: hub 1-13:1.0: 4 ports detected Dec 29 10:15:54 Server usb_manager: Info: rc.usb_manager usb_remove /dev/bus/usb/001/008 001 008 Dec 29 10:15:54 Server usb_manager: Info: rc.usb_manager Device Match 001/008 vm: 001 008 Dec 29 10:15:54 Server usb_manager: Info: rc.usb_manager Removed 001/008 vm: nostate 001 008 Dec 29 10:15:54 Server usb_manager: Info: rc.usb_manager usb_add 1a40_USB_2.0_Hub /dev/bus/usb/001/011 001 011 Dec 29 10:15:54 Server kernel: usb 1-13.1: new full-speed USB device number 12 using xhci_hcd Dec 29 10:15:55 Server kernel: ch341 1-13.1:1.0: ch341-uart converter detected Dec 29 10:15:55 Server kernel: usb 1-13.1: ch341-uart converter now attached to ttyUSB0 Dec 29 10:15:55 Server kernel: usb 1-13.4: new full-speed USB device number 13 using xhci_hcd Dec 29 10:15:55 Server kernel: ftdi_sio 1-13.4:1.0: FTDI USB Serial Device converter detected Dec 29 10:15:55 Server kernel: usb 1-13.4: Detected FT232RL Dec 29 10:15:55 Server kernel: usb 1-13.4: FTDI USB Serial Device converter now attached to ttyUSB1 Dec 29 10:15:55 Server usb_manager: Info: rc.usb_manager Autoconnect No Mapping found 1a40_USB_2.0_Hub /dev/bus/usb/001/011 001 011 port 1-13 Dec 29 10:15:55 Server usb_manager: Info: rc.usb_manager tty_add 1a86_USB_Serial /dev/ttyUSB0 Dec 29 10:15:55 Server usb_manager: Info: rc.usb_manager tty_add SHK_NANO_CUL_868 /dev/ttyUSB1 Dec 29 10:15:55 Server usb_manager: Info: rc.usb_manager Processing tty attach 1a86_USB_Serial /dev/ttyUSB0 Dec 29 10:15:55 Server usb_manager: Info: rc.usb_manager Autoconnect No Mapping found 1a86_USB_Serial /dev/ttyUSB0 port Dec 29 10:15:55 Server usb_manager: Info: rc.usb_manager Processing tty attach SHK_NANO_CUL_868 /dev/ttyUSB1 Dec 29 10:15:55 Server usb_manager: Info: rc.usb_manager Autoconnect No Mapping found SHK_NANO_CUL_868 /dev/ttyUSB1 port Dec 29 10:15:55 Server usb_manager: Info: rc.usb_manager usb_add 1a86_USB_Serial /dev/bus/usb/001/012 001 012 Dec 29 10:15:55 Server usb_manager: Info: rc.usb_manager usb_add SHK_NANO_CUL_868 /dev/bus/usb/001/013 001 013 Dec 29 10:15:56 Server usb_manager: Info: rc.usb_manager Autoconnect Parent 1-13 Dec 29 10:15:56 Server usb_manager: Info: rc.usb_manager Autoconnect No Mapping found 1a86_USB_Serial /dev/bus/usb/001/012 001 012 port 1-13.1 Dec 29 10:15:56 Server usb_manager: Info: rc.usb_manager Autoconnect Parent 1-13 Dec 29 10:15:56 Server usb_manager: Info: rc.usb_manager Autoconnect No Mapping found SHK_NANO_CUL_868 /dev/bus/usb/001/013 001 013 port 1-13.4 Any tips / tricks / hints greatly appreciated.. server-diagnostics-20221230-0909.zip

-
Hi, I am running 6.9.2 and noticed errors in syslog this morning which I think suggest one of mt cache pool drives is misbehaving but there are no errors displayed anywhere, nor any note on that drive - are these just info or should I change this drive? Dec 30 07:44:06 Server kernel: sd 7:0:8:0: attempting task abort!scmd(0x0000000094d60fd2), outstanding for 30352 ms & timeout 30000 ms Dec 30 07:44:06 Server kernel: sd 7:0:8:0: [sdp] tag#4543 CDB: opcode=0x28 28 00 03 20 d8 00 00 00 08 00 Dec 30 07:44:06 Server kernel: scsi target7:0:8: handle(0x0021), sas_address(0x300062b202f04009), phy(9) Dec 30 07:44:06 Server kernel: scsi target7:0:8: enclosure logical id(0x500062b202f04000), slot(18) Dec 30 07:44:06 Server kernel: scsi target7:0:8: enclosure level(0x0000), connector name( ) Dec 30 07:44:06 Server kernel: sd 7:0:8:0: task abort: SUCCESS scmd(0x0000000094d60fd2) Dec 30 07:44:06 Server kernel: sd 7:0:8:0: [sdp] tag#4543 UNKNOWN(0x2003) Result: hostbyte=0x03 driverbyte=0x00 cmd_age=30s Dec 30 07:44:06 Server kernel: sd 7:0:8:0: [sdp] tag#4543 CDB: opcode=0x28 28 00 03 20 d8 00 00 00 08 00 Dec 30 07:44:06 Server kernel: blk_update_request: I/O error, dev sdp, sector 52484096 op 0x0:(READ) flags 0x80700 phys_seg 1 prio class 0 Dec 30 07:44:06 Server kernel: sd 7:0:8:0: attempting task abort!scmd(0x00000000d67ffc34), outstanding for 30382 ms & timeout 30000 ms Dec 30 07:44:06 Server kernel: sd 7:0:8:0: [sdp] tag#4541 CDB: opcode=0x28 28 00 03 20 56 08 00 00 08 00 Dec 30 07:44:06 Server kernel: scsi target7:0:8: handle(0x0021), sas_address(0x300062b202f04009), phy(9) Dec 30 07:44:06 Server kernel: scsi target7:0:8: enclosure logical id(0x500062b202f04000), slot(18) Dec 30 07:44:06 Server kernel: scsi target7:0:8: enclosure level(0x0000), connector name( ) Dec 30 07:44:06 Server kernel: sd 7:0:8:0: No reference found at driver, assuming scmd(0x00000000d67ffc34) might have completed Dec 30 07:44:06 Server kernel: sd 7:0:8:0: task abort: SUCCESS scmd(0x00000000d67ffc34) Dec 30 07:44:06 Server kernel: sd 7:0:8:0: [sdp] tag#4541 UNKNOWN(0x2003) Result: hostbyte=0x03 driverbyte=0x00 cmd_age=30s Dec 30 07:44:06 Server kernel: sd 7:0:8:0: [sdp] tag#4541 CDB: opcode=0x28 28 00 03 20 56 08 00 00 08 00 Dec 30 07:44:06 Server kernel: blk_update_request: I/O error, dev sdp, sector 52450824 op 0x0:(READ) flags 0x80700 phys_seg 1 prio class 0 complete diag attached. server-diagnostics-20221230-0909.zip
-
..but I've no clue what to look for / do Really would appreciate some pointers / advise. server-diagnostics-20220831-1201.zip
-
Thanks for your help. My drives have remained stable and parity2 (just) completed building. I need to work out how to get the probably-fine-but out of the darray drive back in there now but I'l going to leave it for another day - for us both to recover a bit Bought some larger drives for parity(s) so they can go in once all back to normal.. KR Ian.
-
some but I've no way to knowing what they are/were (or do I!?)
-
Thank-you. I paused the parity rebuild, and fixed the fs in maint mode. Just restarted and partiy build is continuing on 2nd parity disk. Failed drive still emulated (red cross) but does not show unmountable any more. I have a spare drive so once parity2 is done I'll rebuild to that one..
-
Ok I checked and it's almost certainly power, all drives which barfed were on the same cable. I was not able to replace all components but that which I could has been replaced and all reseated and run more neatly... Unraid started up again but now one of the drives shows as unmountable, new diag attached. As it shows unmountable and so not emulated, have I just lost data?? server-diagnostics-20220406-2034.zip

-
Thanks, will go check!.
-
diag attached. I have had four drives fail in the last few weeks, nothing changed physcially. While recovering from dual HDD failure (have two parity - phew!) yet another has dropped and one also in error I"m worried, what should I be looking at / for? Any advise gratefully received.. server-diagnostics-20220406-1830.zip
-
So I've been stable since changing to force vers=1.0 Is this a bug - as there's nothing logged how do we report it (usefully!)?
-
I have see the same on ubuntu 18 host AND a 2nd unrid server using unassigned devices to mount. Spent ages thinking it was a problem with unassigned devices plugin... I notice that the web UI on the server machine runs VERY slowly once this issue begins. Noting obvs in any logs anywhere Switching to vers=1.0..
-
Nahh, the HDHRs are on the same LAN and subnet and pingable, including from the server As I said, I can add manualy and it'll progress but fail to enable properly I had a backup but as I've replaced my USB in the last 12 months, I need to wait for a replacement license from LimeTech - No way the house would function without Plex for that time so I chose to restart from scratch (other than this plex issue it was really easy!) I have recreated a new instance of plex, stopped my other and find that running this new instance (no media added or anything) it auto detects the HDHRs properly and immediately, the rest of the setup process also completes successfully too. I must have some broken config somewhere??
-
Hey Guys, I've been running LSIO's Plex container for MANY years on unraid with great sucess now (so thank you!) Unfortunately I've recently had hardware issues (failed USB) and so until get a replacment license I rebuilt my machine on a temp Unraid license. Since then, my Plex container has not been able to see my HDHRs and is has no idea that DVR has been configured and running for a long time No DVR so nothing is recording If I try to re-add my DVR, I get the "introducing Live TV & DVR" splash and when I hit "Set up Plex DVR" I get "There was a problem discovering devices" If I manually enter the IP address of one of my HDHRs the setup wizard progresses and says complete but no DVR links appear in my menus
-
.. and do sensible importing of duplicates (higher bitrate only)





