




ElectroBlvd
Members
-
Joined
-
Last visited
-
So I found the problem with this. The Plex docker from pms-docker from plexinc was causing the memory issue when it would run its daily maintenance. Even if I went into plex and unchecked everything in the scheduled maintenance tasks, it would still run and just flood the memory slowly until the server crashed. I stopped the official plex docker from running and installed the binhex version and have not had an issue since.
-
Ok, so how do I figure out what's going on at 4am every morning that eats up my memory forcing my server to stop a process that ultimately makes all my shares disappear? Having to restart the server every day is starting to get....frustrating. Especially if I forget to restart it before leaving for work and then need to access something on it and can't cause its down.
-
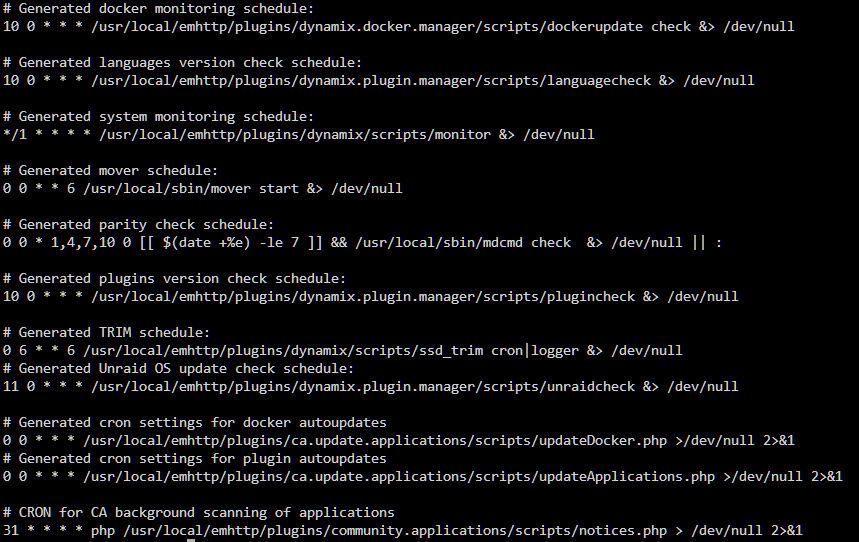
I don't see anything that says Scheduled Tasks but I do see an icon that says Scheduler. I'm assuming that's what you're referring to? Is that the only place? Cause the only things in there is Parity Check, Mover and Trim which none of those are set for 4am daily. Running the command you asked gave me.....
-
So confirmed at 430a this morning that it is happening at 4am every day. I read somewhere, before creating this thread, that there's some automated process that happens around that time built into unraid but can't remember what it was or where I read that. I looked through every setting I could think of in unraid to see if I had anything scheduled during that time and found nothing. Would you be able to advise me on where all the scheduled tasks sections are in unraid so I can make sure I didn't miss anything?
-
Here's the zip main-ur-data01-diagnostics-20250423-2213.zip
-
Eh....I clicked to download the zip file this morning when I noticed my shares were missing again. And then restarted my server. But I guess I didn't notice the file didn't download before restarting. So I don't have that zip file. I guess I'll have to wait till the shares disappear again, and then get the zip file and upload it here. EDIT: I did notice it looked like there was an oom error right before the shares went down.
-
As the title says, ever since the update to 7.0.1, my shares will disappear and I have to restart the server to get them back. I don't check my server often but noticed it when I tried to use Plex and it said Plex was offline. So I went to my docker which showed Plex was running. So then I try to access the movie directly through Windows network drive and the drive is offline. That's when I went to the shares tab and saw there were no shares. Did a google search and found if you restart the server the shares come back but that post said "It only happens one time after the update." Well, its happening more than one time to me. I've been checking my server daily and every single day my shares are gone again until I restart. What's going on? I know diag files will be needed. Do I just attach the whole zip file?
-
Do you perhaps have a link to a walk through for this? I currently download/rip to a "downloads" share. And then I move the files over to the appropriate folder in my plex media share. I'm looking for a way to automate this. So as things get downloaded into the downloads share, an app can automatically move it to the appropriate tv show/season folder. I have both Sonarr and Medusa installed currently but I have no clue how to set it up to do this. Everything I've found is to set them up to download things and then organize what they downloaded. Or to organize something a torrent app downloaded. I've searched for ways to auto move files and came up empty handed other than writing a script which wouldn't do exactly what I'm wanting (and I don't know how to program).
-
Thank you ConnerVT, I did read that on that page prior. But it seems the anonymized diagnostics still include things like IP addresses and such that I don't believe should be advertised for the world to see. I'm not a cyber security expert, though. Don't a lot of attacks start with someone figuring out what your IP address is? I have no qualms about posting up diagnostic files that don't have vulnerable info in them. Just let me know which ones are needed. It seems like I might have more issues than just the docker though. Rather than making multiple threads of each problem, I searched for an official support. I found a page for paid support that says I can get 1 on 1 support. But all of the dates are marked as unavailable? Am I doing something wrong to try and schedule this? Has anyone used the paid support before that can explain to me how it works and how I can get something scheduled in so I can get my server fixed please? I really don't mind paying for help.
-
Yes, I read the typical cause was an app writing to the docker.img instead of to a share. So I double checked that everything was mapped to a share (I have 6 containers total but only 2 are actually running). I also read that with plex containers (which this has been seeming like a plex issue from the start) its common that transcodes are writing to docker.img. That's when I found the entry in my syslog that I post and questioned if my transcoder is writing to docker.img and posted how my plex transcode directory is set up. I believe this is configured correctly. Please correct me if I am wrong. I also looked in my transcode share, saw no files, opened plex to play a video, went back to the transcode share and saw files populated. So I'm assuming it is in fact configured correctly. Since the 100GB I increased to previously was full, my server was running slow again. So that I may navigate the server quicker, I increased the size again (I may have gone overboard with this and increased it to 1000GB as it was easy to just add another 0 to the 100GB that was previously set). A new problem emerged after doing this. My CPU was very active even when nothing was going on. Many cores were constantly hitting 100% with the overall load sitting around 75%. The system ram also started filling up. I watched as it went from its normal 11% to 60% then 66%. I quickly navigated over to Tools->Processes and found that the line for /usr/bin/dockerd -p /var/run/dockerd.pid --log-opt max-size=50m --log-opt max-file=1 --log-level=fatal --storage-driver=btrfs was sitting at 25% CPU load and eating up the system ram. So I went to Settings->Docker and disabled docker. I went back to the dashboard and saw my CPU was now idling at 1% load and my system ram returned to normal at around 8% usage. Just to double check, I reenabled docker and sure enough, my CPU load skyrocketed and my system ram usage started climbing again. So I followed the very simple guide on this forum on how to create a new docker.img without losing container data (literally 2 steps. Delete the docker.img. Add containers using the templates.) While doing this I also set the docker size back to its default 20GB and rebooted the server. After all of this was done, I checked to make sure Plex was working by playing a movie. I also checked my dashboard and CPU load was normal as well as system ram usage. The docker memory is also sitting at 33% (6.37GB) and in the container size menu it is showing Plex is only using 346MB. When you say "attach the diagnostics" are you referring to the entire zip file? Isn't there sensitive info in there that shouldn't be uploaded to the internet for the world to have access to? Or is there a specific file in that zip file you need? If you need the entire zip file, could I send it to you privately? Or can I first be assured there is no sensitive info in that zip file that "hackers" could use? Please forgive my ignorance but I'm sure you can understand my caution as well.
-
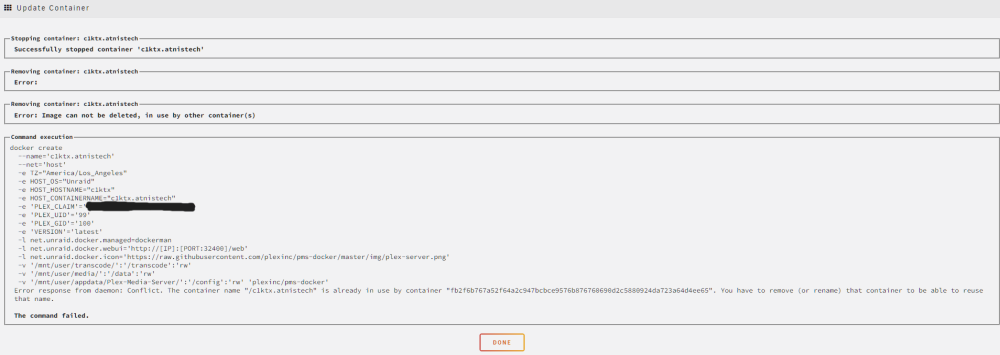
Clicking start container on the plex container would just come back with an error that the name was already taken. So I rebooted the whole server and on reboot the plex container is now running (I did not click start on the container after reboot. It started automatically.) According to the post by Squid, it seems a screen shot of the container on the docker tab is helpful? So I'm including it here. I'm also attaching the docker log file that I grabbed when I noticed the memory was full and the docker log file I grabbed just now after server reboot. If anything else is needed, I will happily learn how to get that info and provide it so please just let me know what you need. My Unraid server has been running since 2021 and I have made no changes to docker or the plex container that I know of for the docker memory to suddenly get full like this. I have done some googling and haven't found a solution either. docker 3-12-24 0822.txt docker 3-11-24 1749.txt

-
So I clicked on the orange dicker run link in your post. Read what Squid said about editing the container, change something, change it back and hit apply to get the docker run. I did that and now I can't get the plex container to start back up as the "edit" failed.
-
I figured out how to get the diagnostics zip file and opened up the logs. Found this line in the syslog file: Mar 11 02:12:13 c1ktx kernel: Out of memory: Killed process 3653 (Plex Transcoder) total-vm:28303584kB, anon-rss:28255104kB, file-rss:0kB, shmem-rss:0kB, UID:99 pgtables:55412kB oom_score_adj:0 Is the plex transcoder using the docker.img to store the transcode???? In the plex settings I have the transcoder temporary directory set to /transcode and in the docker I have: Container Path: /transcode Host Path: /mnt/user/transcode/
-
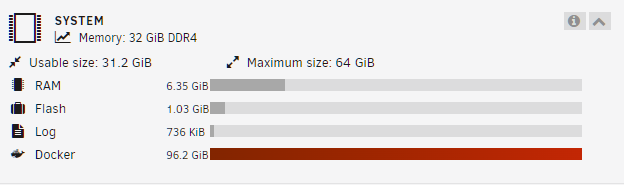
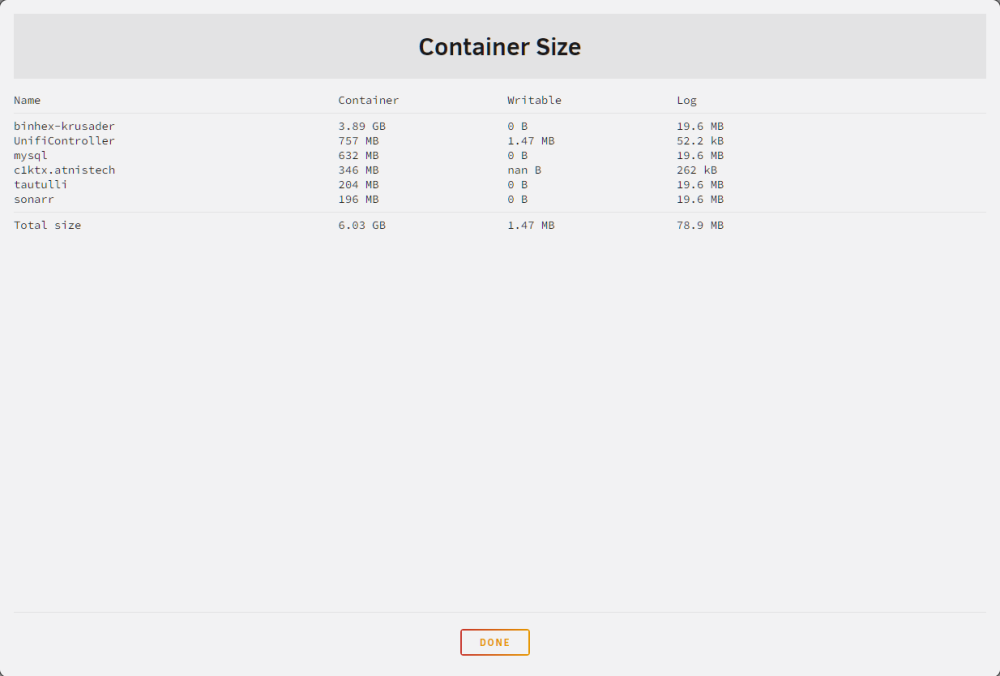
Well it's not longer saying Plex is using 7GB. It's now saying 346MB. I'll do the docker run thing as soon as I have a minute to read over what that is and how to do it. In the mean time, the issue of docker being completely full is back. But the docker container sizes don't equal the same as what the system memory says docker is using. Everything was fine for a little bit there up until last night. And then this morning it's suddenly filled all 100GB. Where should I look to figure out what happened? EDIT: The c1ktx.atnistech is plex.
-
Thank you for that. I didn't even realize that button was there. It says Plex is using the most space at 7.02GB for the container and 6.68GB for Writable. Container seems self explanatory but could you explain what Writable is please?




