jnk22
Members
-
Joined
-
Last visited
Everything posted by jnk22
-
This problem seems to be resolved now. @Jake404 A recent commit for `dvb_frontend.c` changed the line so that this warning/error gets logged only once instead of non-stop. Using the DigitalDevices driver should therefore be working again since the 6.1.43-Unraid release of this plugin. I can confirm that with the current version 6.1.49-Unraid this message gets only logged once now. For reference, it was this line that got spammed endlessly: Oct 2 10:33:45 SERVERNAME kernel: ddbridge 0000:01:00.0: Frontend requested software zigzag, but didn't set the frequency step size
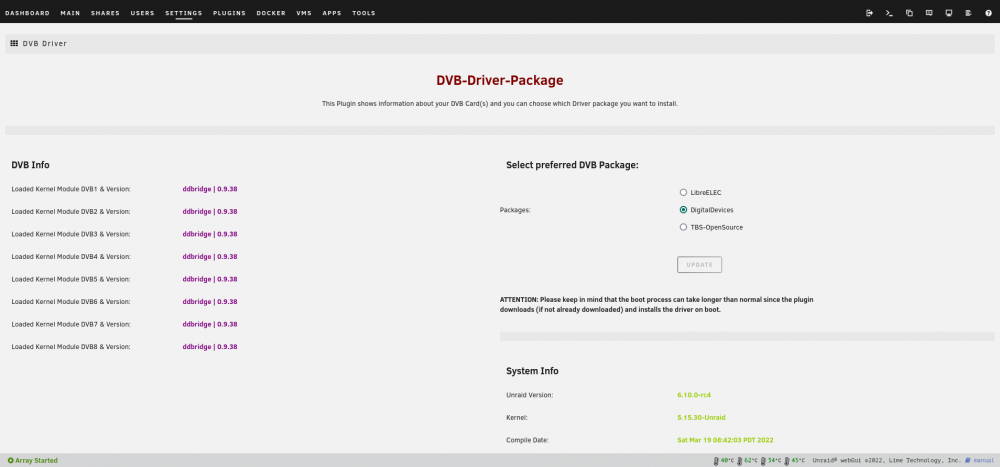
-
This is great to hear Although ofc I'd like to be able to use more recent drivers in the future again I'll definitely contact DigitalDevices in the next days, it would be awesome to get this fixed in an official way (if this is a bug on their side however). As soon as I got some news, I'll report back here. Thanks a lot for your help!
-
Ah, that makes sense ofc! I am using linuxserver/tvheadend - the container. With this line as Device input: /dev/dvb This has been working great from 6.8.3 through 6.9.2 until now. I have just installed the LibreElec driver (see attached screenshot). There is no error yet - and as the driver is 0.9.33 I am confident that there won't be any error outputs anymore 🥳 There is this one line that came up after starting a TV stream, but I don't think that this is related? Mar 21 12:03:45 Eutronik ntpd[1348]: kernel reports TIME_ERROR: 0x41: Clock Unsynchronized --- As a workaround this seems pretty good for now. But as I can't (and should not) rely on the LibreElec drivers not being updated, I guess I should report this somewhere else? Do you happen to know what is the best way to do that?
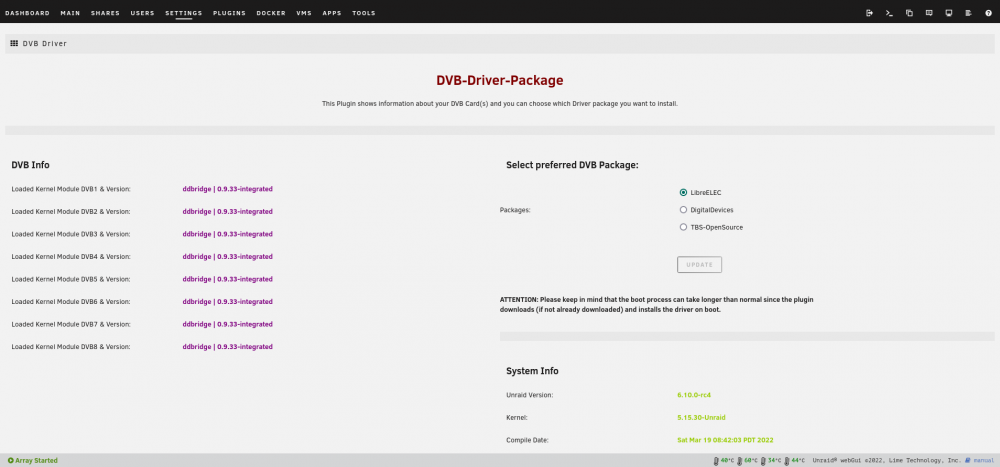
-
Thank you for your quick reply! Sure, my diagnostics are attached now Is it normal, that those mentioned lines will not be visible at the diagnostics/log/syslog.txt file? Mar 21 10:59:29 Eutronik kernel: ddbridge 0000:01:00.0: Frontend requested software zigzag, but didn't set the frequency step size Mar 21 10:59:30 Eutronik kernel: ddbridge 0000:01:00.0: Frontend requested software zigzag, but didn't set the frequency step size Mar 21 10:59:31 Eutronik kernel: ddbridge 0000:01:00.0: Frontend requested software zigzag, but didn't set the frequency step size Mar 21 10:59:32 Eutronik kernel: ddbridge 0000:01:00.0: Frontend requested software zigzag, but didn't set the frequency step size Mar 21 10:59:33 Eutronik kernel: ddbridge 0000:01:00.0: Frontend requested software zigzag, but didn't set the frequency step size Mar 21 10:59:34 Eutronik kernel: ddbridge 0000:01:00.0: Frontend requested software zigzag, but didn't set the frequency step size Mar 21 10:59:34 Eutronik kernel: ddbridge 0000:01:00.0: Frontend requested software zigzag, but didn't set the frequency step size Mar 21 10:59:35 Eutronik kernel: ddbridge 0000:01:00.0: Frontend requested software zigzag, but didn't set the frequency step size Mar 21 10:59:36 Eutronik kernel: ddbridge 0000:01:00.0: Frontend requested software zigzag, but didn't set the frequency step size Mar 21 10:59:37 Eutronik kernel: ddbridge 0000:01:00.0: Frontend requested software zigzag, but didn't set the frequency step size This is just a short extract from my current log, in case you are wondering as well why they are not visible in the syslog.txt as well. eutronik-diagnostics-20220321-1142.zip
-
Hi, I am having some problems with my Digital Devices cards since upgrading from 6.9.2 to 6.10-rc3/4. When starting a stream, my logs are getting spammed with this message: Mar 21 10:31:07 Eutronik kernel: ddbridge 0000:01:00.0: Frontend requested software zigzag, but didn't set the frequency step size I have both DVB-S2 and DVB-C2 cards installed, however last time it was when tuning on a DVB-C2 channel. Due to the frequent error logging, I have to restart every other day to prevent my log being filled up to 100%. I have waited for the 6.10-rc4 release, but that didn't solve this issue unfortunately 😐 --- I have done some research regarding this error message, this line has been added at 2022-01-14: https://github.com/DigitalDevices/dddvb/commit/b6d2a37ac21c6c49830dda085d0176cd9320395f (file: dvb-core/dvb_frontend.c) Checking your compile script for DD drivers, these seem to be included in your sources - as they are currently in the master branch. Is it possible to manually override the source with an older version of the dddvb drivers? e.g. with 0.9.38pre3 which doesn't have those lines included? There is also a thread in a mailing list: https://www.spinics.net/lists/kernel/msg3876756.html There is a line which includes dev_warn_once() instead of dev_warn(), as it is currently being used. I don't know if this would change anything though.. dmesg_2022-03-21_10-21.txt lspci-output_2022-03-21_10-21.txt
-
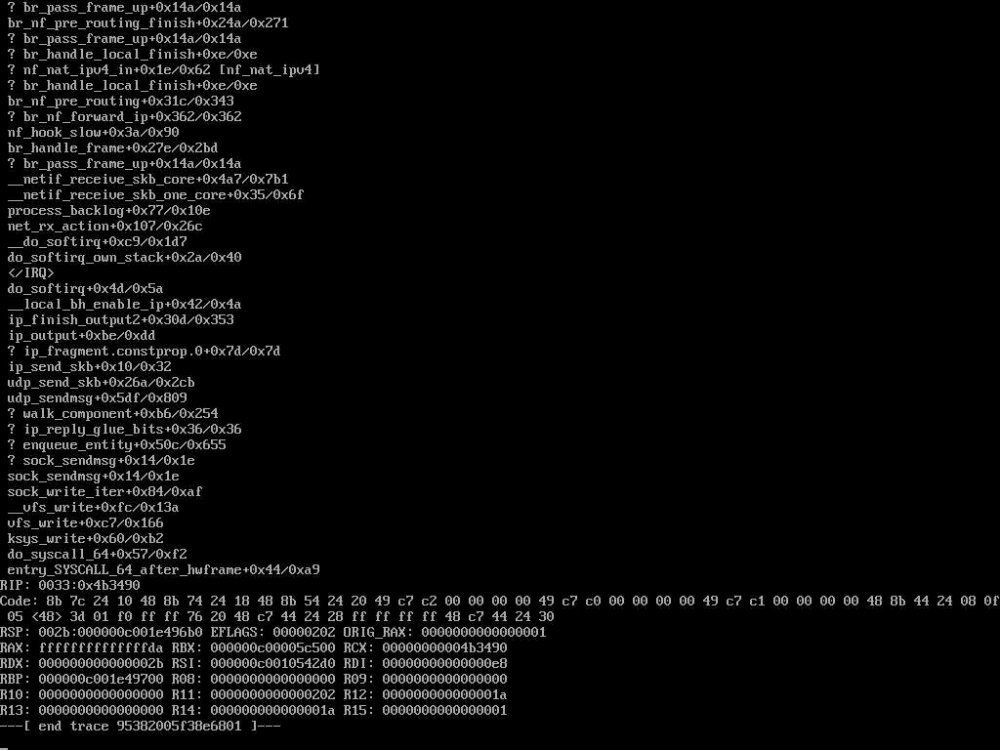
After 90+ days of uptime I can confirm that these changes seem to have solved my problem: - Settings -> Docker -> Host access to custom networks: Disabled - Use custom network "proxynet" for ALL docker instances (before: host + bridge + proxynet) - might be unrelated It is probably due to disabling host access to custom networks as stated here: Since then there is no call trace to be found in my logs anymore 🙂 I'll mark this thread as solved.
-
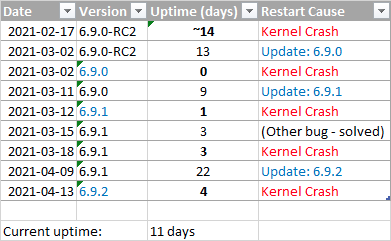
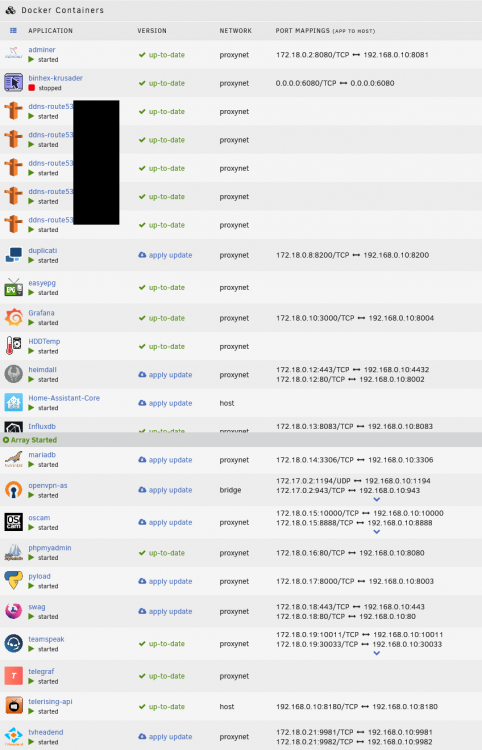
Unfortunately I still have those errors, so disabling IPv6 has not solved this error. The errors occured with all new versions: - 6.9.2 - 6.9.1 - 6.9.0 - 6.9.0-RCx - 6.8.3 This table shows that kernel crashes still appear regularly, with a longest uptime of 22 days (due to an update): It seems that more users are having those kind of crashes since ~6.9.x: I do not know if this thread is directly related to my problem, as most of those users seem to have their dockers running on "bridge" network only. My docker instances use these 3 network types: - bridge (only OpenVPN-AS - will try to replace this with WireGuard for now) - host (2x) - proxynet (21x - custom network, details attached as .txt file) As I probably cannot set up VLANs due to hardware limitations, I'll try to remove the bridge- and host-dockers by replacing them with alternatives for now to further narrow down the cause. I have attached a file with my docker-network settings and my Unraid network settings as well. latest_crash.txt docker-inspect-network-proxynet.txt
-
Hello, I have upgraded to 6.9.1 a few days ago and everything seemed to be working okay so far. However, I noticed that my 'memory log' was at 100% today. (This bar was red at 100%) I rebooted my server and since then I am facing errors regarding one of my array-disks: Mar 15 11:34:35 Server kernel: XFS (dm-2): Metadata corruption detected at xfs_dinode_verify+0xa3/0x581 [xfs], inode 0x3112d7016 dinode Mar 15 11:34:35 Server kernel: XFS (dm-2): Unmount and run xfs_repair Mar 15 11:34:35 Server kernel: XFS (dm-2): First 128 bytes of corrupted metadata buffer: Mar 15 11:34:35 Server kernel: 00000000: 49 4e 81 80 03 02 00 00 00 00 00 63 00 00 00 64 IN.........c...d Mar 15 11:34:35 Server kernel: 00000010: 00 00 00 01 00 00 00 00 00 00 00 00 00 00 00 00 ................ Mar 15 11:34:35 Server kernel: 00000020: 5e ab 64 67 25 cd 6b cc 60 4e 9b 47 00 29 29 3e ^.dg%.k.`N.G.))> Mar 15 11:34:35 Server kernel: 00000030: 60 4e 9b 47 00 29 29 3e 00 00 00 00 02 cc a0 00 `N.G.))>........ Mar 15 11:34:35 Server kernel: 00000040: 00 00 00 00 00 00 2c ca 00 00 00 00 00 00 00 01 ......,......... Mar 15 11:34:35 Server kernel: 00000050: 00 00 00 02 00 00 00 00 00 00 00 00 2d 32 ff fb ............-2.. Mar 15 11:34:35 Server kernel: 00000060: ff ff ff ff aa 5c ad 41 00 00 00 00 00 00 00 5a .....\.A.......Z Mar 15 11:34:35 Server kernel: 00000070: 00 00 00 14 00 3e c7 7f 00 00 00 00 00 00 00 00 .....>.......... If I understand it correctly, this means the affected disk is 'disk3'. That is where the appdata and docker files + other shares are currently located at. I don't know if this is related to 6.9.1 or that memory log problem at all. However, those XFS metadata corruption errors started showing right after the restart which at least solved the memory log at 100% error.. How can I repair those corrupted metadata files properly? I have not yet restarted the server after those errors came up. --- I have attached the newest diagnostics and a full /flash/logs/syslog file. The diagnostics file only shows the current errors related to 'metadata corruption detected...', the other syslog shows: Mar 13 - 'BTRFS critical (device loop2): corrupt leaf: ...' error (lines 30029 - 30653) Mar 15 - /var/log/syslog spam (lines 30715 - 41391) Mar 15 - xfs metadata corruption (lines 44133 - 54109) Feb 17, Mar 2, Mar 12 - various kernel panics which seem to be related to my previous problem regarding macvlan(?) kernel panics (lines 3184 - 7121, 16962+, 29687+) (As this is probably/hopefully not related to my new problem, I'll keep using the other thread for the network-related errors though.) edit: uploaded missing diagnostics/syslog files Thanks in advance, jnk server-diagnostics-20210315-1826.zip syslog_02-17_03-15.zip
-
It seems that I finally have some good news about those crashes Yes, I have looked up the recommended slots for 2 and 4 modules and always placed them in that way. There is no overclocking enabled as you are totally right about the stability aspect as well. --- I have updated to the latest version 6.9.0-RC1 when it was released, but that did not solve it (so it was not solved by the new kernel - which I hoped would fix it). After that I have done the following, which seems to have solved it: - Upgrade to 6.9.0-RC2 - Disabled IPv6 network for Unraid completely Since then, the server is up and running for 37+ days and no error at the logs at all. (maximum was ~15 days before) I did not restart the server since then, so I hope that it will stay the same for the next (RC3?) release. I believe it is the IPv6 setting that does not make it crash anymore. It might be due to some misconfiguration on my home network - or some Unraid related problem with the Unraid network settings in general. I have also found a topic about a similar problem: - https://forums.unraid.net/topic/70529-650-call-traces-when-assigning-ip-to-dockers/ It seems to be solved by using multiple NICs / setting up VLANs etc.: - https://forums.unraid.net/topic/62107-network-isolation-in-unraid-64/?tab=comments#comment-609082&searchlight=1 As the current state (disabling IPv6 completely) is not what I want, I'll try those solutions in the future. However, my network does not really support VLANs due to my current hardware (FRITZ!Box router). I'll report back as soon as I have done some more testing on those IPv6 and general network-related settings.
-
Yea, unfortunately it was not Pi-hole 😅 To rule out the linuxserver.io DVB kernel (and also to test your awesome new docker) I have built a custom kernel with DVB and NVIDIA support today. Worked like a charm! I have also temporarily removed the memory modules (slot 1+2) that I had initially installed. As I have checked the amount of times the server started (which most of the time was due to crashes..) before and after I inserted the 2 additional modules, I realized that the amount of starts/crashes before were about every ~2nd day (for 30 days), after the installation about 4,5 days per crash (for 150 days).. Which could lead to the assumption that I reduced the probability of a crashes by 2 with double the amount of modules. 🤔 If that won't work I'll try a stock Unraid version as next step. Will keep you updated
-
Thanks for your help! @ich777 Yes, it's the linuxserver.io build for my Digital Devices TV cards. But I have already seen your awesome new plugin, and that is what I'll be using for Unraid 6.9.0 for sure I managed to move my Pi-hole instance to an old Raspberry Pi 2. I feel like the Pi-hole docker could have been the reason for the crashes as well. If the server is going to crash again in a few days though, I'll test a stock installation of Unraid in safe-mode without Docker/VM. I'll keep you updated. jnk22
-
Hello, I am having a problem with regular crashes of my Unraid server. Those crashes usually happen after 1 - 10 days of runtime. I have attached 13 screenshots of the last screen that I took using my mainboard's remote control via webinterface. About 80% crashes happend during 02:00 AM and 09:00 AM, when nothing much happened at that time. Sometimes they occured during active usage of the server as well though. In the last ~6 months I have probably had a total amount of ~30 crashes of that kind. Unfortunately I did not have time to address them properly until now. I ruled out a few things already: corrupt appdata on a BTRFS cache drive (running array without any cache drive -> crashes remain) OpenVPN AS Docker: disabled for a few weeks, same crashes My system Unraid 6.8.3 (Unraid DVB Edition) Mainboard: Supermicro X11SPi-TF CPU: Intel Xeon Silver 4210 RAM: 4x 32GB Samsung M393A4K40CB1-CRC DDR4-2400 regECC DIMM CL17 Single (not tested with memtest before installing Unraid) GPU: 2x INNO3D GeForce GTX 1650 Single Slot Cache drive: 1000GB Samsung 970 Evo Plus M.2 2280 PCIe 3.0 HDDs (Array): 4x WD 8TB Red I bought most of the hardware as completely new hardware back in March/April this year (except for some of the HDDs which I have had already). I have then extended the server with 2 more RAM sticks and 2 graphics cards in ~May. The problems have been happening before that already, with the 2 starting memory modules I have had installed. My mainboard has 2 network ports, currently being used in bonding mode. I have used one of those ports in single mode before, but the same crashes have happened back then. I have attached some diagnostics files when the server was active. Unfortunately I could not get those diagnostics files after a crash. However, some of those diagnostics logs seem to have the same kind of errors as well. I also managed to log a "crash" when it seemed to actively happen, but only through copying the logs itself from the webinterface console, as I could not download any diagnostics through the webinterface itself at that point anymore: kernel_error_2020-09-07.txt Could these crashes by related to bad RAM? As those RAM modules are regECC-modules, I would have expected those kind of errors to look different though - but I have never used any regECC-RAM before. I am also using Pi-hole docker. As those errors usually contain something about "NAT" and IPv4/6, could this be the cause as well? Disabling Pi-hole for weeks would not be that easy though as I am using its DNS services for DNS resolution of my TV server and other important services as well.. Thanks in advance jnk diagnostics.zip screenshots.zip