




potjoe
Members
-
Joined
-
Last visited
Everything posted by potjoe
-
Hello @binhex . I've been using this container for years with openVPN and PIA with no issues at all. Recently, I switched to wiregard, and I updated the container because the template was not up to date anymore. In a nutshell, I had to switch network type from bridge to br0 and assign an ip, and I now feel a bit nervous because my true ip address may appear in Qbittorent WebUi... XXX.XXX.XXX.XXX How is it possible, and is there a risk for a leak using br0 as a network interface ? Edit: Forgot to mention, I switched to br0 because I could not get wiregard working. In bridge mode, the container is stuck at [info] Trying to connect to the PIA WireGuard API on 'nl-amsterdam.privacy.network'... and webUI is never accessible.
-
Hello there! First time for me, a drive seems to be slowly failing. A week ago, I had 3 read erros (Reported uncorrect), I decided to wait and see. Yesterday, received a notification of 8 reallocated sectors count, so I thought it is time to replace the drive (is it ?). My current array is made of : 3 TB Parity drive (healthy) 3 TB Data drive (healthy) 3 TB Data drive (failing) 1 TB Data drive (healthy) I found a 4TB drive as a replacement, but it is larger than my current parity drive. How to handle the disk replacement going forward ? Thank you for your help. monalisa-diagnostics-20260202-1508.zip
-
Thank you for your help, I will try these different steps and keep you updated (change ports then format). It is now connected directly to the internal USB 2.0 header with an adapter, I'll first try to reseat it / then change it. I do have a quite recent backup thanks to unraid connect.
-
I managed to bypass the broken menu and to go directly to the Url of diagnose page, it worked. Here is the diagnostic. Sorry for the time lost monalisa-diagnostics-20240327-1924.zip
-
root@MonaLisa:~# df -h Filesystem Size Used Avail Use% Mounted on rootfs 7.7G 1.7G 6.1G 22% / tmpfs 32M 1.9M 31M 6% /run /dev/sda1 29G 754M 29G 3% /boot overlay 7.7G 1.7G 6.1G 22% /lib/firmware overlay 7.7G 1.7G 6.1G 22% /lib/modules devtmpfs 8.0M 0 8.0M 0% /dev tmpfs 7.8G 0 7.8G 0% /dev/shm cgroup_root 8.0M 0 8.0M 0% /sys/fs/cgroup tmpfs 128M 100M 29M 78% /var/log tmpfs 1.0M 0 1.0M 0% /mnt/disks tmpfs 1.0M 0 1.0M 0% /mnt/remotes tmpfs 1.0M 0 1.0M 0% /mnt/addons tmpfs 1.0M 0 1.0M 0% /mnt/rootshare /dev/md1 2.8T 2.6T 172G 94% /mnt/disk1 /dev/md2 2.8T 2.6T 179G 94% /mnt/disk2 /dev/md3 932G 714G 218G 77% /mnt/disk3 /dev/sdf1 466G 137G 329G 30% /mnt/cache /dev/sdg1 239G 43G 197G 18% /mnt/cache_nvme shfs 6.4T 5.9T 568G 92% /mnt/user0 shfs 6.4T 5.9T 568G 92% /mnt/user /dev/loop2 40G 20G 20G 51% /var/lib/docker tmpfs 7.8G 324M 7.5G 5% /var/lib/docker/containers /dev/loop3 1.0G 4.4M 905M 1% /etc/libvirt Here it is. Thank you for your help!
-
Hi all, Accessing the Web UI, I noticed today some big troubles in my server. I do not live in the same location, so I don't know when it started. The webUI is off, displaying failed to open stream everywhere, most of options and pages are unavailable (I cannot access diagnostic or logs through UI). The USB key seems to be blacklisted OR offline, but I wanted to post here before attempting a reboot or anything. Here are some screenshots. Could you provide me with instructions to diagnose / fix its current state ? I've been running unraid for years without any issue.
.thumb.png.67400f458fc5aabf4a4fbdcc29c75fa3.png)
.thumb.png.e365d41aa8b0df607d34e3e8b60a096e.png)
.thumb.png.d2892fc840f3b84ea9fd07277e56109f.png)
.thumb.png.63a9f9d750a22c7077e86b18a957d3c4.png)
.thumb.png.e01760895728af4dcc610550c3d7f142.png)
-
Hi, For many months, I've had an issue with my server having 100% CPU load that I've been unable to troubleshoot since it begun, and this is why I'm finally posting here. Netdata reports high iowait when these spikes are happening. Bios is up to date, File integrity is not used in the system. I've removed every unused docker, reduced my ram usage by 10%, and still, it is happening again, but less often (it was every fifteen minutes, now it's once a day). I've tried many times tracing it down with iotop / htop, but I have not been able to find the culprit. When it happens, I noticed that cache drive read speed is really high (more than 300 mb/s). I hope someone can help me figure it out, thank you for your time. Diagnostic file : monalisa-diagnostics-20230319-0933.zip
-
This unraid template should be revised, as well as the configuration.py default file. Noticed issues : When initializing the container for the first time, there is an error l. 246 in configuration.py. A "}" at the end of the line is causing an error. It conflicts with REMOTE_AUTH_DEFAULT_PERMISSIONS default value, this character should not be already there. Most default values for Environment Variables are incorrectly set. Currently, variables values are set to be the ENV variable name by default, which is causing a lot of errors during initialization. Indeed, since configuration.py is written when the container is started for the first time, having wrong values does not prevent the container to start and result in a config file with many errors, which has to be corrected later on. Instead, ENV var that are required to be set by user should be empty to prevent the container to start if not set. According to https://docs.linuxserver.io/images/docker-netbox, default values should be set as follow : SUPERUSER_EMAIL* : SUPERUSER_EMAIL 'empty' SUPERUSER_PASSWORD*: SUPERUSER_PASSWORD 'empty' ALLOWED_HOST*: ALLOWED_HOST 'empty' DB_NAME*: DB_NAME netbox DB_USER*: DB_USER 'empty' DB_PASSWORD* : DB_PASSWORD 'empty' DB_HOST*: DB_HOST postgres DB_PORT*: DB_PORT 5432 REDIS_HOST*: REDIS_HOST redis REDIS_PORT*: REDIS_PORT 6379 REDIS_PASSWORD: REDIS_PASSWORD 'empty' REDIS_DB_TASK*: REDIS_DB_TASK 0 REDIS_DB_CACHE*: REDIS_DB_CACHE 1 BASE_PATH: BASE_PATH 'empty' REMOTE_AUTH_ENABLED: REMOTE_AUTH_ENABLED False REMOTE_AUTH_BACKEND: REMOTE_AUTH_BACKEND netbox.authentication.RemoteUserBackend REMOTE_AUTH_HEADER: REMOTE_AUTH_HEADER HTTP_REMOTE_USER REMOTE_AUTH_AUTO_CREATE_USER: REMOTE_AUTH_AUTO_CREATE_USER False REMOTE_AUTH_DEFAULT_GROUPS: REMOTE_AUTH_DEFAULT_GROUPS [] REMOTE_AUTH_DEFAULT_PERMISSIONS: REMOTE_AUTH_DEFAULT_PERMISSIONS {} Currently, REDIS_PASSWORD ENV var is 'required' in the template. It should not, since it is optionnal. As a general concern, changes in the UI does not reflect on the configuration file, since it is only written the first time the container start. Isn't there a way to pass Environnement variable to the config after it has been created ?
-
@mjeshurun I'm not familiar with the issue, did you had a look on nextcloud help forum or nextcloudpi GitHub? You can still configure nextcloudpi from a terminal. Open Unraid console and enter docker exec -it nextcloudpi ncp-config it'll open an editor to configure it the same way you would in the webUI.
-
Regarding imagick, it has been removed from the container for security reasons. See here https://github.com/nextcloud/nextcloudpi/issues/1159 Regarding OPcache configuration, you can ignore the warning : https://help.nextcloud.com/t/nextcloud-23-02-opcache-interned-strings-buffer/134007/5
-
Do you mean Nextcloud's Dashboard or Nextcloudpi's Web administration panel on port 4443 ? Maintenance mode can be disabled through the second one.
-
Hi @jiyang1018, I've encountered the same issue yesterday, after investigation I was not able to find the root of the issue. In my case, ncp admin panel was also unavailable. However, I have successfully restored data and config after a fresh install, with my last backup available. Do you have such a backup ?
-
Not considering myself knowledgeable, though I hope I can help! I've been using NCP for almost two years now, and it is a really neat all-in-one solution. Some pros : integrated let's encrypt cert automation, auto update, good enough performance from scratch (though some tweaks are welcome, as well as removing undesired apps), possibility to schedule backup in archive for data and config. Some cons : performance is not optimal, sometimes maintenance mode is still on after an update, unraid shares must be mounted as external storages and cannot be used as nextcloud "data" root directory, not on razor's edge version of nextcloud. Overall, it is a good container. The Linuxserver version is also really good : BUT, you'll have to setup a database, a redis server eventually, and maintain it yourself, if you want backups, update, etc. However, direct mount of a share seemed to be a little bit easier. But you can expect overall better performance if you adjust core settings. I guess it depends on your taste for tinkering and having the most update version of nextcloud available. If you're coming from nextcloudpi, I guess you already made your choice some years ago! Moreover, It may be possible to "backup" your current config from NCP web panel and to import it directly in your new ncp docker, through the "restore" function in the same panel.
-
Hi @Jonny Redd, have you been able to troubleshoot your issue ? I'm encountering a similar behaviour, meaning some random lock of the server with nothing useful in the syslog
-
Thanks @mgutt! Actually there is no sign of the restart because I copied the lines from the syslog server local record (That I enabled from Unraid settings to be stored in appdata). In this log, we can see the last record before the lock : Dec 25 15:30:01 MonaLisa docker: RAM-Disk synced I think the first lines "<date> xxx kernel: Linux version 123456-Unraid" are missing because rsyslogd had not started yet. I confirm that I had to reset the server and that it restarted : here is a new Diagnostic file with the full logs this time. Edit : in the logs from the diagnostic archive, we can see that the server restarted : Dec 25 15:57:17 MonaLisa kernel: Linux version 5.10.28-Unraid (root@Develop) (gcc (GCC) 9.3.0, GNU ld version 2.33.1-slack15) #1 SMP Wed Apr 7 08:23:18 PDT 2021
-
Hi! After two weeks without issue, my server went unresponsive again this afternoon depite last time's BIOS changes. Weeks ago I enabled the syslog server to see if something was relevant in the last minutes preceding the bug. As you can see the last activity reported before the crash today (it happened somewhen between 15:30 and 15:59, time of hard reset when I had to hard reset again...), was the RAM-Disk synced : Dec 25 14:07:56 MonaLisa dhcpcd[1909]: br0: Router Advertisement from fe80:**************:c8c Dec 25 14:08:01 MonaLisa dhcpcd[1909]: br0: Router Advertisement from fe80::**************:c8c Dec 25 14:17:29 MonaLisa dhcpcd[1909]: br0: part of a Router Advertisement expired Dec 25 14:17:29 MonaLisa dnsmasq[26780]: reading /etc/resolv.conf Dec 25 14:17:29 MonaLisa dnsmasq[26780]: using nameserver 192.168.10.254#53 Dec 25 14:17:29 MonaLisa dnsmasq[26780]: using nameserver 2a01:**************1#53 Dec 25 14:17:29 MonaLisa dnsmasq[26780]: reading /etc/resolv.conf Dec 25 14:17:29 MonaLisa dnsmasq[26780]: using nameserver 192.168.10.254#53 Dec 25 14:17:29 MonaLisa dnsmasq[26780]: using nameserver 2a01:**************#53 Dec 25 14:30:01 MonaLisa docker: RAM-Disk synced Dec 25 15:00:01 MonaLisa docker: RAM-Disk synced Dec 25 15:17:50 MonaLisa dhcpcd[1909]: br0: Router Advertisement from fe80::**************:c8c Dec 25 15:17:58 MonaLisa dhcpcd[1909]: br0: Router Advertisement from fe80::**************:c8c Dec 25 15:30:01 MonaLisa docker: RAM-Disk synced Dec 25 15:59:58 MonaLisa kernel: mdcmd (36): set md_write_method 1 Dec 25 15:59:58 MonaLisa kernel: Dec 25 15:59:58 MonaLisa cache_dirs: Arguments=-p 1 -u -e Backup -e Enregistrements -e appdata -e domains -e isos -e system -l off Dec 25 15:59:58 MonaLisa cache_dirs: Max Scan Secs=10, Min Scan Secs=1 This process is due to the tweak proposed by mgutt in this thread to avoid wearing out SSD's : I'm not sure at all it is related to the issue I'm having, just mentionning it. I don't have any clue on why I'm having these frequent locks of the server. Thank you very much for your time!
-
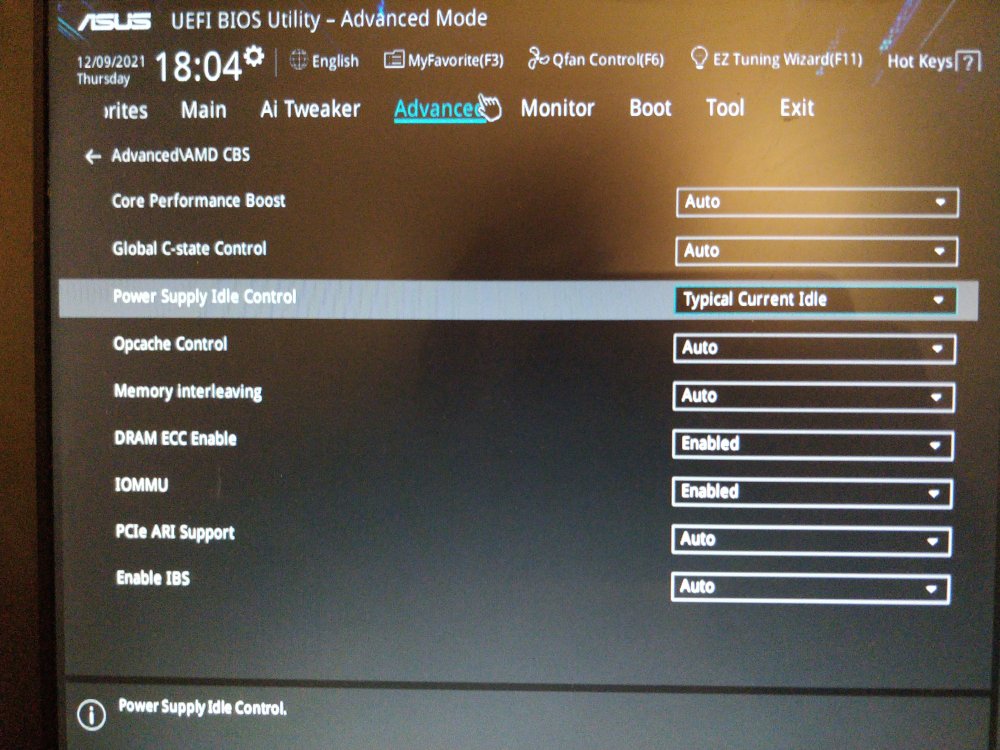
Hi! So I finally had the time to check bios settings tonight. My memories were correct : when I set up the server a year ago, I disabled Global C-state control but did not touched Power Supply Idle Control. I adjusted them according to the recommendations : Power Supply Idle Control set to "Typical Current Idle" and re-enabled Global C-state control (set to auto). The situation where Unraid became unresponsive only started two months ago or so. I'm not familiar with the options you mentionned, thus I don't know if this was the source of the issue. Current settings :
-
Thank you. I'll double check when at home, I'm almost sure to have follow instructions this page regarding ryzen cpus when I set up the server last year. Not sure about power supply idle control, but I remember disabling global C-State control. I've never experienced such behaviour in roughly a year and a half.
-
Hi, For some time now, I've observed more and more often situations where my server became totally unresponsive : no Web UI, no VM running (no pfsense thus, but it's another story), no SSH connections, server not responding to ping. I noticed that when it happens power consumption raises by 50-70 % if the UPS is to be trusted. I usually try a quick press of power button, but it's not rebooting the server. I am forced to break the first rule and to force shutdown by pressing the reset button and force an unclean shutdown. The issue is that I'm running headless without GPU installed, and the Ryzen 1600 CPU I'm using does not support video output. Thus, I can't plug a monitor when the issue occurs. I've run a diagnostic after the reboot, but if I'm not mistaken it won't provide any useful information right ? I'm including it anyway, just in case. This is the fourth time in two months it's happening, and I'm really out of ideas. Any help to troubleshoot the issue would be really great. Thank you for your time. P.s. : the pfsense being down when it happens, I plug in directly into the switch with a manual IP assignment to test connections. Since Unraid has a fixed IP, it should respond anyway.
-
Hi! For the fourth time this month, I'm having an issue with this container resulting with an unresponsive server, forcing me to do an unclean shutdown (no WebUI, no SSH). I'm using CA auto-update and CA appdata backup plugins. When they shutdown the docker before performing backup/update at scheduled time, I assume qbittorrent docker failed to properly shutdown before the expiration of the delay (10 seconds by default) from the plugins, and it results being killed. At restart, (this, I know for a fact) qbittorrent config has been lost, and it starts moving all torrents to /config/download simultaneously, which results, I think, in an out of memory error, affecting the whole server. Last time it happened, I tried to bump up the expiration delays up to 60 seconds, but this morning it happened again. I'd be really grateful to get some help sorting this out : is someone encountering a similar issue ? How can I diagnose why the docker failed to shutdown (if this is the issue) ? Is there a way to prevent a config override ? For now, I disabled auto-update and backup for this particular docker, and excluded it from the list of docker to stop before backup, but I'd ideally like to use these features.
-
Thanks for the clarifications. Indeed, I was confused by the wording, since I thought the Remote Access was performed by the intermediary of Unraid's official servers acting as a proxy, and not with a DNS entry as it is actually. Sorry for that! Sure, I'm glad to know it's is looked at! Thanks again.
-
Hi! I thought about enabling Remote Access through My Servers for some time, but to me it still seems too embarassing to expose the server with an one factor authentication, no matter how strong root password is. Thus, I had two questions to address to the (amazing) unraid team : - In a short term / mid-term perspective, would it be possible to disclose the ip ranges used by My Servers API to remote access into servers ? This would allow for instance to restrict at a firewall level what IPs can or cannot access to the server, and thus restrict it to Unraid's official servers. Many major services which rely on WAN port forwarding, such as Plex, or Cloudflare, publicly disclose their Ip Ranges specifically for that purpose (see here or here). - In a Mid-term / long-term perspective, have some other implementations of remote access login already been thought of ? 2FA, Key authentication, it's an open debate... For now, I'm still worried to think that it relies on a single factor, password authentication, and this is why I was wondering if something had been thought / was worked out / was coming soon regarding the security of remote access through My Servers. As always, thank for the hard work put into this great piece of software.
-
Hi! MySQL service is part of the image. Open a console from within the container (in unraid GUI, click on the container, then console). Once opened, you can check MySQL logs in /var/log/MySQL/error.log. This should give you some indications on what's going on. You can also try to rebuild the container, not only restart it. Easiest way : edit the container, change any value and revert the change, click apply.
-
Merci @ChatNoir et @PicPoc pour ces informations / le temps passé à réaliser les tests. Effectivement, cet échange était très instructif au regard des subtilités d'unraid.
-
Je suis de près la conversation car cela vient de se produire chez un utilisateur de reddit. Essayant de l'aider, il m'a pourtant semblé qu'il avait bien suivi la procédure, et j'ai du mal à voir là où il a pu se tromper. C'est le genre de choses qu'on aime à connaître avant le jour J (je touche du bois). Si je comprends bien, en cas de disque défaillant, aucun formatage du disque de remplacement n'est requis avant de l'assigner à la place de l'ancien dans l'array ? Pour les curieux, voici le lien du cas en question.

.png.39162ca4e7566318da2b77245d6fd563.png)
.png.6dd8a36c82f3c0523d948ef28d57e99b.png)
.png.4b08bb90295a65fcdcc746c713f00234.png)
.png.1357e92bdba20919e42cfe5081f40f79.png)
.png.5156a1e850877a7af99ff23d97690f9d.png)

