




Alexstrasza
Members
-
Joined
-
Last visited
Everything posted by Alexstrasza
-
Aha! By creating a 'sacrificial' pool on a spare drive all of the other shares appeared in the share config properly. Thanks for pointing me in the right direction and fingers crossed for full integration with the UI soon !
-
To add to this, at the moment there's no way to use shares (which is a rather major feature of a NAS ) with a native encrypted ZFS pool because even though you can manually load the key, there is no way to tell Unraid that the share is now unlocked, so it still thinks it's an "Unmountable: wrong or no file system". The good news is that everything is working fully in Unraid, other than emphttpd is not calling zfs load-key <pool name> on startup with a user provided password or a key file, (you can see in the logs all of the mount process working fine until it exits because the key isn't loaded) so I'm hopeful that Lime can add this in quite easily in a future update by reusing the UI system already present for encrypted LUKS systems and just calling the command. Calling the command manually makes everything work and mount fine, but then Unraid still doesn't let you make shares because it didn't do it itself during array start. Apr 7 21:25:41 Sybil emhttpd: errors: No known data errors Apr 7 21:25:41 Sybil emhttpd: shcmd (246): /usr/sbin/zfs set -u mountpoint=/mnt/main main Apr 7 21:25:41 Sybil emhttpd: shcmd (247): /usr/sbin/zfs mount -o atime=off main Apr 7 21:25:41 Sybil root: cannot mount 'main': encryption key not loaded Apr 7 21:25:41 Sybil emhttpd: shcmd (247): exit status: 1 Apr 7 21:25:41 Sybil emhttpd: shcmd (248): /usr/sbin/zpool export -f main Apr 7 21:25:41 Sybil emhttpd: shcmd (249): rmdir /mnt/main Apr 7 21:25:41 Sybil emhttpd: main: mount error: wrong or no file system @andrebrait - Just to confirm, you don't have any SMB shares working for the pool either do you? I'd settle with a hacky solution for the time being but I haven't been able to find a way to use the native share system while emhttpd isn't trying to load the key itself.


-
I'm also observing this issue in Microsoft Edge. Does anyone see anything off with my XML?
-
<?xml version="1.0"?> <Container version="2"> <Name>Storj</Name> <Repository>storjlabs/storagenode:beta</Repository> <Registry/> <Network>bridge</Network> <MyIP/> <Shell>sh</Shell> <Privileged>false</Privileged> <Support/> <Project>https://documentation.storj.io/</Project> <Overview>This is official Storj V3 node client. To participate you must first have to have an authorization token, to get the Authentication Token go to: https://storj.io/sign-up-farmer
 
 This template is for running the Docker application only, please follow Storj Lab directions to generate your Node Identity files - this is in https://documentation.storj.io/dependencies/identity
 
 
 
 !!! IMPORTANT !!!
 
 Two path need to be passed to the docker. Currently Storj requires that the path are mounted using --mount rather than -v. Please add the path for the storage and identity folders to the extra parameters in the following format (extra parameters can be accessed through the advanced view toggle):
 
 --mount type=bind,source="/mnt/user/appdata//storj/identity/storagenode/",destination=/app/identity --mount type=bind,source="/mnt/user//",destination=/app/config
 
 During the first run the -e SETUP=true argument needs to be added to this string to create the required folders. After the first run when container is created restart it and delete the -e SETUP=true argument.
 
 For additional information please visit the support thread: https://forums.unraid.net/topic/88430-support-storj-v3-docker/
 </Overview> <Category>Cloud: Crypto: Other: Status:Stable</Category> <WebUI>http://[IP]:[PORT:14002]/</WebUI> <TemplateURL>https://raw.githubusercontent.com/dalekseevs/Unraid-Docker-Templates/master/stroragenode-v3.xml</TemplateURL> <Icon>https://raw.githubusercontent.com/dalekseevs/Unraid-Docker-Templates/master/logos/storj-logo-png-transparent.png</Icon> <ExtraParams/> <PostArgs/> <CPUset/> <DateInstalled>1654110094</DateInstalled> <DonateText/> <DonateLink/> <Requires/> <Config Name="TCP Port" Target="28967" Default="28967" Mode="tcp" Description="Default Storj V3 node port." Type="Port" Display="always" Required="true" Mask="false">57658</Config> <Config Name="Dashboard Port" Target="14002" Default="14002" Mode="tcp" Description="The port to access web dashboard" Type="Port" Display="always" Required="true" Mask="false">14002</Config> <Config Name="Email address" Target="EMAIL" Default="" Mode="" Description="Email address used to sign Storj V3 node. (recommended)" Type="Variable" Display="always" Required="true" Mask="false"></Config> <Config Name="Wallet Address" Target="WALLET" Default="" Mode="" Description="Your Payout address here." Type="Variable" Display="always" Required="true" Mask="false"></Config> <Config Name="Allocated Storage" Target="STORAGE" Default="2TB" Mode="" Description="A minimum of 500GB with no maximum of available space per node. Preferred minimum of 8TB and maximum of 24TB of available space per node." Type="Variable" Display="always" Required="true" Mask="false">32TB</Config> <Config Name="Identity directory" Target="/app/identity" Default="" Mode="rw" Description="" Type="Path" Display="always" Required="false" Mask="false">/mnt/user/appdata/Storj/identity/storagenode/</Config> <Config Name="Storage location" Target="/app/config" Default="" Mode="rw" Description="Storj database location" Type="Path" Display="always" Required="false" Mask="false">/mnt/user/Storj/</Config> <Config Name="Internet Address" Target="ADDRESS" Default="domain.ddns.net:28967" Mode="" Description="Your ISP IP address:28967 (static IP) or dynamic DNS address here." Type="Variable" Display="always" Required="true" Mask="false"></Config> <Config Name="TCP Port" Target="28967" Default="28967" Mode="udp" Description="QUIC Port" Type="Port" Display="always" Required="true" Mask="false">57658</Config> <Config Name="Bandwidth" Target="BANDWIDTH" Default="" Mode="" Description="(OPTIONAL) Amount of bandwidth used, per month, to Storj network. According to Storj documentation, minimum is 2TB, recommended is 16+ TB, preferred is unlimited (e.g. 100000TB)." Type="Variable" Display="advanced" Required="false" Mask="false">45TB</Config> </Container> I removed two personal values
-
Hmm, if I inspect the actual link itself is it supposed to be literally the [IP]:[PORT] syntax?
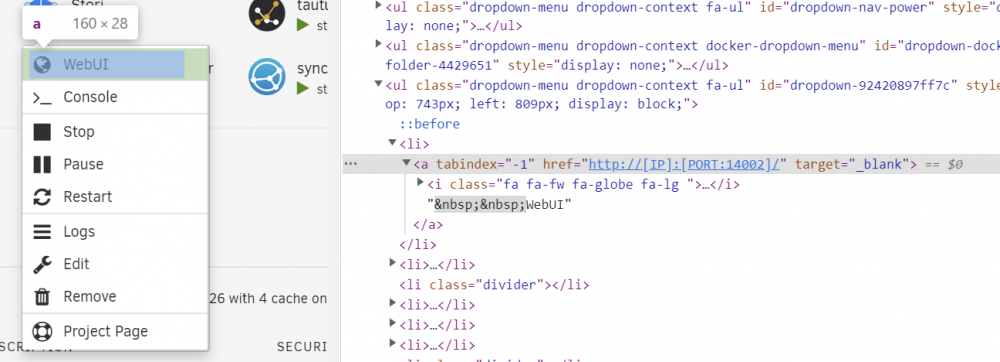
-
Hmm, that's so strange. I tried earlier in Incognito and I just tried as well in --disable-extensions mode (which completely disables extensions) and it still does the about:blank#blocked thing. It doesn't seem to, and I manually enabled popups as well because I heard that might be an issue.
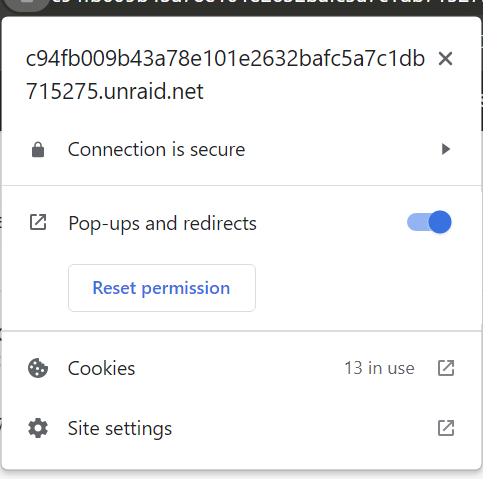
-
Hi all, Recently I've started noticing that all of my Docker WebUI links open a new window to about:blank#blocked rather than their destination. I've checked and the links themselves seem fine (e.g. http://[IP]:[PORT:14002]/) and I've also tested with no extensions and no AV other than Windows Defender. I'm wondering if this is perhaps an upcoming security change in Chrome Dev? (I'm running Chrome Dev Version 105.0.5148.2 (Official Build) dev (64-bit)) Has anyone else observed this behavior?
-
Issue now filed upstream at https://github.com/netdata/netdata/issues/12413. Thanks for the additional confirmation @Agent531C.
-
The latest version of this container seems to have some kind of runaway disk-write bug. Some kind of chart temp file? It writes extremely rapidly and doesn't require you to visit the webUI to trigger. The specific problem seems to be log spam of an apc connection error message. I'll report upstream.
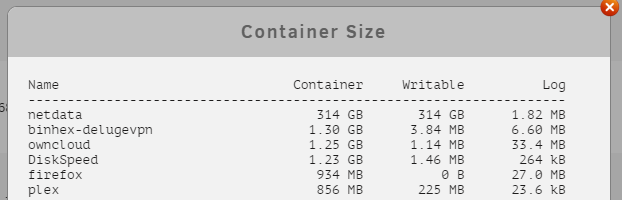

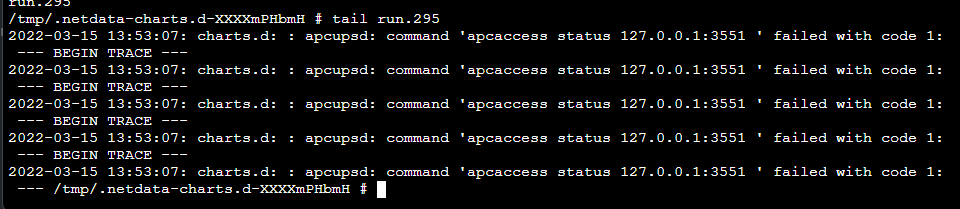
-
I think you've muddled your 🦈 and 🛡️'s 😉Ah... have you made sure that "Host access to custom networks" is set to "Enabled" in your UnRaid docker settings?Are you running the latest version of the container available (:latest)? If so our environments should be identical. The only thing I had to change to get mine working was turning IPv6 forwarding on for the host, which you've done too.Strange. Can you check cat /proc/sys/net/ipv6/conf/all/forwarding from the UnRaid console? I know it should return 1 based on your results above, but it's worth double checking.That's a pretty strange issue, that's not the error you should get if it's a SMBv1 problem from what I know, the error is normally much more specific. Have you tried posting a general thread in https://forums.unraid.net/forum/55-general-support/? They'll be much better prepared to help you there, this is more of a support thread for Tailscale-specific issues. Unfortunately I think if your non-Tailscale file transfers don't work properly, they are unlikely to work within Tailscale, as the method is exactly the same.What exact error is it you are getting?Have you made sure Privileged is ON?
 Hi there, no, no more complete panics since then. I've had quite a lot of general instability issues, the X470D4U motherboard seems to be plagued with issues, in particular reliability varies hugely BIOS to BIOS, so if you're running that motherboard then I heavily recommend the P3.50 BIOS firmware and 2.20.00 BMC firmware, which have been the most stable I've seen. It's also worth noting that future UnRaid versions have also improved other issues a lot, so I heavily recommend checking you are on the latest version as well.Correct on all three counts! However there is a bit more nuance to it. Whilst Wireguard can be used with a kernel implementation (which I believe is more efficient, so less CPU usage) it can also be implemented in software. Tailscale at the moment exclusively uses the software implementation to ease cross-platform compatibility, although there are plans in the future to link in with the kernel system on systems with support. This means it's technically not speaking with the system implementation at all at the moment. As for compatibility in general, as far as I'm aware any number of systems can use the underlying Wireguard technology, as long as they don't use conflicting address spaces (this is true with any VPN afaik and in my experience). Since Tailscale uses the rare 100. address range, it's incredibly unlikely to conflict with anything else provided you haven't manually specified that same range for the Unraid Wireguard tunnels.They can both run independently, so feel free to try it out!It's working now 🎉! . Thanks John.Good to hear! I'm glad I'm not going insane :). Unfortunately I still can't see the button because of another error: key [iManufacturer] doesn't exist Sounds like it's the same thing again but for this key 😅. I wonder what it's trying to read that lacks these values?Hi John, Am I going insane, or did there used to be a "Benchmark all" button or something to that extent? The only 'multiple benchmark' button I can find is under the controller info, and that seems to just check for a controller bottleneck. Also, when I look at the "USB Bus Tree" page, I see this error. Thanks for all your work!
Hi there, no, no more complete panics since then. I've had quite a lot of general instability issues, the X470D4U motherboard seems to be plagued with issues, in particular reliability varies hugely BIOS to BIOS, so if you're running that motherboard then I heavily recommend the P3.50 BIOS firmware and 2.20.00 BMC firmware, which have been the most stable I've seen. It's also worth noting that future UnRaid versions have also improved other issues a lot, so I heavily recommend checking you are on the latest version as well.Correct on all three counts! However there is a bit more nuance to it. Whilst Wireguard can be used with a kernel implementation (which I believe is more efficient, so less CPU usage) it can also be implemented in software. Tailscale at the moment exclusively uses the software implementation to ease cross-platform compatibility, although there are plans in the future to link in with the kernel system on systems with support. This means it's technically not speaking with the system implementation at all at the moment. As for compatibility in general, as far as I'm aware any number of systems can use the underlying Wireguard technology, as long as they don't use conflicting address spaces (this is true with any VPN afaik and in my experience). Since Tailscale uses the rare 100. address range, it's incredibly unlikely to conflict with anything else provided you haven't manually specified that same range for the Unraid Wireguard tunnels.They can both run independently, so feel free to try it out!It's working now 🎉! . Thanks John.Good to hear! I'm glad I'm not going insane :). Unfortunately I still can't see the button because of another error: key [iManufacturer] doesn't exist Sounds like it's the same thing again but for this key 😅. I wonder what it's trying to read that lacks these values?Hi John, Am I going insane, or did there used to be a "Benchmark all" button or something to that extent? The only 'multiple benchmark' button I can find is under the controller info, and that seems to just check for a controller bottleneck. Also, when I look at the "USB Bus Tree" page, I see this error. Thanks for all your work! No problem, glad it was that setting and not something more messy!This is probably due to the fact that Docker containers are prevented from talking to the host by default. So the traffic will be trying to do this: You -> Tailscale tunnel -> Tailscale Docker on Unraid Host -x> Pihole container Before it was doing this: You -> LAN -> Directly in the network interface of the Unraid host and routed to the PiHole To fix, try going to Settings -> Docker and changing "Host access to custom networks" to "Enabled". You'll have to temporarily disable Docker to do this and then restart it. Let me know if that works!
No problem, glad it was that setting and not something more messy!This is probably due to the fact that Docker containers are prevented from talking to the host by default. So the traffic will be trying to do this: You -> Tailscale tunnel -> Tailscale Docker on Unraid Host -x> Pihole container Before it was doing this: You -> LAN -> Directly in the network interface of the Unraid host and routed to the PiHole To fix, try going to Settings -> Docker and changing "Host access to custom networks" to "Enabled". You'll have to temporarily disable Docker to do this and then restart it. Let me know if that works!











