
feins
-
Posts
137 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by feins
-
-
2 hours ago, JorgeB said:
Looks like a certificate problem:
Apr 6 22:49:44 TS-P500 nginx: 2024/04/06 22:49:44 [error] 31577#31577: recv() failed (111: Connection refused) while requesting certificate status, responder: r3.o.lencr.org, peer: 202.188.238.139:80, certificate: "/boot/config/ssl/certs/certificate_bundle.pem"Try disabling SSL by typing in the CLI
use_ssl noI've rebooted the server while copying the log and diagnostic and its working now. Will it happen again or should i disable SSL?
-
I've just install Akaunting and setup postgresql15.
When i try to launch Akaunting the log show this error and no login page.
Enabling module rewrite.
To activate the new configuration, you need to run:
service apache2 restart
❌ Some options are missing and --no-interaction is present. Please run the following command for more information :
❌ php artisan help install
❌ Missing options are : db-port, db-name
❌ Some options are missing and --no-interaction is present. Please run the following command for more information :
❌ php artisan help install
❌ Missing options are : db-port, db-name
❌ Some options are missing and --no-interaction is present. Please run the following command for more information :
❌ php artisan help install
❌ Missing options are : db-port, db-name
❌ Some options are missing and --no-interaction is present. Please run the following command for more information :
❌ php artisan help install
❌ Missing options are : db-port, db-name
❌ Some options are missing and --no-interaction is present. Please run the following command for more information :
❌ php artisan help install
❌ Missing options are : db-port, db-name
❌ Some options are missing and --no-interaction is present. Please run the following command for more information :
❌ php artisan help install
❌ Missing options are : db-port, db-name** Press ANY KEY to close this window **
-
Dear All,
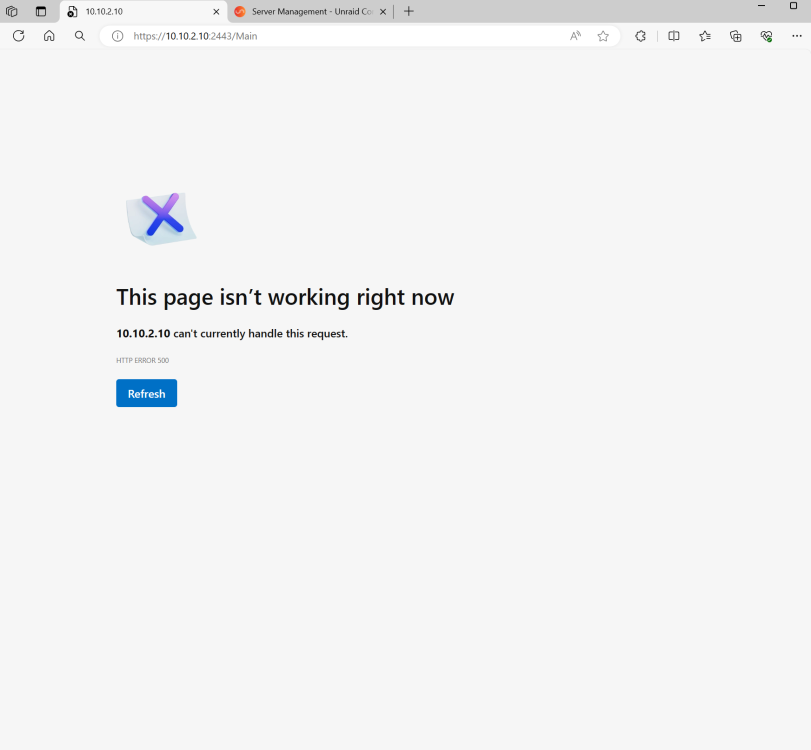
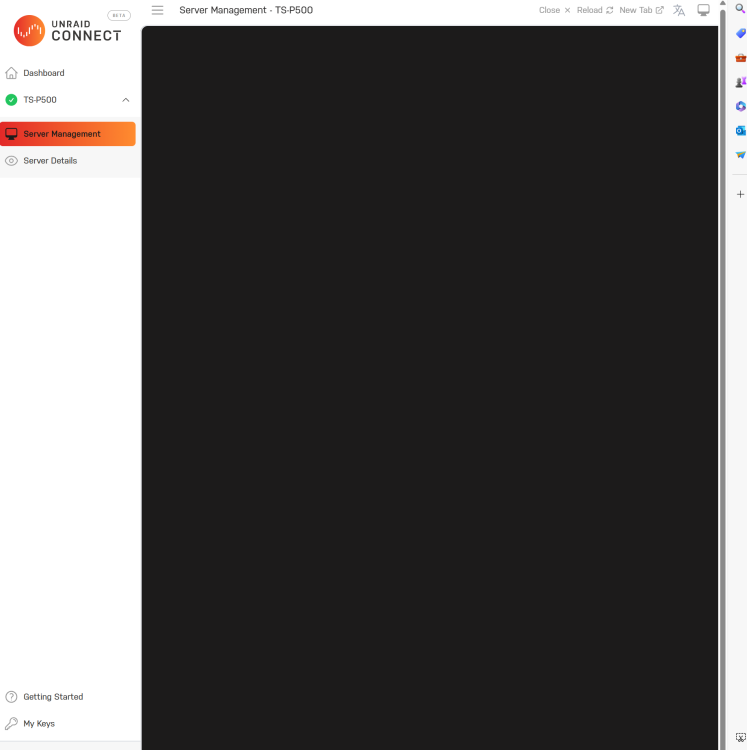
Ive updated to unraid version 6.12.9 from 6.12.8 a few days ago and everything works after update. But today i try to access the webui after i keyin the root and password i got HTTP Error 500.
I try to do a Unraid Connect remote also after keyin root and password i got a black screen only.
What should i do from here?
Seems my dockers are running fine as my plex and other docker are all accessible just Unraid Dashboard are not accessible only.
-
On 2/6/2024 at 11:01 PM, JorgeB said:
It's never a good sign, but if the post read test passed the disk is OK for now, bit I would recommend at least running a couple more read tests (or SMART extended tests) before using the disk.
Ok Ive run 3 more Preclear and also SMART Extended test.
Can help to verify if this Drive still good to use for the Array?
Here's the result.
#################################################################################################### # Unraid Server Preclear of disk Y995K4LHFW9G # # Cycle 3 of 3, partition start on sector 64. # # # # Step 1 of 5 - Pre-read verification: [8:07:11 @ 136 MB/s] SUCCESS # # Step 2 of 5 - Zeroing the disk: [8:06:20 @ 137 MB/s] SUCCESS # # Step 3 of 5 - Writing Unraid's Preclear signature: SUCCESS # # Step 4 of 5 - Verifying Unraid's Preclear signature: SUCCESS # # Step 5 of 5 - Post-Read verification: [8:07:15 @ 136 MB/s] SUCCESS # # # # # # # #################################################################################################### # Cycle elapsed time: 24:20:53 | Total elapsed time: 73:03:33 # #################################################################################################### #################################################################################################### # S.M.A.R.T. Status (device type: default) # # # # ATTRIBUTE INITIAL CYCLE 1 CYCLE 2 CYCLE 3 STATUS # # Reallocated_Sector_Ct 112 112 112 112 - # # Power_On_Hours 30863 30888 30912 30936 Up 73 # # Temperature_Celsius 31 40 39 38 Up 7 # # Reallocated_Event_Count 14 14 14 14 - # # Current_Pending_Sector 0 0 0 0 - # # Offline_Uncorrectable 0 0 0 0 - # # UDMA_CRC_Error_Count 750 750 750 750 - # # # # # #################################################################################################### # # #################################################################################################### --> ATTENTION: Please take a look into the SMART report above for drive health issues. --> RESULT: Preclear Finished Successfully!.
Feb 10 08:42:07 preclear_disk_Y995K4LHFW9G_28127: killing smartctl with pid 6448 - probably stalled ... Feb 10 08:42:28 preclear_disk_Y995K4LHFW9G_28127: killing smartctl with pid 6448 - probably stalled ... Feb 10 08:42:50 preclear_disk_Y995K4LHFW9G_28127: killing smartctl with pid 6448 - probably stalled ... Feb 10 08:43:11 preclear_disk_Y995K4LHFW9G_28127: killing smartctl with pid 6448 - probably stalled ... Feb 10 08:43:33 preclear_disk_Y995K4LHFW9G_28127: Resumed Feb 10 08:43:35 preclear_disk_Y995K4LHFW9G_28127: Zeroing: zeroing the disk completed! Feb 10 08:43:36 preclear_disk_Y995K4LHFW9G_28127: Signature: writing signature... Feb 10 08:43:37 preclear_disk_Y995K4LHFW9G_28127: Signature: verifying Unraid's signature on the MBR ... Feb 10 08:43:38 preclear_disk_Y995K4LHFW9G_28127: Signature: Unraid preclear signature is valid! Feb 10 08:43:38 preclear_disk_Y995K4LHFW9G_28127: Post-Read: post-read verification started 1 of 5 retries... Feb 10 08:43:38 preclear_disk_Y995K4LHFW9G_28127: Post-Read: verifying the beginning of the disk. Feb 10 08:43:39 preclear_disk_Y995K4LHFW9G_28127: Post-Read: verifying the rest of the disk. Feb 10 10:22:24 preclear_disk_Y995K4LHFW9G_28127: Post-Read: progress - 25% verified @ 161 MB/s Feb 10 12:11:03 preclear_disk_Y995K4LHFW9G_28127: Post-Read: progress - 50% verified @ 146 MB/s Feb 10 14:14:58 preclear_disk_Y995K4LHFW9G_28127: Post-Read: progress - 75% verified @ 125 MB/s Feb 10 16:50:53 preclear_disk_Y995K4LHFW9G_28127: Post-Read: elapsed time - 8:07:12 Feb 10 16:50:53 preclear_disk_Y995K4LHFW9G_28127: Post-Read: post-read verification completed! Feb 10 16:50:59 preclear_disk_Y995K4LHFW9G_28127: S.M.A.R.T.: Cycle 3 Feb 10 16:50:59 preclear_disk_Y995K4LHFW9G_28127: S.M.A.R.T.: Feb 10 16:50:59 preclear_disk_Y995K4LHFW9G_28127: S.M.A.R.T.: ATTRIBUTE INITIAL NOW STATUS Feb 10 16:50:59 preclear_disk_Y995K4LHFW9G_28127: S.M.A.R.T.: Reallocated_Sector_Ct 112 112 - Feb 10 16:50:59 preclear_disk_Y995K4LHFW9G_28127: S.M.A.R.T.: Power_On_Hours 30863 30936 Up 73 Feb 10 16:50:59 preclear_disk_Y995K4LHFW9G_28127: S.M.A.R.T.: Temperature_Celsius 31 38 Up 7 Feb 10 16:50:59 preclear_disk_Y995K4LHFW9G_28127: S.M.A.R.T.: Reallocated_Event_Count 14 14 - Feb 10 16:50:59 preclear_disk_Y995K4LHFW9G_28127: S.M.A.R.T.: Current_Pending_Sector 0 0 - Feb 10 16:50:59 preclear_disk_Y995K4LHFW9G_28127: S.M.A.R.T.: Offline_Uncorrectable 0 0 - Feb 10 16:50:59 preclear_disk_Y995K4LHFW9G_28127: S.M.A.R.T.: UDMA_CRC_Error_Count 750 750 - Feb 10 16:50:59 preclear_disk_Y995K4LHFW9G_28127: S.M.A.R.T.: Feb 10 16:50:59 preclear_disk_Y995K4LHFW9G_28127: Cycle: elapsed time: 24:20:53 Feb 10 16:50:59 preclear_disk_Y995K4LHFW9G_28127: Preclear: total elapsed time: 73:03:38
-
Just recently one of my 4TB Toshiba HDD suddenly prompt Reallocated Sector CT from 0 to 5 then to 8, 16, 96, 104 and 112.
This drive just did a preclear and was successfully completed with no error just the Reallocate Sector CT remain at 112 and Reallocated_Event_Count 14.
Since preclear successful is this drive still good to used?preclear_disk_2015033100081_32492.txt
#################################################################################################### # Unraid Server Preclear of disk 2015033100081 # # Cycle 1 of 1, partition start on sector 64. # # # # Step 1 of 5 - Pre-read verification: [8:06:26 @ 137 MB/s] SUCCESS # # Step 2 of 5 - Zeroing the disk: [8:06:23 @ 137 MB/s] SUCCESS # # Step 3 of 5 - Writing Unraid's Preclear signature: SUCCESS # # Step 4 of 5 - Verifying Unraid's Preclear signature: SUCCESS # # Step 5 of 5 - Post-Read verification: [8:06:29 @ 137 MB/s] SUCCESS # # # # # # # #################################################################################################### # Cycle elapsed time: 24:19:25 | Total elapsed time: 24:19:26 # #################################################################################################### #################################################################################################### # S.M.A.R.T. Status (device type: default) # # # # ATTRIBUTE INITIAL CYCLE 1 STATUS # # Reallocated_Sector_Ct 112 112 - # # Power_On_Hours 30825 30849 Up 24 # # Temperature_Celsius 31 36 Up 5 # # Reallocated_Event_Count 14 14 - # # Current_Pending_Sector 0 0 - # # Offline_Uncorrectable 0 0 - # # UDMA_CRC_Error_Count 750 750 - # # # # # #################################################################################################### # # #################################################################################################### --> ATTENTION: Please take a look into the SMART report above for drive health issues. --> RESULT: Preclear Finished Successfully!.
-
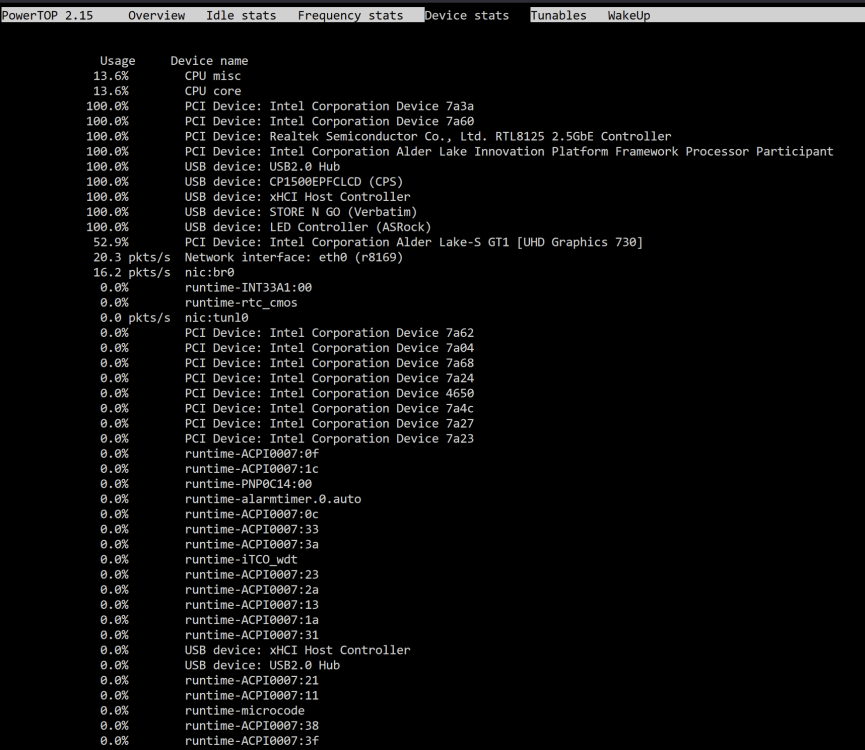
Ive just got myself an Asrock Z790 Pro RS/D4
Core i5-12400
Crucial 2X 16 GB DDR4 3200 1.2V
Cooler Master MWE 850 Gold V2 PSU
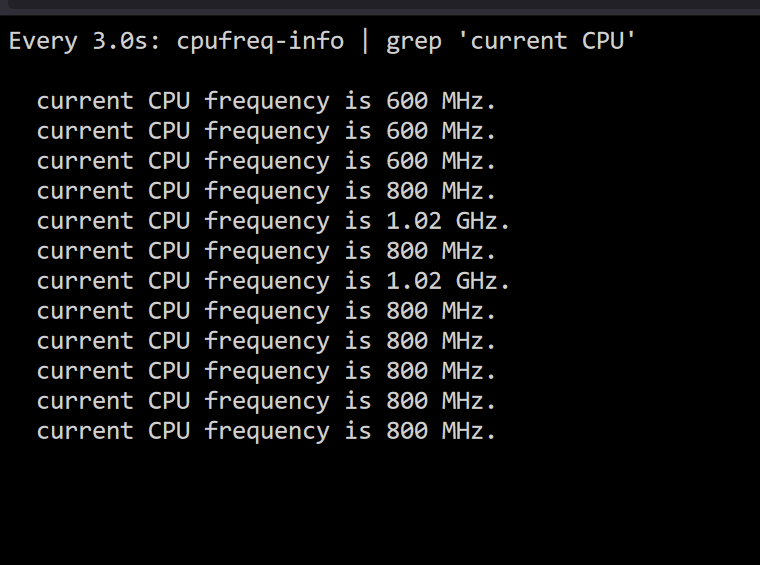
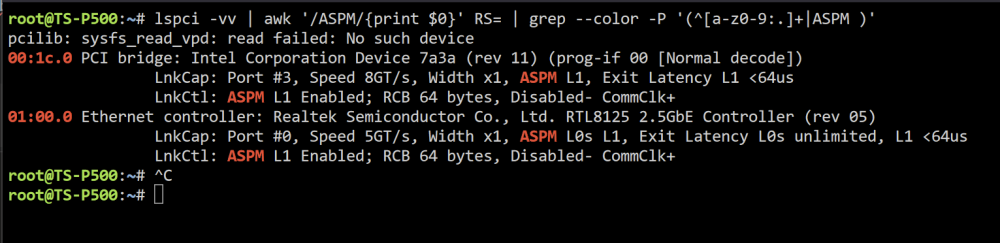
Ive enable all the ASPM on my bios and tested the system with barebone setup only get to C3 status.
Unraid iGPU driver installed
CPU Governor set to Power Save
What might be the issue that i cant get any lower than C3
Barebone power consumption 36W
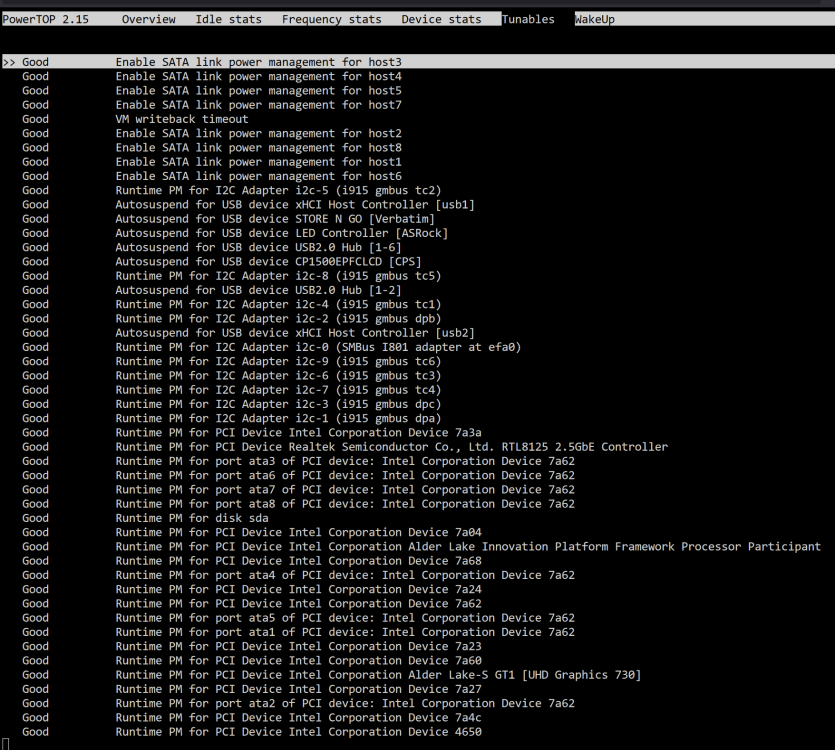
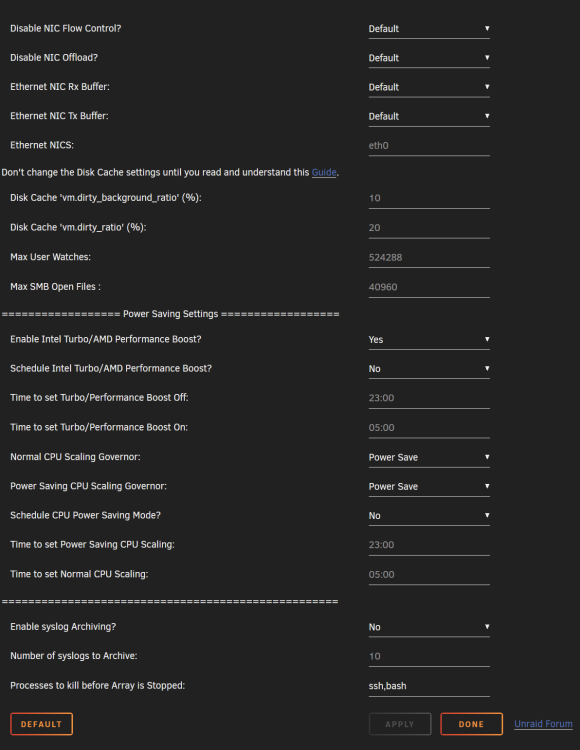
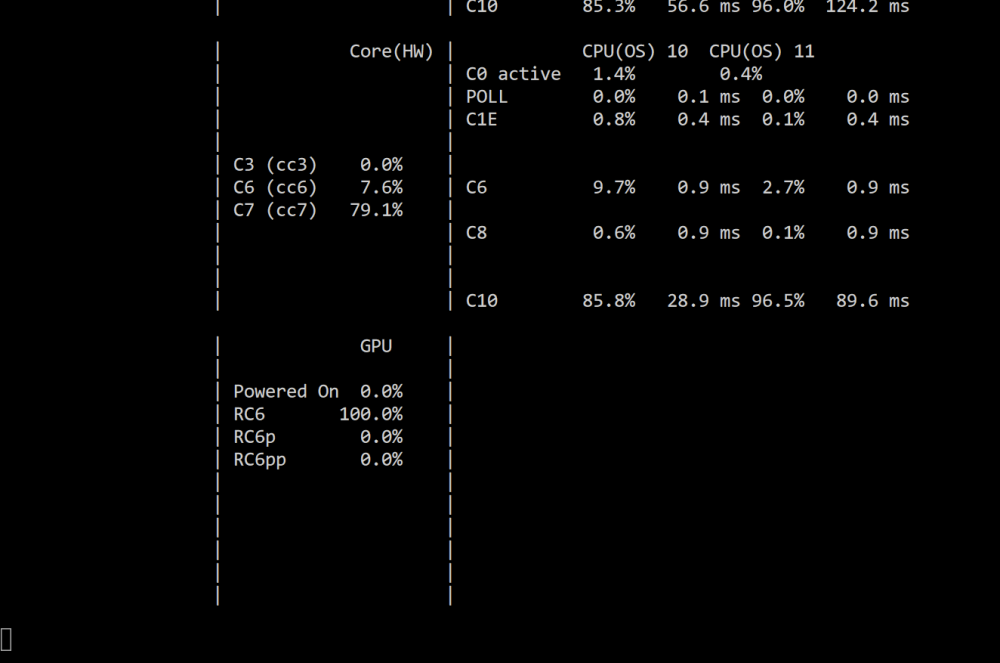
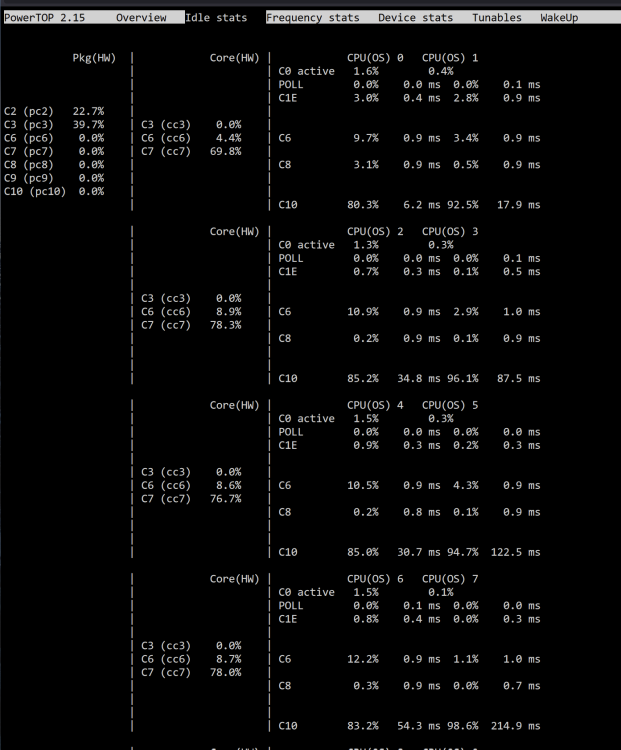
-
22 hours ago, Vr2Io said:
You also need clear attribute on those .nfo file. and re-export the hash.
Could you be able to guide me how to do that?
-
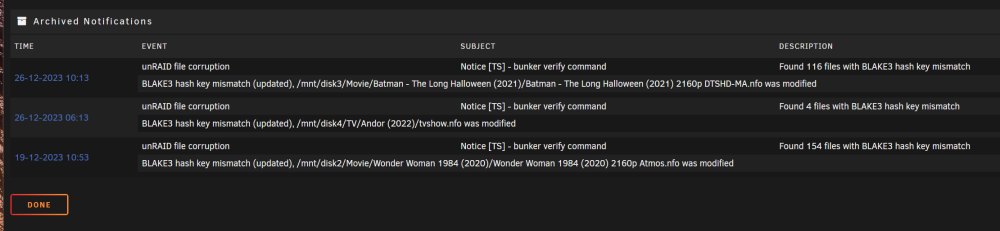
Each time when the file integrity runs i keep getting this type of errors.
How to resolve this? Ive already excluded *.nfo
-
On 10/4/2023 at 8:44 PM, Mainfrezzer said:
the mismatch lets you know that the file was modified, got a new checksum but you have no current export of that new checksum(thats expected with .nfo files, there is no point in checksumming them).
the pink box is intriguing, no clue thoRecently the file integrity just finish checksum and this time no Pink Check box. but I'm still getting prompt that
unRAID file corruption: 19-12-2023 10:53
Notice [TS] - bunker verify command
Found 154 files with BLAKE3 hash key mismatchHow do i find what type of files are those?
-
Dear all,
Im still getting the error. Ive already excluded the files.
BLAKE3
Excluded folders:
.Trash-99 .Recycle.Bin .stfolder .sync .TemporaryItems @Recycle .stversions
Excluded files:
*.tmp , *.nfo , *.log , *.partial , *.part , *.stgnore , *.apdisk
unRAID file corruption: 07-11-2023 10:27
Notice [TS] - bunker verify command
Found 154 files with BLAKE3 hash key mismatch -
Dear All,
Why Disk 2 i got a pink box?
Also i notice that i got alot of hash key mismatch.

-
On 9/30/2023 at 7:00 PM, itimpi said:
The online documentation is accessible via the Manual link at the bottom of the Unraid GUI. In addition every forum page has a DOCS link at the top and a Documentation link at the bottom. The You want to go to Unraid OS ->Manual->Troubleshooting section for guidance on Unclean shutdowns.
Oooh that User guild i was thinking there a troubleshooting guide for the plugin itself.
Ok i've just add some time out for my Docker and System shutdown since i don't use any VM.
Ive also attach the Diagnostic Log, maybe you could pinpoint what might be the case that cause the Unclean Shutdown.
-
30 minutes ago, itimpi said:
No. The plugin will never cause an unclean shutdown to happen but it simply tries to make it obvious when it happens.
The message is correct if a parity check started. Have you looked at the section of the documentation that the notification suggests you look at.
Where is the Troubleshooting online doc?
-
12 minutes ago, JorgeB said:
This is related to the parity check plugin, make sure it's updated to latest, if it doesn't help use the existing plugin support thread:
https://forums.unraid.net/topic/78394-plugin-parity-check-tuning/
The Plugin is up to date.
Should i uninstall the parity check plugin?
-
my P500 also using the same chip but its been years i've trying to ask for support until now without any progress.
-
Mine a Lenovo Thinkstation P500, i try to do a sensors scan and my Nuvoton chip got this output Found unknown chip with ID 0xb732
any help?
-

I also getting this Unclean Shutdown detected from time to time.
I've just update a docker and some plugin.
I did a reboot and after the server rebooted i got a message Unclean shutdown detected and my parity check start.
I would like to know whats the issue as well and what should i do to resolve this.
-
Need some help i had file Binhex file integrity install and recently after file verification and i was prompt with some file corruption error.
unRAID file corruption: 26-09-2023 10:29
Notice [TS] - bunker verify command
Found 41 files with BLAKE3 hash key corruptionAs I'm just a beginner, what should i do on this?
-
On 9/6/2023 at 4:05 PM, itimpi said:
Make sure you are on the latest release of the parity.check.tuning plugin.
If you have it delete the 'parity.check.tuning.paused' file in the plugins folder on the flash drive. Looks like the plugin somehow has missed the fact the check has finished in your case although the latest version may fix this.
If you continue to have problems after that then please enable the 'Testing' mode logging in the plugins settings and post your diagnostics after the problem has occurred so I can check out why.
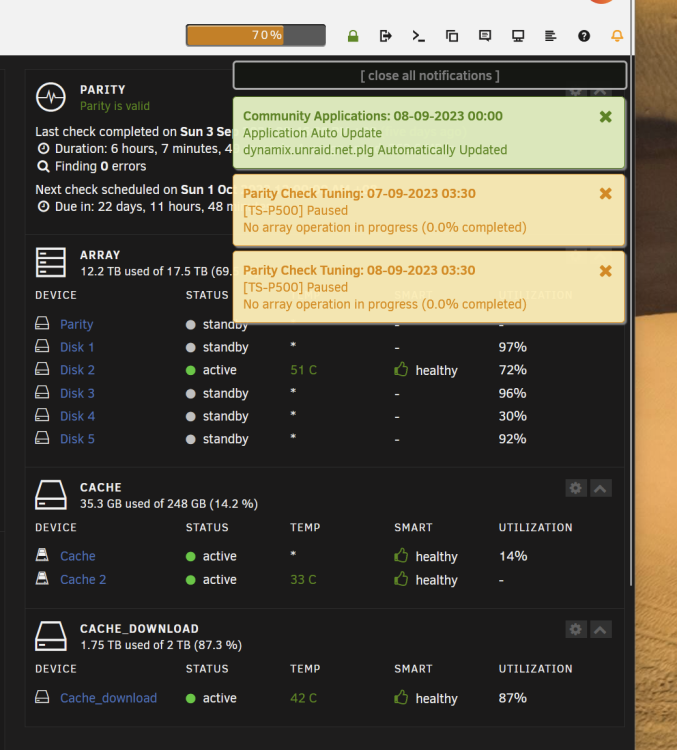
Ok im still getting the SNMP notification at 3.30am each day even there suppose to be no event. Ive attach the Diagnostic log with Testing mode logging enable.
-
4 hours ago, itimpi said:
Make sure you are on the latest release of the parity.check.tuning plugin.
If you have it delete the 'parity.check.tuning.paused' file in the plugins folder on the flash drive. Looks like the plugin somehow has missed the fact the check has finished in your case although the latest version may fix this.
If you continue to have problems after that then please enable the 'Testing' mode logging in the plugins settings and post your diagnostics after the problem has occurred so I can check out why.
Noted, just update to the latest release will monitor for a few day.
-
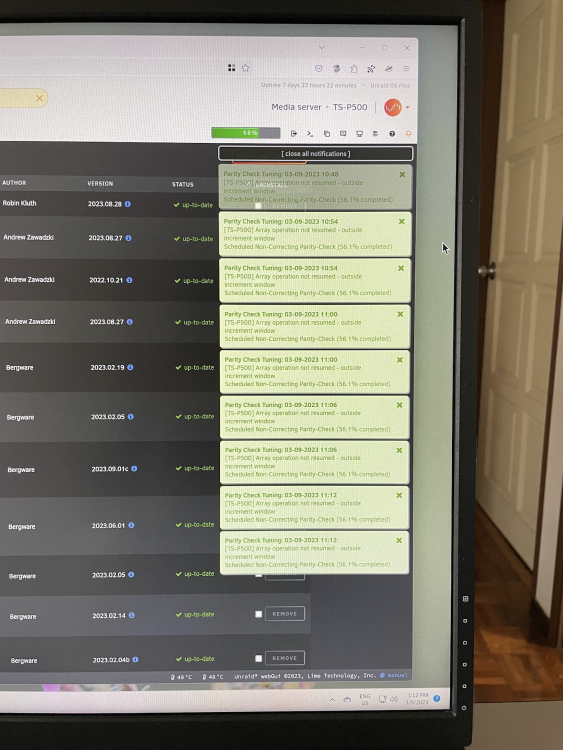
On 9/3/2023 at 4:00 PM, JorgeB said:
Try rebooting.
After reboot i tot its fix. but seems it still do broadcast. I dont behave at such until last week onward.
-
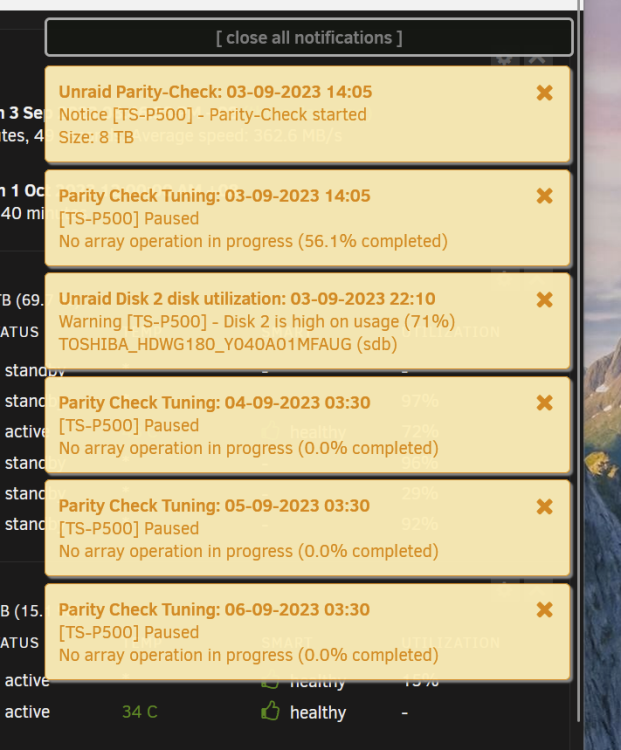
Dear All,
Just recently my server just send SNMP nonstop on the same event.
Its been working well until recent before that just 1 notification on 1 event only but this few day it just keep sending the same SNMP for the same event repeatably nonstop.
-
There is a choice of ATX boards with 8 SATA ports.
Some newer PSUs are remarkably more efficient - there's quite a bit of talk about them at the end of the thread linked above.
Lots of motherboards now come with the built-in 2.5 Gigabit LAN
You can use M.2 NVMe SSDs to free up motherboard SATA ports.
https://pcpartpicker.com/list/
Noted yes. New board starting to include 2.5gb nic. Not many review that actually mention about idling power. Because few mth back I help a fren to setup his unraid where he use his old Intel gen4 Core i5 4670, Asus mobo, 32gb Ram HBA card and 8HDD and his 1200W Silverstone 80+ Platinum PSU. And a Silverstone TJ07 casing. He has his roon core running 24/7 and Plex. With most of the time Plex transcoding CPU running near 100% with an impressive 70+W of power usage and idling at 30+W full system.
Sent from my iPhone using Tapatalk -
58 minutes ago, Lolight said:
Well, the newer consumer tech will be more efficient, there shouldn't be any doubt about that.
I don't know your exact system setup, but If you're real concerned about power efficiency and want to achieve maximum power savings then you should try to build a system that doesn't contain any add-on cards.
There's an unlimited variety of hardware combinations - impossible to say which will provide the best results without trying.
Check out the thread below.
It's a long thread, but there are numerous examples of what hardware tends to deliver better results.
Also provides general idea about electricity consumption for most common for NAS add-on cards and dGPUs and why they should be avoided.
Also talks about PSUs effeiciency and why they shouldn't be overlooked.
Yes i totally understand about add on card that's why at mean time my Xeon Processor doesn't come with an iGPU as such i notice that my P2000 in idle status still drawn 8W of power. HBA card i don't think there will be avoid as there wont have any board that come with more than 6 Sata port at mean time. So far this Lenovo P500 come with a 80+ Gold PSU. I understand that PSU effeciency does take into account.
My system is actually a Stock Lenovo P500 Workstation pretty standard come with 128Gb of DDR4 ECC Ram a 16core Xeon E5-2698-V3, 490W 80+ Gold Lenovo PSU. The only additional item that i add in is a LSI SAS 9207 HBA, Nvidia P2000 and Intel X520-T2 10Gb Nic Card. There are a total of 7 Drive and 2 SSD a total of 9 Drive at the moment.

















Dashboard dont load HTTP Error 500 after updated to 6.12.9
in General Support
Posted
It happen again and now I've disable SSL as you recommend.