




wm-te
Members
-
Joined
-
Last visited
Everything posted by wm-te
-
Hey - thanks for addng this to unraid. I've had good success generating images with the Tesla P4 I used with containers. I have found a problem - and seem to have just repeated it. I'm using 02-sd-webui. When I install the Dreambooth extension, and then restart the UI as prompted, the container dies and won't restart. I think I had the same problem, caused in the same way, about 2 weeks ago. I tried to fix by removing the folder sd_dreambooth_extension from the extension folder - but that didn't work so I just did a total remove/reinstall. My python fu is not strong enough to see if there is a fix I should apply in the log output. If anyone has ideas that would be great. Also is there a better way to uninstall an extension that causes a problems like this? The log says : Traceback (most recent call last): File "/opt/stable-diffusion/02-sd-webui/webui/venv/lib/python3.10/site-packages/transformers/utils/import_utils.py", line 1086, in _get_module return importlib.import_module("." + module_name, self.__name__) File "/usr/lib/python3.10/importlib/__init__.py", line 126, in import_module return _bootstrap._gcd_import(name[level:], package, level) File "<frozen importlib._bootstrap>", line 1050, in _gcd_import File "<frozen importlib._bootstrap>", line 1027, in _find_and_load File "<frozen importlib._bootstrap>", line 1006, in _find_and_load_unlocked File "<frozen importlib._bootstrap>", line 688, in _load_unlocked File "<frozen importlib._bootstrap_external>", line 883, in exec_module File "<frozen importlib._bootstrap>", line 241, in _call_with_frames_removed File "/opt/stable-diffusion/02-sd-webui/webui/venv/lib/python3.10/site-packages/transformers/modeling_utils.py", line 85, in <module> from accelerate import __version__ as accelerate_version File "/opt/stable-diffusion/02-sd-webui/webui/venv/lib/python3.10/site-packages/accelerate/__init__.py", line 3, in <module> from .accelerator import Accelerator File "/opt/stable-diffusion/02-sd-webui/webui/venv/lib/python3.10/site-packages/accelerate/accelerator.py", line 35, in <module> from .checkpointing import load_accelerator_state, load_custom_state, save_accelerator_state, save_custom_state File "/opt/stable-diffusion/02-sd-webui/webui/venv/lib/python3.10/site-packages/accelerate/checkpointing.py", line 24, in <module> from .utils import ( File "/opt/stable-diffusion/02-sd-webui/webui/venv/lib/python3.10/site-packages/accelerate/utils/__init__.py", line 131, in <module> from .bnb import has_4bit_bnb_layers, load_and_quantize_model File "/opt/stable-diffusion/02-sd-webui/webui/venv/lib/python3.10/site-packages/accelerate/utils/bnb.py", line 42, in <module> import bitsandbytes as bnb File "/opt/stable-diffusion/02-sd-webui/webui/venv/lib/python3.10/site-packages/bitsandbytes/__init__.py", line 6, in <module> from .autograd._functions import ( File "/opt/stable-diffusion/02-sd-webui/webui/venv/lib/python3.10/site-packages/bitsandbytes/autograd/_functions.py", line 5, in <module> import bitsandbytes.functional as F File "/opt/stable-diffusion/02-sd-webui/webui/venv/lib/python3.10/site-packages/bitsandbytes/functional.py", line 13, in <module> from .cextension import COMPILED_WITH_CUDA, lib File "/opt/stable-diffusion/02-sd-webui/webui/venv/lib/python3.10/site-packages/bitsandbytes/cextension.py", line 113, in <module> lib = CUDASetup.get_instance().lib File "/opt/stable-diffusion/02-sd-webui/webui/venv/lib/python3.10/site-packages/bitsandbytes/cextension.py", line 109, in get_instance cls._instance.initialize() File "/opt/stable-diffusion/02-sd-webui/webui/venv/lib/python3.10/site-packages/bitsandbytes/cextension.py", line 59, in initialize binary_name, cudart_path, cuda, cc, cuda_version_string = evaluate_cuda_setup() File "/opt/stable-diffusion/02-sd-webui/webui/venv/lib/python3.10/site-packages/bitsandbytes/cuda_setup/main.py", line 125, in evaluate_cuda_setup cuda_version_string = get_cuda_version(cuda, cudart_path) File "/opt/stable-diffusion/02-sd-webui/webui/venv/lib/python3.10/site-packages/bitsandbytes/cuda_setup/main.py", line 45, in get_cuda_version check_cuda_result(cuda, cudart.cudaRuntimeGetVersion(ctypes.byref(version))) File "/usr/lib/python3.10/ctypes/__init__.py", line 387, in __getattr__ func = self.__getitem__(name) File "/usr/lib/python3.10/ctypes/__init__.py", line 392, in __getitem__ func = self._FuncPtr((name_or_ordinal, self)) AttributeError: python3: undefined symbol: cudaRuntimeGetVersion The above exception was the direct cause of the following exception: Traceback (most recent call last): File "/opt/stable-diffusion/02-sd-webui/webui/launch.py", line 48, in <module> main() File "/opt/stable-diffusion/02-sd-webui/webui/launch.py", line 44, in main start() File "/opt/stable-diffusion/02-sd-webui/webui/modules/launch_utils.py", line 432, in start import webui File "/opt/stable-diffusion/02-sd-webui/webui/webui.py", line 13, in <module> initialize.imports() File "/opt/stable-diffusion/02-sd-webui/webui/modules/initialize.py", line 16, in imports import pytorch_lightning # noqa: F401 File "/opt/stable-diffusion/02-sd-webui/webui/venv/lib/python3.10/site-packages/pytorch_lightning/__init__.py", line 35, in <module> from pytorch_lightning.callbacks import Callback # noqa: E402 File "/opt/stable-diffusion/02-sd-webui/webui/venv/lib/python3.10/site-packages/pytorch_lightning/callbacks/__init__.py", line 14, in <module> from pytorch_lightning.callbacks.batch_size_finder import BatchSizeFinder File "/opt/stable-diffusion/02-sd-webui/webui/venv/lib/python3.10/site-packages/pytorch_lightning/callbacks/batch_size_finder.py", line 24, in <module> from pytorch_lightning.callbacks.callback import Callback File "/opt/stable-diffusion/02-sd-webui/webui/venv/lib/python3.10/site-packages/pytorch_lightning/callbacks/callback.py", line 25, in <module> from pytorch_lightning.utilities.types import STEP_OUTPUT File "/opt/stable-diffusion/02-sd-webui/webui/venv/lib/python3.10/site-packages/pytorch_lightning/utilities/types.py", line 27, in <module> from torchmetrics import Metric File "/opt/stable-diffusion/02-sd-webui/webui/venv/lib/python3.10/site-packages/torchmetrics/__init__.py", line 14, in <module> from torchmetrics import functional # noqa: E402 File "/opt/stable-diffusion/02-sd-webui/webui/venv/lib/python3.10/site-packages/torchmetrics/functional/__init__.py", line 120, in <module> from torchmetrics.functional.text._deprecated import _bleu_score as bleu_score File "/opt/stable-diffusion/02-sd-webui/webui/venv/lib/python3.10/site-packages/torchmetrics/functional/text/__init__.py", line 50, in <module> from torchmetrics.functional.text.bert import bert_score # noqa: F401 File "/opt/stable-diffusion/02-sd-webui/webui/venv/lib/python3.10/site-packages/torchmetrics/functional/text/bert.py", line 23, in <module> from torchmetrics.functional.text.helper_embedding_metric import ( File "/opt/stable-diffusion/02-sd-webui/webui/venv/lib/python3.10/site-packages/torchmetrics/functional/text/helper_embedding_metric.py", line 27, in <module> from transformers import AutoModelForMaskedLM, AutoTokenizer, PreTrainedModel, PreTrainedTokenizerBase File "<frozen importlib._bootstrap>", line 1075, in _handle_fromlist File "/opt/stable-diffusion/02-sd-webui/webui/venv/lib/python3.10/site-packages/transformers/utils/import_utils.py", line 1076, in __getattr__ module = self._get_module(self._class_to_module[name]) File "/opt/stable-diffusion/02-sd-webui/webui/venv/lib/python3.10/site-packages/transformers/utils/import_utils.py", line 1088, in _get_module raise RuntimeError( RuntimeError: Failed to import transformers.modeling_utils because of the following error (look up to see its traceback): python3: undefined symbol: cudaRuntimeGetVersion [+] accelerate version 0.21.0 installed. [+] diffusers version 0.19.3 installed. [+] transformers version 4.30.2 installed. [+] bitsandbytes version 0.35.4 installed. Launching Web UI with arguments: --listen --port 9000 --enable-insecure-extension-access --medvram --xformers --no-half-vae --disable-nan-check --api
-
An update - things seem be working for the most part - but I think some files cause hw transcode issues. I've moved to plex 1.32.4.7195 which release notes say something about fixing a transcode issue for linux users (I can't find those notes now to quote exact wording). I'm not sure if its an Unraid v6.12.x issue or plex at this point. If I start playback via the app.plex.tv domain, most files will play ok. If I change the quality setting to something that needs transcode, it stops playing. I can see in the plex dashboard that the GPU will briefly show 1 process for a second, then go back to 0 processes.
-
I'm having some problems with plex hardware transcoding since moving to 6.12.0 a few days ago. Was working well on unraid 6.11.5. Checkign the logs in plex, I see [Req#d9b/Transcode] [FFMPEG] - Failed to initialise VAAPI connection: -1 (unknown libva error). and [Req#ab55/Transcode/1qakjznm3xolwgd9qrw632z3] Transcode runner appears to have died. Works ok if I disable hardware transcode in plex config - but CPU goes up (as expected). Hardware is Dell Poweredge T630 with Nvidia Telsa P4. Currently using nvidia driver 535.43.02 but had the same problem with latest version 535.54.03. I thought I had fixed this a few days ago by updating permissions to 0777 on /tmp which is set as the /transcode container path - but the problem is back.
-
I've just reinstalled gitlab-ce container. I've got correct SMTP info in the config, but I'm not seeing signs that its sending emails. I'm using mailgun - which is working well for unraid notifications, and other containers I'm running. Mailgun logs show no emails hitting their server. I'd like to troubleshoot it - but need a few pointers. Where should I check in the container to see what is happening when it tries to send an email? Gitlab-ce log files show this message ==> /var/log/gitlab/sidekiq/current <== sh: 1: /usr/sbin/sendmail: not found If I enter the container and edit /etc/gitlab/gitlab.rb with the correct info, I receive emails ok. So it looks like the problem is SMTP config settings not being picked up when the container is started.
-
There seem to be some GTX 1080 and 1070 cards hitting the 2nd hand market - they would do the job well. Strongly recommend going for the blower style cards like the Asus Turbo cards, or most of the founders editions. These suit the airflow in the rack servers better. The more common dual or triple fan GPUs are too big to fit into the space. You also need a special cable to run power from the main board to the gpu - but these are pretty easy to get via eBay. The one I got was part number 9H6FV .
-
Does the recent release of Unraid 6.9 fix this issue?
-
Its a while since I posted on this topic. I'm currently at 65 days uptime - which is way more than I'd seen when I last posted. The change has been to always close browser tabs that have the Unraid web ui open. I found the other day that I had left a tab open for a few days, and as a result my logs are at 3% of capacity. Until I left that tab open, this had remained at 1%. From past experience, that percentage climbs very rapidly once it starts moving. I will keep closing browser tabs as a workaround - but I would prefer a fix if anyone can suggest one.
-
No - i haven't solved it yet. And looking through other recent posts in this forum, I suspect that there are other users having a similar problem. My server has this issue again today - but I was able to reboot it before it became unresponsive (which saved me doing a 10hr parity check). This time I also had syslog going to a local syslog server so I was able to check what was happening in the logs before the crash. Looks like there are hundreds of these lines Jul 9 09:10:02 Tower rsyslogd: action 'action-0-builtin:omfile' (module 'builtin:omfile') message lost, could not be processed. Check for additional error messages before this one. [v8.1908.0 try https://www.rsyslog.com/e/2027 ] preceded by possibly thousands of these lines .. log file was at 97mb. Jul 8 21:27:31 Tower nginx: 2020/07/08 21:27:31 [alert] 1660#1660: *2874685 header already sent while keepalive, client: 192.168.1.187, server: 0.0.0.0:80 Jul 8 21:27:31 Tower kernel: nginx[1660]: segfault at 0 ip 0000000000000000 sp 00007ffeaafbe7b8 error 14 in nginx[400000+21000] Jul 8 21:27:31 Tower kernel: Code: Bad RIP value. Jul 8 21:27:31 Tower nginx: 2020/07/08 21:27:31 [alert] 6641#6641: worker process 1660 exited on signal 11 Jul 8 21:27:31 Tower nginx: 2020/07/08 21:27:31 [crit] 1665#1665: ngx_slab_alloc() failed: no memory Jul 8 21:27:31 Tower nginx: 2020/07/08 21:27:31 [error] 1665#1665: shpool alloc failed Jul 8 21:27:31 Tower nginx: 2020/07/08 21:27:31 [error] 1665#1665: nchan: Out of shared memory while allocating channel /var. Increase nchan_max_reserved_memory. Jul 8 21:27:31 Tower nginx: 2020/07/08 21:27:31 [alert] 1665#1665: *2874687 header already sent while keepalive, client: 192.168.1.187, server: 0.0.0.0:80 Jul 8 21:27:31 Tower kernel: nginx[1665]: segfault at 0 ip 0000000000000000 sp 00007ffeaafbe7b8 error 14 in nginx[400000+21000] Jul 8 21:27:31 Tower kernel: Code: Bad RIP value. Jul 8 21:27:31 Tower nginx: 2020/07/08 21:27:31 [alert] 6641#6641: worker process 1665 exited on signal 11 Jul 8 21:27:31 Tower nginx: 2020/07/08 21:27:31 [crit] 1666#1666: ngx_slab_alloc() failed: no memory Jul 8 21:27:31 Tower nginx: 2020/07/08 21:27:31 [error] 1666#1666: shpool alloc failed Jul 8 21:27:31 Tower nginx: 2020/07/08 21:27:31 [error] 1666#1666: nchan: Out of shared memory while allocating channel /disks. Increase nchan_max_reserved_memory. Jul 8 21:27:31 Tower nginx: 2020/07/08 21:27:31 [error] 1666#1666: *2874689 nchan: error publishing message (HTTP status code 507), client: unix:, server: , request: "POST /pub/disks?buffer_length=1 HTTP/1.1", host: "localhost" Jul 8 21:27:32 Tower nginx: 2020/07/08 21:27:32 [crit] 1666#1666: ngx_slab_alloc() failed: no memory Jul 8 21:27:32 Tower nginx: 2020/07/08 21:27:32 [error] 1666#1666: shpool alloc failed Jul 8 21:27:32 Tower nginx: 2020/07/08 21:27:32 [error] 1666#1666: nchan: Out of shared memory while allocating channel /cpuload. Increase nchan_max_reserved_memory. Jul 8 21:27:32 Tower nginx: 2020/07/08 21:27:32 [error] 1666#1666: *2874690 nchan: error publishing message (HTTP status code 507), client: unix:, server: , request: "POST /pub/cpuload?buffer_length=1 HTTP/1.1", host: "localhost" Jul 8 21:27:32 Tower nginx: 2020/07/08 21:27:32 [crit] 1666#1666: ngx_slab_alloc() failed: no memory Jul 8 21:27:32 Tower nginx: 2020/07/08 21:27:32 [error] 1666#1666: shpool alloc failed Jul 8 21:27:32 Tower nginx: 2020/07/08 21:27:32 [error] 1666#1666: nchan: Out of shared memory while allocating channel /var. Increase nchan_max_reserved_memory. Jul 8 21:27:32 Tower nginx: 2020/07/08 21:27:32 [alert] 1666#1666: *2874691 header already sent while keepalive, client: 192.168.1.187, server: 0.0.0.0:80
-
I spoke too soon. A few hours after the post above, the server hard crashed. Web ui totally unresponsive, no ssh etc. This was on screen of the attached monitor.
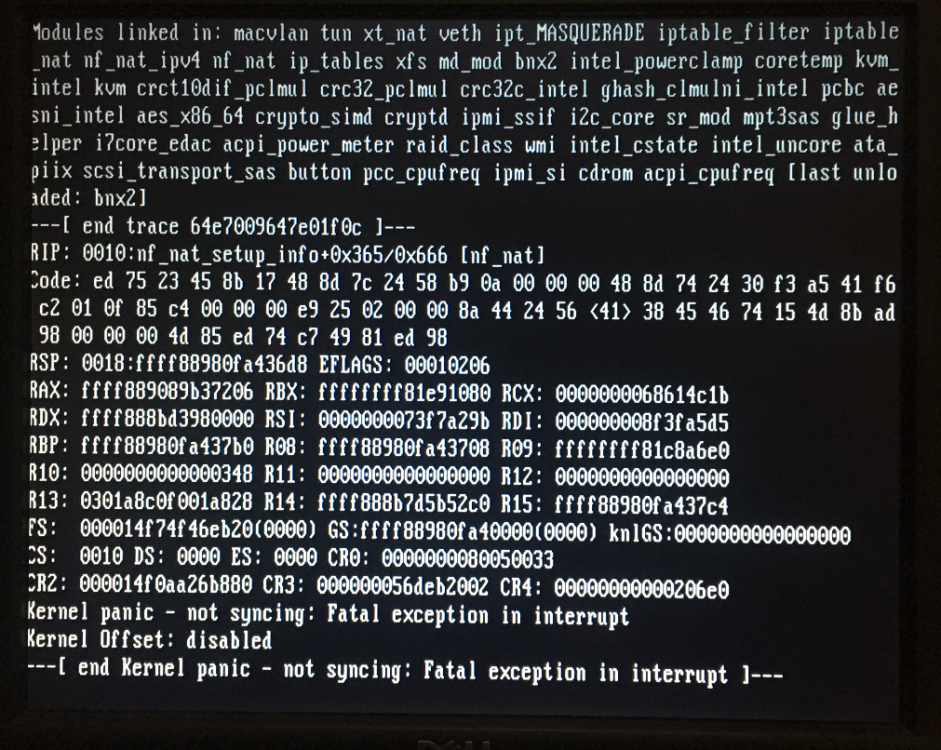
-
Since I posted my message above 13 days ago, I've not had a system crash. 14 days 17 hours uptime. I was getting no more than 5 days due to this problem. After the last crash, I stopped a number of new dockers I had been using for just a few weeks. Sonarr, Radarr and Jackett. Since stopping these, my system appears to be stable again. Log file size reporting as 1%.
-
I'm having what I think is the same problem. I see this filling up my nginx log files. ker process: ./nchan-1.2.6/src/store/spool.c:479: spool_fetch_msg: Assertion `spool->msg_status == MSG_INVALID' failed. 2020/06/05 19:43:01 [alert] 6602#6602: worker process 12703 exited on signal 6 Eventually this log memory reaches 100% and the server crashes. This requires a reboot - I can't even ssh in. This is happening within 3-5 days of a reboot. I've noticed that the cpu activity graph on the dashboard will become inactive, with no data shown for any core. I have VM turned off. I'm running a number of dockers. ____ Unraid 6.8.3 Dell r710 12cores 96gb ecc ram
