




bullmoose20
Members
-
Joined
-
Last visited
Everything posted by bullmoose20
-
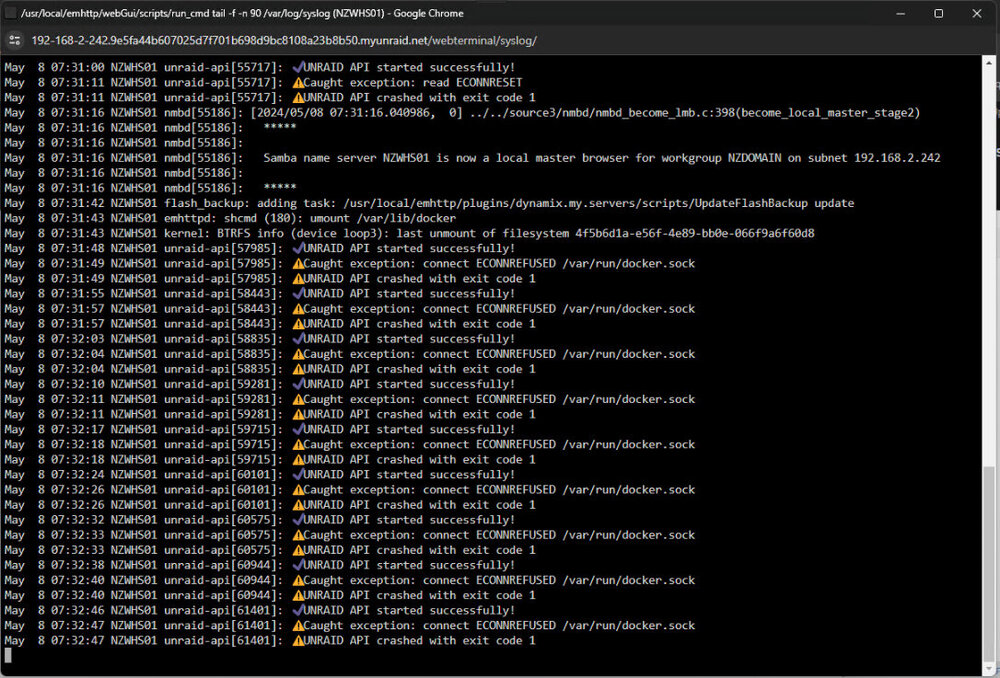
Also having this issue. Version 6.12.10 2024-04-03 I will add a diagnostics shortly(Just added) nzwhs01-diagnostics-20240508-0745.zip nzwhs01-diagnostics-20240508-1629.zip
-
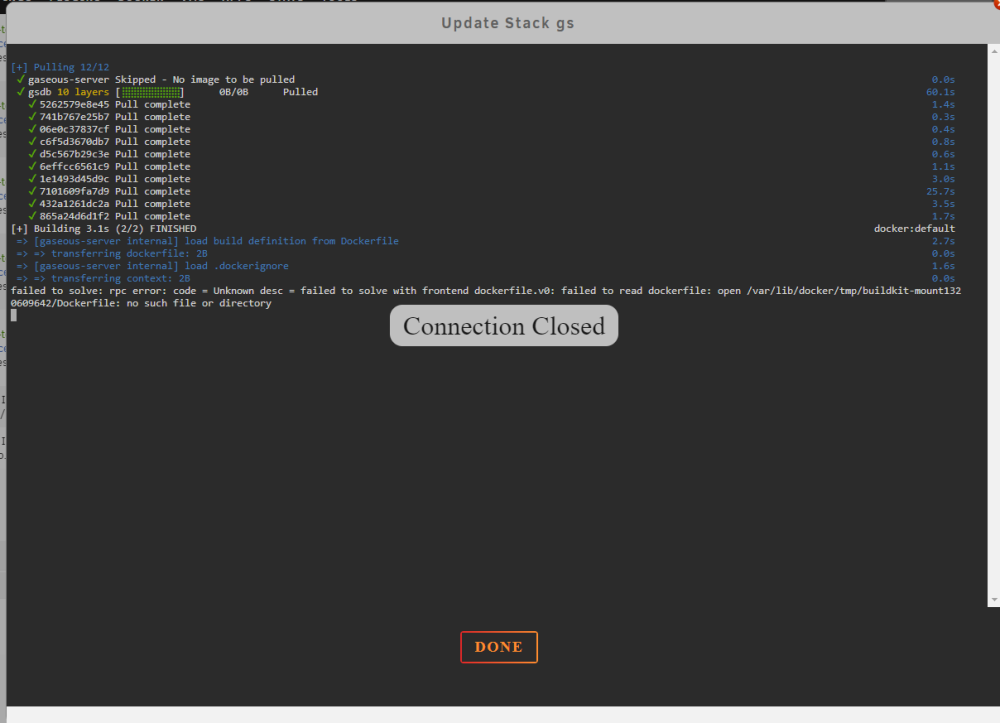
chatted with the dev.. my bad.. I had the wrong docker-compose file
-
i keep getting the following error: version: '2' services: gaseous-server: container_name: gaseous-server build: context: ./ dockerfile: Dockerfile restart: unless-stopped networks: - gaseous depends_on: - gsdb ports: - 5198:80 volumes: - gs:/mnt/user/appdata/gaseous-server environment: - dbhost=gsdb - dbuser=root - dbpass=gaseous - igdbclientid=(redacted) - igdbclientsecret=(redacted) gsdb: container_name: gsdb image: mysql:8 restart: unless-stopped networks: - gaseous volumes: - gsdb:/mnt/user/appdata/mysql environment: - MYSQL_ROOT_PASSWORD=gaseous - MYSQL_USER=gaseous - MYSQL_PASSWORD=gaseous networks: gaseous: driver: bridge volumes: gs: gsdb:
-
So… I took the opportunity to shutdown the server and move it to a new location. In doing so I took the time to get rid of dust that had accumulated everywhere and reseated all the ram. Since then… all looks good. 20 hours and counting of uptime. I agree… it was a red herring and just darn luck that the machine had been running so long. Talk about Murphy’a Law!
-
random-reboots.mp4 Well... I thought that with my ilo4 board and console connected, I might get more details from the "screen" that might not be captured in the syslog locally on the usb drive or on the remote syslog server, however this reset just happens... literally nothing on the screen... as you can see. I am starting a memtest for the next 24 hours or so I guess? If anyone has an idea or sees a clue, let me know.
-
i cannot conclude much at this point. Someone is telling me that I am likely experiencing kernel panics and that I should be doing a memtest for 24 hours to see. I am not at that point yet because with 168GB of RAM, that memtest is pretty painful
-
crashed again. syslog (4)nzwhs01-diagnostics-20230624-0950.zip
-
Update! currently at 9h15minutes of uptime and server has not rebooted randomly. So there might be a plugin that is causing me grief in 6.12.1. Suggestions? Should I: a - stay in safe mode with plugins not running and turn on docker service which will then start up all my containers? or b - reboot to get out of safe mode, leave Docker service off, start enabling plugins (assuming I can even do that) 1 by one and wait on each plugin to see? or c - something else
-
I see btrfs errors littered in your syslog. you could have a bad disk
-
In my case, the most stability that I have is the following and going on 6 hours and 6 minutes of uptime: VM service off Docker service off Rebooted to safe mode(effectively ruling out all plugins), added passphrase for encrypted disks so file systems and disks mount Since I do not use the server shares in this way and I must have my containers and vm's running... this is not really a workaround for me. Waiting for guidance on what I should do next.... Like at this point is looks like maybe a bad plugin is causing the server to reset. Nothing obvious in the syslog. So not even sure if there is an option to increase logging to possibly catch the issue? my iLo4 board just sees the server reset... no power cut, nothing... no hardware errors... nothing...
-
Sharing some files in case someone sees something....syslog (3)nzwhs01-diagnostics-20230623-0931.zip No reboots left but since teh last reboot to safe mode was at around 8:45, the next unexpected reboot should be around 12pm-1pm (Around the 4 hour mark.
-
3 reboots later… I will now return n in safe mode to eliminate plugins. VM service off Docker Service off Safe Mode (to eliminate plugins) So effectively the only thing the server is doing is mounting the drives in the array.
-
I additionally turned off the VM service. Now it’s a wait and see. So both docker and VM service is turned off. Array is still running but basically doing nothing. Next will be safe mode to remove possibility of plugins causing the reboot. But I will wait to see if system reboots with both VM service and Docker service turned off before booting to safe mode.
-
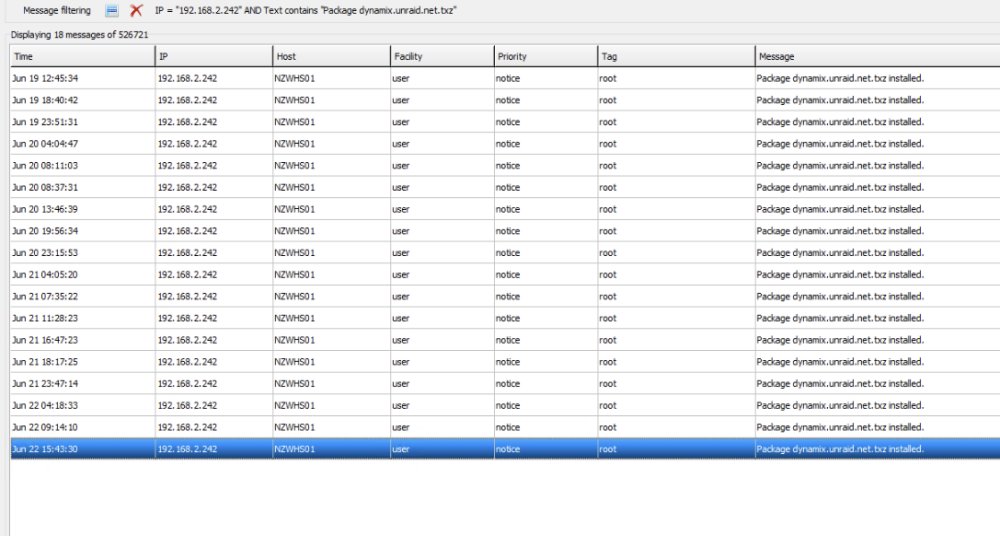
So server rebooted two times overnight. usually around the 4 hour uptime mark. i then turned off docker service and the server rebooted at 915am and then again at 1545. no apparent reason...
-
Flipped back to macvlan and then stopped all containers and the docker service, ran the Unraid Update assistant... came back clean... then Updated to 6.12.1 without issues. restarted Docker Service and all the containers are up and running again... Waiting to see if I can pass 5 hours as such. If not, then before I goto bed, I will stop the docker service as suggested and see if I can get more than the 4-5 hours of uptime
-
OK. setting it to ipvlan in the docker settings did not help... system reset again... going to update to 6.12.1.
-
I also see that 6.12.1 was released with a new kernel and bugfixes... If the ipvlan for docker does not help (trying to get more than 24 hours of up time), I will likely update to 6.12.1 so at least it won't be a question of being behind on unraid version.
-
If I stop docker... then the server is 100% going to be doing nothing..... I only run containers
-
OK. I have switched to ipvlan and will wait and see...
-
Do you think I should remain on 6.11.5 or upgrade to 6.12.0? I ask because I don't think its more or less stable and at this point wondering where I would get the best community support. Not sure if I should be going to ipvlan versus macvlan(I am currently on macvlan) as I do not seem to see any kernel panics at the moment....
-
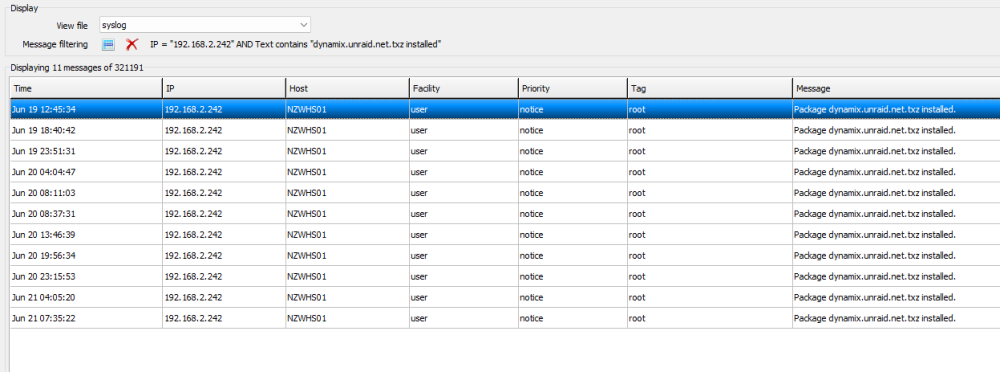
Each one of these represents a server reset. No real discernable pattern. And it seems that the stability, whether on 6.11.5 or 6.12.0 is the same. Question for the community.... should I move back to 6.12.0 and work from there as the stability seems to be the same between 6.11.5 and 6.12.0. Sadly, it was so stable before and now the rollback has kept the instability.... 😞 @JorgeB, what am I testing? So I have about 20 running containers.... if each reboot is at about the 5 hour mark, am i really going to do this for the next 100 hours?
-
syslog (2) Here is the flash syslog and the most recent diag nzwhs01-diagnostics-20230620-2006.zip
-
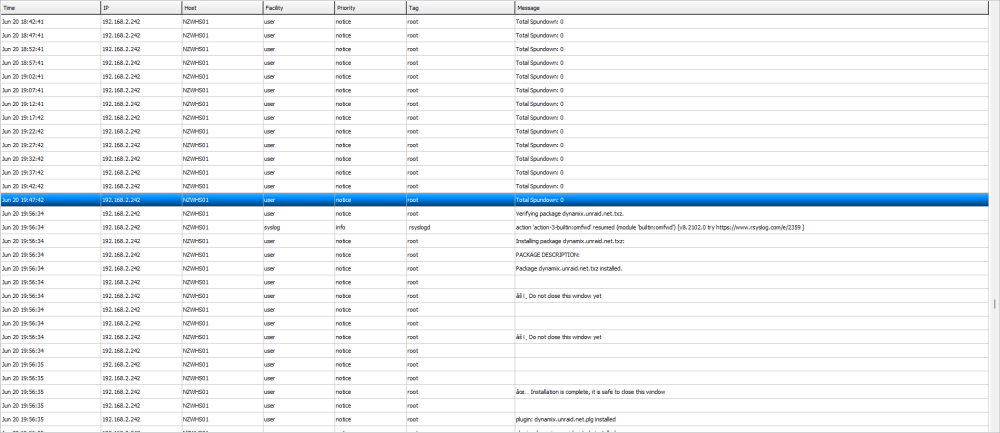
Last message is highlighted before machine reset. Logs coming as soon as I get access to file system
-
I will enable the write to flash again and remain on 6.11.5. I do not want to introduce additional variables into this... like I mentioned: 1 - Uptime of 1.5-2months 2 - Upgraded to 6.12.0 from 6.11.5 (used the update assistant) 3 - Upgrade went seemingly fine... let it soak... and was not getting more than 5 hours of uptime 4 - ran in safe mode - 5 hours max uptime 5 - through all of this, setup external syslog server and logs not showing anything prior to server reset I am pretty sure it will happen again... until then I will set the logs to write to flash and then just wait.
-
nzwhs01-diagnostics-20230620-1350.zip So not sure what is going on... prior to the upgrade, I was getting 1.5-2 months of uptime. After the upgrade, it went down to less than 5 hours. I tried running in safe mode and that did not help. I since downgraded to 6.11.5 and had some issues with some docker images so I reinstalled the problematic ones and did not see any more errors when starting them. External syslog is not showing any issues just prior to the crashes. Mirroring syslog to flash did not show anything. I have attached my diagnostics here in hopes that someone may have an idea of what i should do at this point?







