




Jaybau
Members
-
Joined
-
Last visited
-
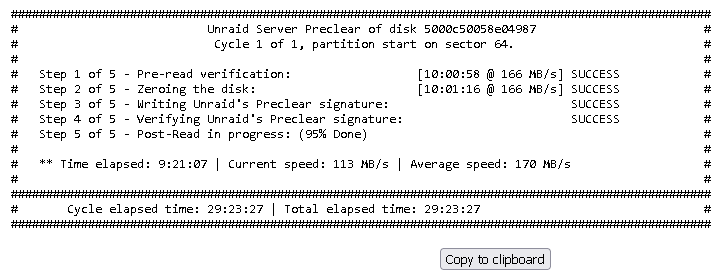
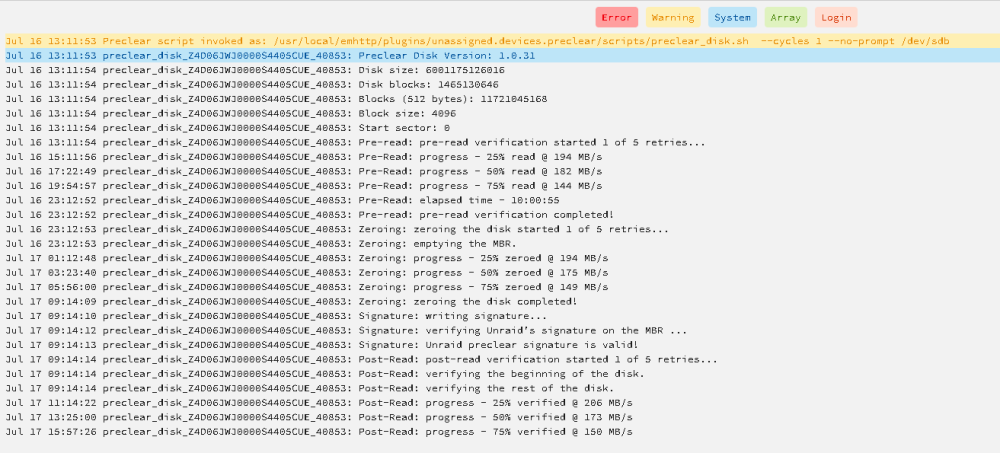
The preclear gui no longer shows the active preclear activity for a drive I'm prelearing. I did keep the preclear log window open, and it shows preclear activity, and has not yet finished.

-
What is the easiest way to find an available network port for a docker container? I have a lot of docker containers, and it's not easy to determine what network ports are available. I also use docker compose for some, and it doesn't have a "docker allocations" option.
-
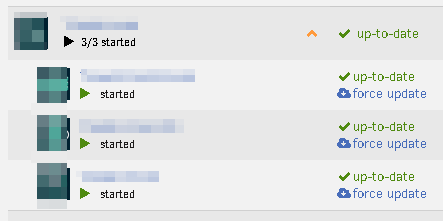
Why do some folders have the option to "force update", and others don't?
-
The progress bar does not appear correctly. It's not 98.6% complete. There's a lot more than 8 hours 40 minutes left. Uploading Attachment... Thank you.

-
What does the scale mean? Is Normal on the left of the scale, and Idle on the right side of the scale, that means Best Efforts is somewhere between Normal and Idle? Why are there so many Best Efforts? I/O Priority: Normal Best-effort 0 Best-effort 1 Best-effort 2 Best-effort 3 Best-effort 4 Best-effort 5 Best-effort 6 Best-effort 7 Idle ...I'm trying to figure out which is best to use (ideally): 1) Prioritize productivity. This is mostly read from SSD cache pool, and/or reading Plex/Jellyfin media from array for when watching a movie/show. 2) De-prioritize Dynamix Integrity check. 3) De-prioritize Parity check. 4) De-prioritize torrent client reads from array/cache. But I also have a separate pool for torrent writes which I want to have high/normal priority. Basically, I want cache moved to array as quickly/soon as possible, unless I'm the user or I need torrents moved from torrent pool to the cache... ...and since the Integrity check started, the mover is taking forever, and I assume there's competition for resources. But I won't know for sure until I see the start time and transfer rate posted to the log at the end of the move. It's also possible there's a bug. Automover is showing the mover is active, but I haven't seen the log update for a long time.
-
I get messages "File still in use after 10 attempts". I would like to know if the file cannot be moved because it is being read or written. I have large files being copied to the cache pool, which can take a long time. Is Automover aware when the file has completed being copied (no more writes), therefore won't trying to move a file off cache that is being written to? If the problem is the file is being written to, then could we have a Age Based Filter for hours to avoid trying to move files that have not completed being written to? Thank you.
-
I see the Activity Log in the top right corner displaying: Last Run 1d ago. Yet the Activity Log says (today): Session finished - 2026-04-03 16:08:00 Duration: 0s Usage below threshold — nothing to do cache usage: 39% Threshold:60% Stop Threshold:0% Plugin version: 2026.03.31.01 Session started - 2026-04-03 16:08:00 My guess is the "Last Run" only displays if 1) there was an actual move. 2) On after the run is complete. I would expect the Last Run would be based on the start date or end date (whichever is greater), regardless if files were moved or not.
-
The Activity Log search box doesn't search/filter. Clicking the "clear" button in File Moved Log doesn't clear the log. Would be nice to have a progress bar measuring files, size, and transfer rate, elapsed time, remaining time. Version 2026.03.31.01
-
Can someone please explain I/O Priority to me? Best Efforts? When/Why would I want to change from Normal? Thank you.
-
How do I keep my configuration after an Unraid reboot?
-
A docker container would be nice. Unfortunately I haven't found a good one.
-
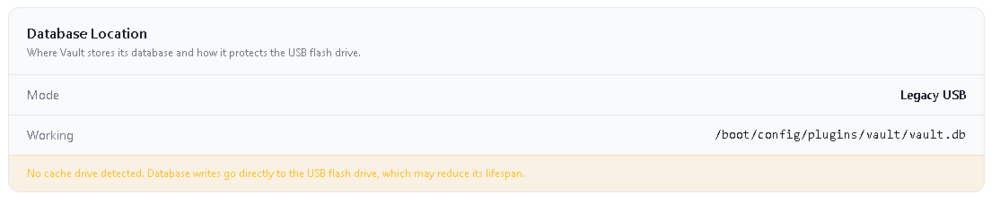
How do you change the database location? I have a mirrored SSD cache pool that isn't being detected. Uploading Attachment...
-
When I rebooted Unraid, I lost my configuration. Is that just me? Uploading Attachment...
-
Requesting an Unraid plugin for jdupes. Thank you.
-
What is the sudo password for the container? I need to install some Python utilities via PIP, and I cannot install to the folder /home/pgadmin.







