




JohnnyCache
Members
-
Joined
-
Last visited
Everything posted by JohnnyCache
-
Probably because it's just annoying. I have up on fixing it.
-
That's a good idea, thanks! I'm more interested in reinstalling/repairing them, though, since I never had any issues with any plugins until I had to do the restore. Is that possible? I'm assuming it's an issue related to this restore as opposed to a truly incompatible plugin.
-
Is there a special process to follow to do a full\clean reinstall of plugins? Reason - I swapped my mobo\cpu in my server and it wouldn't boot. I followed a help article detailing how restore my flash drive, and it started working again. Except my server started locking up at random times requiring a hard reboot. After some testing I found that it's been stable in safe mode, indicating an issue with a pluign.
-
I just double checked and I don't even have ipv6 enabled on my LAN - it's ipv4 only. The errors persist. Also worth noting I'd been running unRAID for well over a year before this started. I have no idea what was updated that started this occurrence. I had a lot of change in the time I remember it not being an issue and the time I first noticed it. Nothing crazy, but things like - Introduced Windows 11 into my environment (but clients in the log are all clients I use unRAID with) Updated all devices in my unifi stack (WAPs, switches, controller, etc) Installed several updates within unraid (plugins, Dockers, os version running latest stable) Nothing glaringly obvious was the cause. 100% started recently-ish for me though.
-
Wanted to add a quick THANK YOU for adding this detection to FCP. I've been mildly curious about why my cache drive activity always seemed low lately, figured I was just catching it ad odd times or something. Now I'm seeing a lot more activity on it
-
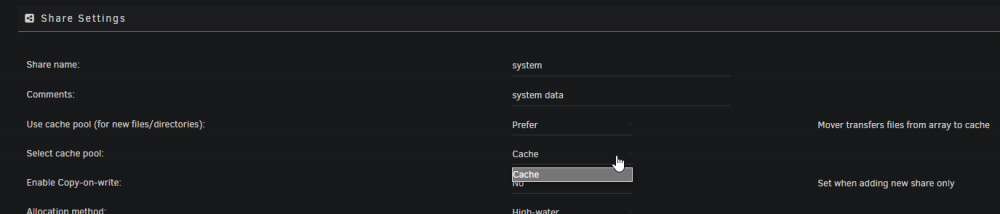
I noticed the same thing, the unraid UI showed that the cache pool was correct, and no other option existed in the dropdown. FCP stated I was using a different pool. I just did something similar: Change the "use cache pool" option to any other option, then back to what I had it set to. Did not save changes until it was set back to Prefer (setting I had initially). This made the "apply" button active. After applying the settings I rescanned in FCP and boom, errors gone. Essentially, make any change in the share settings that allows you to be able to click the Apply button and click apply. The UI showed these shares of mine as using the pool Cache but for some reason they weren't. Here's my share showing only one cache pool - And FCP notifying me about how it's using a different pool - And my one and only cache device -

-
Good Afternoon, I'd like to create a user script that monitors the duration of an appdata backup job, and notifies me if it crosses a certain runtime.. The reason is I recently had some server issues (corrupted cache drive) that (among other things) prevented dockers from responding correctly. I had an appdata backup job that was trying to run for over a week, but was hung due to the docker/cache drive issue. I was able to recover, but only from a very old appdata backup. Since the backup job technically never failed, I was not alerted. I've created a script to alert me if my appdata backups are stale, but I'd also like something to monitor my backup job runtime. Adding a runtime watchdog such as this will be part of my belt and suspenders approach to (hopefully) ensure that I never have a missing appdata backup again. I need some help with the "appdata backup job started 5 hours ago and is still running" logic for the script (see below) Where/how can I query the status of and runtime of a CA backup job? Here's what I'm envisioning - if [[ $(appdata backup job started 5 hours ago and is still running) ]]; then echo "CA Backup runtime is unhealthy" /usr/local/emhttp/webGui/scripts/notify -s "CA Backup runtime is unhealthy" -i "alert" -m "This alert was triggered by the ca_backup_time_watchdog script. Backup runtime is unhealthy" -d "A CA backup job was started over 5 hours ago and still has not completed. Check AppData backup for hung jobs or other issues." else echo "Recent CA Backup runtime is healthy" /usr/local/emhttp/webGui/scripts/notify -s "CA Backup runtimes is healthy" -i "normal" -m "Backup runtimes look good" -d "CA AppData Backup runtime is/was less than 5 hours. All is well with the cosmos." fi Any help is appreciated! Thank you
-
There may be specific solutions for different causes of this issue, but I'd like to share that I've had no issues since I followed the instructions to reformat my cache to xfs
-
Nov 9 09:24:41 nas nginx: 2021/11/09 09:24:41 [error] 27188#27188: *974740 limiting requests, excess: 20.172 by zone "authlimit", client: 192.168.1.159, server: , request: "GET /login HTTP/2.0", host: "nas", referrer: "https://nas/Docker" Nov 9 09:24:41 nas nginx: 2021/11/09 09:24:41 [error] 27188#27188: *974740 limiting requests, excess: 20.169 by zone "authlimit", client: 192.168.1.159, server: , request: "GET /login HTTP/2.0", host: "nas", referrer: "https://nas/Docker" Nov 9 09:24:41 nas nginx: 2021/11/09 09:24:41 [error] 27188#27188: *974740 limiting requests, excess: 20.166 by zone "authlimit", client: 192.168.1.159, server: , request: "GET /login HTTP/2.0", host: "nas", referrer: "https://nas/Docker" Nov 9 09:24:41 nas nginx: 2021/11/09 09:24:41 [error] 27188#27188: *974740 limiting requests, excess: 20.164 by zone "authlimit", client: 192.168.1.159, server: , request: "GET /login HTTP/2.0", host: "nas", referrer: "https://nas/Docker" Nov 9 09:24:41 nas nginx: 2021/11/09 09:24:41 [error] 27188#27188: *974740 limiting requests, excess: 20.161 by zone "authlimit", client: 192.168.1.159, server: , request: "GET /login HTTP/2.0", host: "nas", referrer: "https://nas/Docker" Nov 9 09:24:41 nas nginx: 2021/11/09 09:24:41 [error] 27188#27188: *974740 limiting requests, excess: 20.160 by zone "authlimit", client: 192.168.1.159, server: , request: "GET /login HTTP/2.0", host: "nas", referrer: "https://nas/Docker" Nov 9 09:24:41 nas nginx: 2021/11/09 09:24:41 [error] 27188#27188: *974740 limiting requests, excess: 20.158 by zone "authlimit", client: 192.168.1.159, server: , request: "GET /login HTTP/2.0", host: "nas", referrer: "https://nas/Docker" I'm still seeing these too. The weird thing is that the IP changes; this issue is not isolated to my desktop. The IP I'm seeing in my logs is from a brand new laptop with almost nothing on it other than Windows. All I did to interact with Unraid is login to the webGUI; have no shares or mapped or anything.
-
found this thread after seeing the same thing. IP is my main desktop.
-
Thanks for the tip, that makes a ton of sense. It could also explain why several others had the same issue, and why they never had it again after moving to xfs.
-
Yessss thank you for sharing this. I've guessed some of the steps but only as far as stopping the array and backing up my cache drive. I'll work through these steps tomorrow. Thank you everyone for your help! I'm still curious off btrfs relies on enterprise hardware or what could have been done to prevent this corruption to begin with. Can anyone share those details?
-
Last question; should get me going - Is there a guide available on how to convert a cache disk from btrfs to XFS?
-
Is there anything specific I should be looking for? The SSD is relatively new and does not get a ton of use. Or is it more that btrfs is expecting better ECC on the drive itself (thinking an enterprise SSD vs the off-the-shelf EVO I have)?
-
thanks for the quick reply. Dang... Do you mean just backup and re-format the cache drive only? Would the best process for this be to: 1. image the drive just in case 2. set cache=no on all shares 3. run the mover to ensure all data is moved to array 4. run appdatabackup 5. format the cache 6. restore appdata 7. restore cache setting on file shares Is there anything I need to do to to prevent this in the future? I haven't had any power failures/unclean shutdowns. Would it be worthwhile to switch to XFS as others have done?
-
Good Morning, I saw some docker issues this AM and probed around to find that my cache drive is suddenly a read-only file system. How did this happen and how can I fix it? I've searched around a bit to try to repair this but have not had any luck. I know next to nothing about BTRFS but am decent with Linux in general. the only thing that stood out to me was when running btrfs fi df /mnt/cache The numbers on Data make it look like the drive is nearly full. In other posts where users were faced with the "my BTRFS drive is full but not reporting that in the UI" issue, the size/used issue was identified in the btrfs fi show /mnt/cache command. Does that make any difference? Am I seeing the same issue? In the threads I've found, removing some data and rebalancing was the fix. But I can't rebalance due to the "read-only file system" issue. I can't even create an empty file on my cache disk - root@jonas:~# touch /mnt/cache/Logs/testwrite.log touch: cannot touch '/mnt/cache/Logs/testwrite.log': Read-only file system btrfs fi outputs: root@jonas:~# btrfs fi show /mnt/cache Label: none uuid: 06942e55-3e85-4a3d-a70a-f5d321bea2a3 Total devices 1 FS bytes used 217.21GiB devid 1 size 465.76GiB used 224.02GiB path /dev/sde1 root@jonas:~# btrfs fi df /mnt/cache Data, single: total=222.01GiB, used=216.62GiB System, single: total=4.00MiB, used=48.00KiB Metadata, single: total=2.01GiB, used=606.70MiB GlobalReserve, single: total=341.06MiB, used=0.00B root@jonas:~# btrfs balance start -dusage=5 /mnt/cache ERROR: error during balancing '/mnt/cache': Read-only file system There may be more info in syslog - try dmesg | tail Thanks for you help!!





