




shadowbert
Members
-
Joined
-
Last visited
-
That'd be right... kinda would have been nice if they hinted at it in the title. If it goes down again I'll certainly check it out though.
-
Huh. Weird design choice, but that certainly explains it. At any rate, things are looking better with this half of ram. And it's entirely possible my old set might actually still be under warranty, so that might be handy...
-
I got a screen connected. For some reason, memtest (from the unraid install) refuses to run. It just immediately restarts the computer. Ominous, but not conclusive. Going back to running unraid, with the monitor connected I can see that this shutdown is caused by a kernel panic. That certainly explains why the server simply "disappeared". Unfortunately (though unsurprisingly) the server was not kind enough to write the full details of the panic to the syslog, but it certainly helps confirm the ram theory. I've taken half of it out, to see if I can bisect which one is giving me grief. Fingers crossed. Thanks for pointing me in the right direction.
-
Alright. I'll need to find a way to get a screen connected then.
-
That makes sense... though it is certainly concerning. Would the (now removed) SSD that was throwing those CRC be a possible cause?
-
Really? I had assumed that a power outage that happened to occur when something is written to disk A but not disk B would cause that sort of issue... or is btrfs somehow smarter than that?
-
I highly suspect it's more likely to be due to the sudden shutdowns than ram. Running memtest is going to be tricky given that I don't have any display outputs on that machine... What should I do to clean up the corruption, assuming RAM isn't the issue?
-
Sure, here you go. lime-diagnostics-20231021-1923.zip
-
Alright, so I haven't had it completely lock up since posting, but I have had docker grind to a halt at least 3 times. Looks like I have BTRFS errors for days in the logs. So I guess there's something wrong with my cache. One of the drives do have a CRC error count value of 133... so I'm guessing I should try ripping that out and seeing if it helps.
-
Never mind, I worked it out. I had to set the server to use itself as the remote server.
-
Fair call. Is this all I need to do for that? Nothing came up in the share yet...
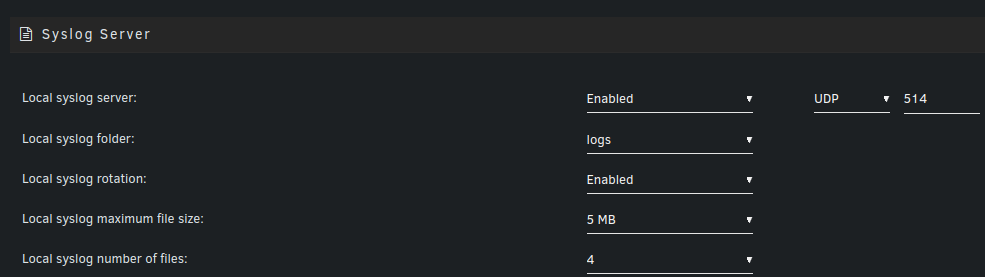
-
I don't even know where to start with this one, but it's a real pain. The server will simply stop responding to any traffic and, because it's headless (no gpu, no display ports on motherboard), I have no choice but to cold restart. You may note that drive 5 is missing. This drive had quite a lot of smart errors, so I took it out to see if that was somehow causing issues. Ideally I would think that drives misbehaving may result in it getting disabled (and certainly shouldn't take out the server), but it doesn't seem to have helped. lime-diagnostics-20231013-0844.zip
-
Right.. so I might be able to control it via the terminal if I match this name somehow? The specific stack I'm using (mailcow) has a special update script which does a little more than just pull/restart the containers, so I guess that means this plugin isn't going to work that well in my usecase... Oh well, at least it gets compose installed in a nice and easy way.
-
I'm a bit confused. Everything seems to be working well - but the UI and the command line don't seem to agree on what containers are running. That is, if I run `docker compose up -d`, the webui still thinks everything is donw. If I press "up" on the webui, the docker compose logs -f gives me nothing (as does docker compose ps) If I do both, I get two sets of the same containers. Is this a known thing? Or has something gone crazy wrong on my end?
-
I just installed this for the first time - and novnc doesn't start. The rest seems ok, but I'm unable to connect to port 8083. In the docker logs I note the following; > 022-07-31 23:57:28,170 INFO exited: audiostream (exit status 111; not expected) > 2022-07-31 23:57:29,252 INFO exited: novnc (exit status 1; not expected) Everything else seems ok, but those two processes attempt to start and fail in the same way a few times until supervisord gives up on them. Anyone else seeing something like this?

