tTIKA
Members
-
Joined
-
Last visited
Everything posted by tTIKA
-
Hi, I know this plugin can be turned off or on easily but when its running, everyone in the network can see all the file names in the entire server by going to [server ip]:7090. Is there any way to put this plugin behind a password. Although no file content is exposed this seems to be a big issue.
-
Hi all, I’m on Unraid 7.2.3 and checking the container runtime shows this: root@f:~# runc --version runc version 1.2.4 commit: v1.2.4-0-g6c52b3f spec: 1.2.0 go: go1.22.11 libseccomp: 2.5.4 There were several SEVERE runC container escape vulnerabilities that could let containers gain root access to whole system in November 2025 ( CVE-2025-31133, CVE-2025-52565 , CVE-2025-52881) and upstream mentions fixes in later runC releases (1.2.8+). Questions: Is Unraid 7.2.3 actually vulnerable because it ships runc 1.2.4, or are these fixes backported in some way? If backported, is there a way to verify this to in patch notes,etc? If not backported, is there an ETA or recommended mitigation on Unraid (beyond “avoid untrusted containers”)? just trying to confirm whether this is a real exposure on Unraid. Thanks
-
I am replacing a 4TB disk with a 24 TB one. I always do a pre-clear and read before adding new disk to the array. But even when the new disk has already been fully precleared/verified as zero, the rebuild still writes the entire 24TB end-to-end, including the portion beyond the original disk size that will reconstruct as zeros. Can we please add a “skip confirmed-zero regions” / “fast rebuild for larger replacement disks” mode so we get faster rebuilds when upgrading capacity (less wear, less time at degraded protection, less array load). I assume this would require the rebuild to be done in maintenance mode for safety, but I think its a fair compromise. Thanks
-
Finally upgraded from Unraid v6 to v7 and I’m running into issues. Please Help! Current issue: If I turn off the Docker service in Settings and click Apply, the entire server freezes: no web UI, no shares, no SSH. I have to hold the power button to force a shutdown. Background (possibly relevant): I shut the server down in May before a trip. Two days ago I powered it back on (still on the latest v6), then upgraded to v7. It booted fine. On the Docker page I clicked Update All; it failed. Investigation showed my BTRFS RAID1 cache was corrupted and had mounted read-only (seems somewhat common). I had a CA Appdata Backup, so I reformatted the cache drives to ZFS and restored appdata with the plugin. Containers work fine, but the freeze happens every time I stop the Docker service. I need to stop/start Docker to troubleshoot an unrelated network issue and adjust container network settings. So… the upgrade hasn’t been smooth. Diagnostics after a fresh boot attached. fatma-diagnostics-20250907-1207.zip
-
Thanks, but why would I be getting so many parity errors? Anything wrong in the diagnostics you see?
-
TLDR: Does the running XFS_REPAIR in the UI also reflect the changes in parity or would I need to run a parity check to update? The whole issue: I booted up my server after a long vacation and one of the disks in the array was unmountable. It is an encrypted xfs. I did some trouble shooting and got it working after running the xfs_repair in the UI and some re plugging of sata cables. I did start a parity check afterwards. (I was gonna do it anyway since it has been a while). Around %15 in, I noticed around 5MB of updates to the parity. I expected some after the repair but that seems too much. I did some digging and noticed that I now have a lost+found folder in the disk. (I know what is it now, but didin't know at the time) The bad news is, I found most of the files in there are random files for my Encrypted Time Machine backups of my various Macs at the house. I was able to tell because Time machine splits them up in fixed sized chunks. But there is no way that I know of to put them back since the file names are gone. So I want to restore this and start again, if I can. Should A) I just rebuilt the disk from parity? I understand that %15 of the new stuff is already written. But would this leave things in a limbo? B) Or does the parity already have updated with the results of the xfs_repair? if it did, why did I got so many errors? C) Or should I just let the parity check run and salvage whatever I can? Thanks for any help here fatma-diagnostics-20230802-2050.zip
-
fatma-diagnostics-20220705-1934.zip
-
Just trying find out if this is intended behavior: I have a disk mounted with Unassigned Drives plugin. I am trying to copy its contents to the array. The command I used is: cd /mnt rsync --progress -ra disks/Y5J326NC/BerkesHDD/ user/ManuelBackup/BerkesHDD/ However, rsync fails when my cache is full: 2,457,600 7% 2.23MB/s 0:00:12 rsync: [receiver] write failed on "/mnt/user/ManuelBackup/BerkesHDD/sd_cards/2018 all nikon z6/Simla Shoot/DSC_0442.NEF": No space left on device (28) rsync error: error in file IO (code 11) at receiver.c(378) [receiver=3.2.3] rsync: [sender] write error: Broken pipe (32) rsync error: error in file IO (code 11) at io.c(823) [sender=3.2.3] But my settings for that device should start writing directly to the array when the cache is full? Why would this happen? I know I can bypass cache by using user0 instead but I want to know why this is the case.
-
I just unassigned and re assigned the second drive and let btrfs do its thing again. But for future reference and may be helping others: What would cause this? Is there an other way to fix it? And where to look in the diagnostics? and if it matters hers the output now: root@fatma:~# cryptsetup luksOpen /dev/nvme0n1p1 nvme0n1p1 Device nvme0n1p1 already exists.
-
Just updated unraid directly from the 6.9.2 to 6.10.2. Now the btrfs cache with 2 disks doesn't work. It says "Unmountable: Volume not encrypted". Tried restarting the array but didn't work. Not sure what to do other than formatting. fatma-diagnostics-20220601-1219.zip
-
Updated both the BIOS and Firmware using the excellent guide here: Do you know what the setting "Boot Support" in the cards BIOS does?
-
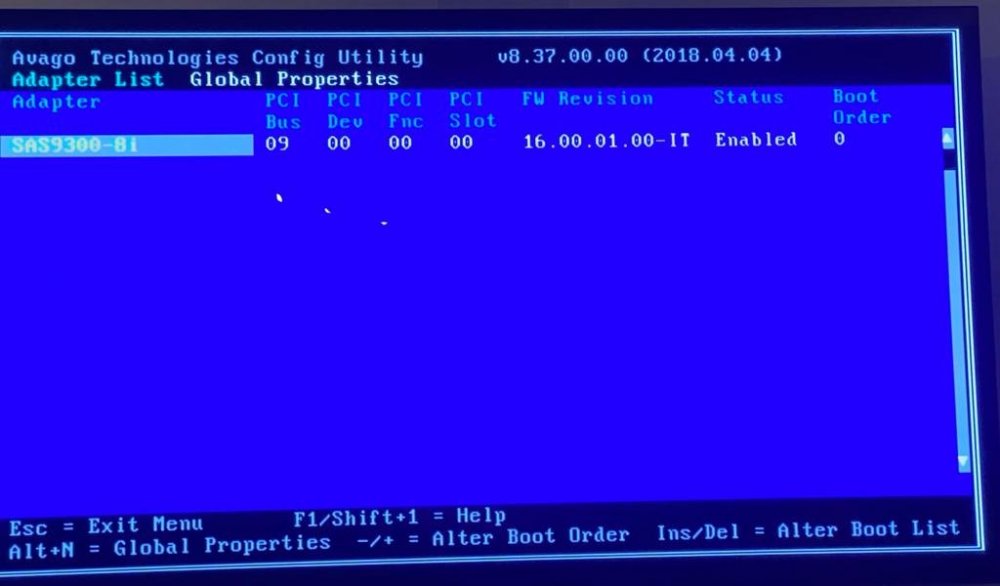
Thank you for the help! The missing disk was on purpose. My array drives are connected to a LSI board because with two M.2s (my btrfs raid 1 cache pool) my motherboard wont let me use all the onboard sata ports. I temporally took one of the SSDs out to use all the onboard Sata ports for testing. So my questions are: If something like this happens again, is there a way to gracefully shut down the system without holding the power button? (linux commands from ssh didnt work) Add my LSI card is very new. Could that be causing issues like this? I'm adding its details below. It's it came in IT mode and I haven't done anything to it
-
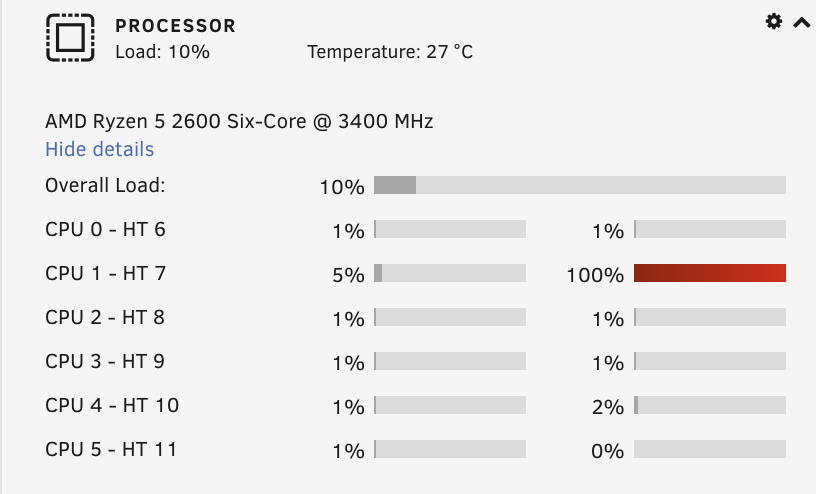
I messed something up (probably about the docker service) and my server is now messed up. Turning on the docker service (by which I mean when setting Enable Docker to Yes in settings when the array is on) will make the system somewhat unresponsive. Some pages will takes ages to load, sometimes fix common problems will get stuck etc. But this is inconsistent. What is consistent is after turning docker on I wont be able to turn off some containers. (that has been working perfectly for over a year and I haven't touched them). This will in turn will make me un able to stop the array and shut down the server, requiring a hard restart. The server will never fully freeze and I am able to ssh in to it. But no linux shutdown/halt command I found online or killing docker processes will do anything. I tried pretty much everything I could find in this forum. Lastly I tried formatting my USB drive and only copying or my plug-ins and configs for the shares, users, passwords etc. Nothing docker related. Then I set it up linuxservers Plex docker. It worked perfectly fine. But then I tried to stop it in the UI, and my system went back to that state again. Every time I clicked on stop it will show the arrows the UI but after 10 minutes I would refresh the page and the containerwould still show as running. I worked on this for 3 days straight now and about to loose it. Please help me. fatma-diagnostics-20220115-1918.zip
-
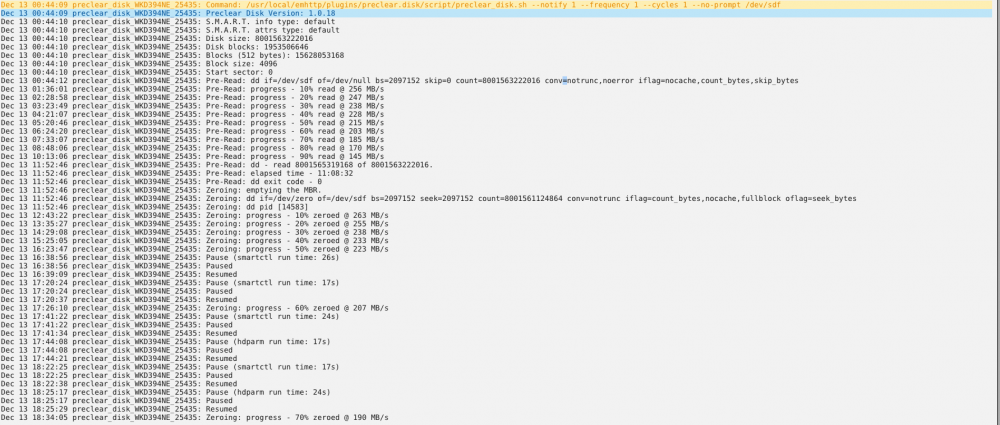
Need some help with 2 new drives. A WD red plus drive was making a clicking sound during pre read phase. The click itself didn't sound abnormal for a dive(this is my 6th WD red, so i am familiar with how they sound, but first plus drive) but the click was happening exactly once a second like a clock. Pre read completed successfully. After pre read, clicking stooped. An other drive I just bought (a seagate ironwolf if matters) also passed pre clear. Put in the logs section I see the line: Dec 13 14:50:07 preclear_disk_VDKAS47P_25498: Pre-Read: dd - read 8001565319168 of 8001563222016. since the numbers don't match should I be alarmed? (full log posted below) This is my first post on the forums, since I always try to solve things by my self first, but the pre-clearing (especially pre reading) issues seems to be not very discussed online. Any help appreciated! Full Logs: