Fulgurator
Members
-
Joined
-
Last visited
-
Same thing just happened to me... I guess this means my flash drive is on its last legs because AFAIK nobody writes to this drive except Unraid during version upgrades, and the last Unraid upgrade dates back to December last year and the system booted just fine a couple of times since then. For the fun of it I did a binary compare of the bzfirmware files and there was a 4K block near the end that was completely corrupted. Note that for the longest time (years!) I had bad blocks flagged at boot (like in this thread) which I assumed were the result of an Unraid upgrade, maybe this was related.
-
No issues from me except what I already reported earlier (array startup issues) and turned out to be unrelated to 6.11.5. No perf issues from Sab (nor any other Docker container) on my side either.
-
In case it's important, the problematic drive still had a v1 free space cache, it was created long ago. I looked into converting it to a v2 space cache but that requires recreating the filesystem or tweaking the mount command, so I probably won't bother doing it. My other btrfs drive used for the pool cache was already on v2.
-
Before rebooting again I noticed that some of the CPUs were always pinned to 100% while stuck waiting for the array to start, and looking at the running processes again pointed to a btrfs issue. It turns out I had a second btrfs drive, an NVMe SSD which was mounted via Unassigned Devices that I had missed. Booting again in safe mode and clearing the btrfs free space tree in the terminal (as you initially suggested), and rebooting again normally fixed the problem I saw with 6.11.5. The Kernel crash is also gone from the syslog. This also explains why downgrading did not fix the issue... Looks like I was indeed just that unlucky! Thanks!

-
So. The btrfs check commands did not help, I still see the same Kernel crash in the syslog when booting normally. The only way I can start the array since the 6.11.5 upgrade is to boot in safe mode.
-
I'll try that later if normal boot doesn't work, thanks!. The question is though, why did this happen during an upgrade and why does it persist through downgrades? Am I just that unlucky? (same with @NNate it would seem!) Looking at the Main page it looks like I am only using btrfs for a cache drive. I don't remember making a filesystem choice when I set this up, but it's been running trouble-free for so long I could have just forgotten and just picked whatever was the default at the time.
-
Interestingly, searching for "btrfs-cache btrfs_work_helper" yields the same callstack in the Linux Kernel mailing list: https://lore.kernel.org/linux-btrfs/e1cde76ba6cf7b14d6f38310113588d6486d5a00.1659989333.git.josef@toxicpanda.com/ Not sure if related but it sure seems suspicious.
-
Looks like I just forgot to scroll and only saw the big orange button on the top right. Anyway downgrading isn't really the issue here, but I'll remember next time. Thanks! Parity check is already halfway done, so tomorrow I should be able to reboot again normally and see if I "hang" starting the array again. The system "works" (UI is not frozen, shell works, etc) but of course anything requiring the array is down, and trying to reboot the system normally (or generating Diagnostics logs) stalls forever.
-
For what it's worth, there doesn't seem to be an easy way to downgrade to 6.10.3 from 6.11.2. First the download link always points to the latest version, but even editing the .plg to point to the old 6.10.3 version & Linux kernel, failed a manual plugin install ("not installing old version"). In the end I had to reinstall 6.11.5 again. In any case, booting the system in safe mode allows the array to start just fine. I am now going through a forced Parity check (which should take a couple of days), likely caused by the multiple hard shutdowns I was forced to do to regain control of the system
-
I upgraded without thinking much, and this update appears to have killed my setup, something crashes in the kernel when starting the array: [ 143.967784] rcu: INFO: rcu_preempt self-detected stall on CPU [ 143.967787] rcu: 2-....: (59996 ticks this GP) idle=caf/1/0x4000000000000000 softirq=7170/7170 fqs=14996 [ 143.967802] (t=60000 jiffies g=16485 q=749575 ncpus=8) [ 143.967804] NMI backtrace for cpu 2 [ 143.967806] CPU: 2 PID: 58 Comm: kworker/u16:2 Not tainted 5.19.17-Unraid #2 [ 143.967808] Hardware name: ASUS All Series/Z97-A, BIOS 2801 11/11/2015 [ 143.967810] Workqueue: btrfs-cache btrfs_work_helper [ 143.967816] Call Trace: [ 143.967819] <IRQ> [ 143.967821] dump_stack_lvl+0x44/0x5c [ 143.967825] nmi_cpu_backtrace+0xda/0x104 [ 143.967838] ? lapic_can_unplug_cpu+0x95/0x95 [ 143.967842] nmi_trigger_cpumask_backtrace+0x72/0x107 [ 143.967854] trigger_single_cpu_backtrace+0x2a/0x31 [ 143.967858] rcu_dump_cpu_stacks+0xa0/0xd6 [ 143.967861] rcu_sched_clock_irq+0x44b/0xaf7 [ 143.967864] ? perf_event_task_tick+0x5e/0x1e3 [ 143.967869] ? tick_nohz_restart_sched_tick+0x83/0x83 [ 143.967871] update_process_times+0x62/0x81 [ 143.967874] tick_sched_timer+0x43/0x71 [ 143.967876] __hrtimer_run_queues+0x110/0x1b7 [ 143.967879] hrtimer_interrupt+0x9c/0x16e [ 143.967882] __sysvec_apic_timer_interrupt+0xc5/0x12f [ 143.967885] sysvec_apic_timer_interrupt+0x80/0xa6 [ 143.967888] </IRQ> [ 143.967889] <TASK> [ 143.967890] asm_sysvec_apic_timer_interrupt+0x16/0x20 [ 143.967893] RIP: 0010:native_queued_spin_lock_slowpath+0x7f/0x1d0 [ 143.967897] Code: 0f ba 2b 08 8b 03 0f 92 c2 0f b6 d2 c1 e2 08 30 e4 09 d0 3d ff 00 00 00 76 0c 0f ba e0 08 72 1e c6 43 01 00 eb 18 85 c0 74 0a <8b> 03 84 c0 74 04 f3 90 eb f6 66 c7 03 01 00 e9 32 01 00 00 e8 0f [ 143.967899] RSP: 0018:ffffc90000257c60 EFLAGS: 00000202 [ 143.967901] RAX: 0000000000000101 RBX: ffffc90000257cc8 RCX: 0000000000b83f02 [ 143.967902] RDX: 0000000000000000 RSI: 0000000000000001 RDI: ffffc90000257cc8 [ 143.967904] RBP: ffff888102fadd90 R08: 0000000000000000 R09: 0000000000000200 [ 143.967905] R10: ffff888102fadd90 R11: 0000000000030d80 R12: 0000000000000001 [ 143.967906] R13: ffff88816b309018 R14: ffff888166ad4000 R15: 000000003772a000 [ 143.967910] do_raw_spin_lock+0x14/0x1a [ 143.967912] __btrfs_remove_free_space_cache+0xe/0x2d [ 143.967916] load_free_space_cache+0x230/0x2dd [ 143.967919] ? kmem_cache_free+0xdb/0x176 [ 143.967925] caching_thread+0x7e/0x43d [ 143.967929] ? raw_spin_rq_unlock_irq+0x5/0x10 [ 143.967932] ? finish_task_switch.isra.0+0x140/0x21c [ 143.967936] btrfs_work_helper+0x114/0x2a5 [ 143.967940] process_one_work+0x1ab/0x295 [ 143.967943] worker_thread+0x18b/0x244 [ 143.967945] ? rescuer_thread+0x281/0x281 [ 143.967947] kthread+0xe7/0xef [ 143.967950] ? kthread_complete_and_exit+0x1b/0x1b [ 143.967952] ret_from_fork+0x22/0x30 [ 143.967957] </TASK> Unfortunately this seems severe enough that I cannot extract diagnostics from the system (hangs during collection), pressing Reboot in the UI does not reboot, issuing "shutdown -r now" in the console does not reboot, etc. My only option is to "yank the plug" so to speak and try again. I will need to try safe mode. I managed to downgrade to 6.11.2 (which was the previous version on the USB stick) through the UI but the problem remains the same, it hangs forever while starting the array. I am not ruling out a hardware issue, because the downgrade should have fixed it? I will try to downgrade further, maybe go back to 6.10.x.
-
I know this is a very old post but I haven't seen this answered anywhere. I managed to run protected TeknoParrot games under a VM by editing the VM in XML view and adding the following inside the <domain> section: <qemu:commandline> <qemu:arg value='-cpu'/> <qemu:arg value='host,kvm=off,hv_vendor_id=null,-hypervisor'/> </qemu:commandline> Hope this helps! Cheers, Ben.
-
Thanks, changing it back to what I had (and moving back my VMs & Docker paths to their preferred spot...) solved it, I should have paid more attention when setting up UD long ago. Now that I've specified an explicit mount point, the next time the default changes I won't be affected. Cheers! Ben.
-
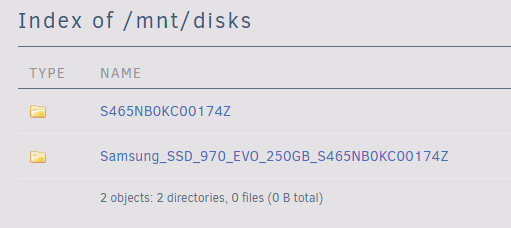
Hello fellow Unraid users! Yesterday I had to restart my Unraid server and found that my autostart VM no longer worked. After some troubleshooting I found that the issue was that the disk image could no longer be found, and the reason for that is because the unassigned device I was using changed its name for an unknown reason after a restart. Is this normal? I guess the better question is, why do both paths still exist? It looks like some of the directory hierarchy is left in the original path, but the content is gone and only available from the new path. Did I just miss an update message with the Unassigned Devices plugin? Cheers, Ben. PS: I posted this in General Support first but it was not appreciated...
-
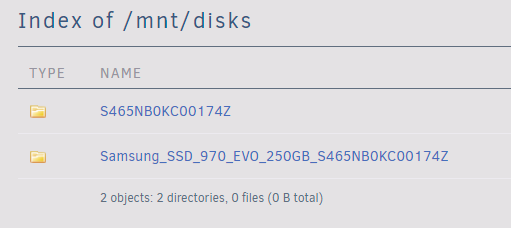
Hello fellow Unraid users! So yesterday I had to restart my Unraid server and found that my autostart VM no longer worked. After some troubleshooting I found that the issue was that the disk image could no longer be found, and the reason for that is because the unassigned device I was using changed its name for an unknown reason after a restart. Is this normal? I guess the better question is, why do both paths still exist? It looks like some of the directory hierarchy is left in the original path, but the content is gone and only available from the new path. Did I just miss an update message with the Unassigned Devices plugin? Cheers, Ben.