




Everything posted by [email protected]
-
I've moved all the files not on cache manually. I rebooted then turned docker back on and Boom, all my containers were back and working. Thanks for all your help JorgeB
-
Looks like appdata have alot of symlinks including some of the files that are not moving. I couldnt find a command to list all files with hardlinks within a directory
-
I've not changed anything from the out of box setup from Unraid in that regard. I'll check when I'm back home if there are any symlinks within the appdata location
-
media-diagnostics-20221116-2020.zip
-
I've rerun Mover with logging now enabled. New diagnostics attached The share is still showing some appdata content on array disks. but only a few bytes on 1 drive and a few KB on the other. There are a few SVG files deep in the Krusader directory, a cookie file in the QdirStat dir and a mongodb-27117.sock file under unifi controller. Could I manually move these files over manually? TBH, other than maybe the unifi controller file, the rest are not important and I can redeploy those later if needed. media-diagnostics-20221116-2020.zip

-
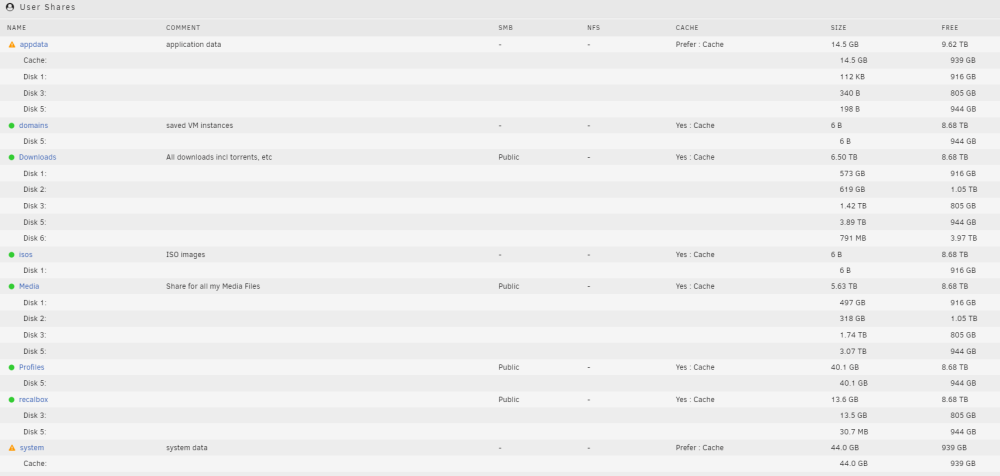
I've done the same as last time, and set appdata and system shares to Cache = yes and run Mover. I've rebooted and grabbed latest diag. and here is the current shares Is an option to replace the Docker image with the one from the old Cache drive as I do still have the old smaller drive? media-diagnostics-20221115-1734.zip
-
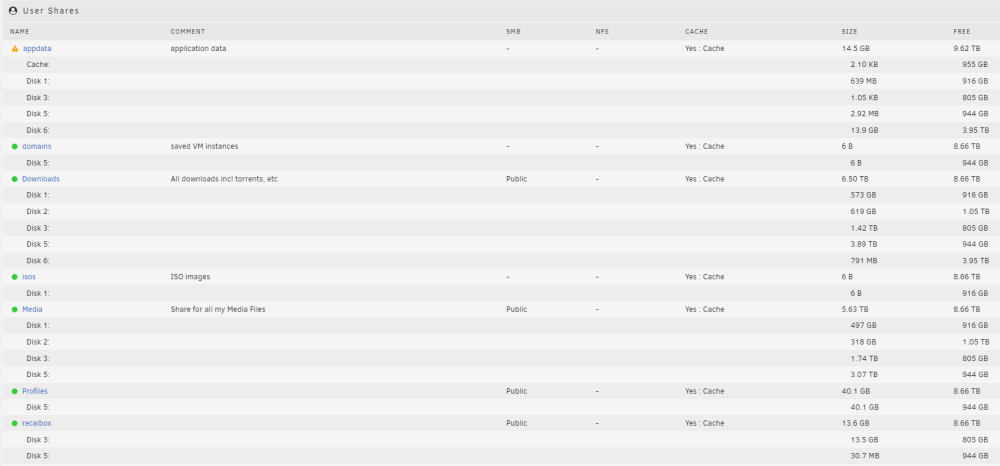
Hi @JorgeB, Thanks for the continued help on this. I did change the shares to Cache Yes and Ran mover. So the logs and screenshots are after doing that change. New logs attached and screenshot as requested. media-diagnostics-20221115-0039.zip

-
No, happy to try that if you think it will help. DO I set all drive back to cache Yes, run mover , format, than cache to Prefer or No, run mover.
-
I've run the diagnostics from the command line instead of the web GUI which are now attached. This was before the reboot. and I've also completed the reboot and attached the new syslog. media-diagnostics-20221113-0153.zip syslog
-
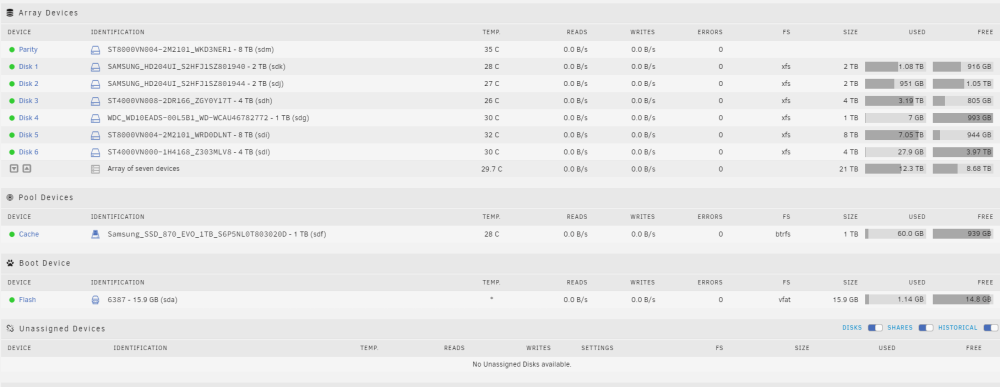
Thanks for confirming. Syslog attached. Also here is my drive config as you may not see what you need from syslog syslog
-
I've just upgraded my cache drive following these instructions found here Stop all running Dockers/VMs Settings -> VM Manager: disable VMs and click apply Settings -> Docker: disable Docker and click apply Click on Shares and change to "Yes" all cache shares with "Use cache disk:" set to "Only" or "Prefer" Check that there's enough free space on the array and invoke the mover by clicking "Move Now" on the Main page When the mover finishes check that your cache is empty (any files on the cache root will not be moved as they are not part of any share) Stop array, replace cache device, assign it, start array and format new cache device (if needed), check that it's using the filesystem you want Click on Shares and change to "Prefer" all shares that you want moved back to cache On the Main page click "Move Now" When the mover finishes re-enable Docker and VMs When I re-enabled Docker, it was empty. I say a comment on another thread that you can just re-add them via CA previous apps. I tried this with a single docker and after the reinstall, the docker was running the default config not the config it was running before the upgrade. Before I try anything else and possibly make things worse does anyone have any wisdom that could get me out of this hole. I'm generating the diagnostics now, does it normally take a long time? Been running about 30 minutes so far.
-
Hi All, I need some help. I just updated my Plex media server docker. I didnt take note of the old or new versions. Since the update, when I restart the container, the webUI is available for less than 1 minute. by the time I login I only get the following in the browser " This page isn’t working right now 192.168.X.X didn’t send any data. ERR_EMPTY_RESPONSE " I tried updating my Unraid to 6.10.1 and all plugins no change. I've stopped all other containers which also no change. Container and Unraid have been rebooted multiple times. Any and all help appreciated Here are the logs from a restart to when the UI fails: 2022-05-27 20:05:43.605456 [info] Host is running unRAID 2022-05-27 20:05:43.648341 [info] System information Linux Media 5.15.40-Unraid #1 SMP Mon May 16 10:05:44 PDT 2022 x86_64 GNU/Linux 2022-05-27 20:05:43.696161 [info] OS_ARCH defined as 'x86-64' 2022-05-27 20:05:43.745276 [info] PUID defined as '99' 2022-05-27 20:05:43.800075 [info] PGID defined as '100' 2022-05-27 20:05:43.861897 [info] UMASK defined as '000' 2022-05-27 20:05:43.910614 [info] Permissions already set for '/config' 2022-05-27 20:05:43.959139 [info] Deleting files in /tmp (non recursive)... 2022-05-27 20:05:44.013444 [info] TRANS_DIR defined as '/tmp' 2022-05-27 20:05:44.066548 [info] Starting Supervisor... 2022-05-27 20:05:44,334 INFO Included extra file "/etc/supervisor/conf.d/plexmediaserver.conf" during parsing 2022-05-27 20:05:44,335 INFO Set uid to user 0 succeeded 2022-05-27 20:05:44,338 INFO supervisord started with pid 8 2022-05-27 20:05:45,341 INFO spawned: 'plexmediaserver' with pid 65 2022-05-27 20:05:45,345 INFO spawned: 'shutdown-script' with pid 66 2022-05-27 20:05:45,346 INFO reaped unknown pid 9 (exit status 0) 2022-05-27 20:05:46,348 INFO success: plexmediaserver entered RUNNING state, process has stayed up for > than 1 seconds (startsecs) 2022-05-27 20:05:46,348 INFO success: shutdown-script entered RUNNING state, process has stayed up for > than 0 seconds (startsecs) 2022-05-27 20:06:33,967 DEBG 'plexmediaserver' stderr output: libc++abi: terminating with uncaught exception of type std::bad_cast: std::bad_cast 2022-05-27 20:06:36,504 DEBG 'plexmediaserver' stderr output: ****** PLEX MEDIA SERVER CRASHED, CRASH REPORT WRITTEN: /config/Plex Media Server/Crash Reports/1.26.2.5797-5bd057d2b/PLEX MEDIA SERVER/7c89788c-4091-4c38-a6b0ab8f-f050f596.dmp 2022-05-27 20:06:37,506 DEBG fd 8 closed, stopped monitoring <POutputDispatcher at 22722773641792 for <Subprocess at 22722773636560 with name plexmediaserver in state RUNNING> (stdout)> 2022-05-27 20:06:37,507 DEBG fd 10 closed, stopped monitoring <POutputDispatcher at 22722773641744 for <Subprocess at 22722773636560 with name plexmediaserver in state RUNNING> (stderr)> 2022-05-27 20:06:37,507 INFO exited: plexmediaserver (terminated by SIGABRT; not expected) 2022-05-27 20:06:37,508 DEBG received SIGCHLD indicating a child quit 2022-05-27 20:06:37,510 INFO spawned: 'plexmediaserver' with pid 211 2022-05-27 20:06:38,512 INFO success: plexmediaserver entered RUNNING state, process has stayed up for > than 1 seconds (startsecs)
-
Hi Everyone, I'd like your feedback on which CPU option to go with. I currently have a single Xeon E5-2680 (2.7GHz, 8c 16t) which does an OK job running Unraid mainly for Plex. I have a GTX card doing transcoding. I got a dual Xeon workstation for free which has dual E5649 CPU's (2.5GHz, 6c 12t each). Would the higher core count of the dual CPU's be worth migrating too, or is the slightly higher clock speed of more benefit? Assume all other parts of the machine are the same. Thanks for your input
-
Ah, I think you picked the issue. It is a Quadro 600 not a P600. Just grabbed an HP Z240 out of the cupboard thinking it would have something reasonable in it, but didn't check close enough. I'll have a look for another card laying around I can use. Thanks for the help.
-
So I'm an Unraid Noob trying to get Plex HW transcoding working with an Nvidia P600. I've followed the above steps from @yogy but I just keep getting the following message: "NVIDIA-SMI has failed because it couldn't communicate with the NVIDIA driver. Make sure that the latest NVIDIA driver is installed and running." I haven't set it to pass it through to the container yet. Any help appreciated, Thanks





