




OneMeanRabbit
Members
-
Joined
-
Last visited
Everything posted by OneMeanRabbit
-
root@tower:/boot/syslinux# fdisk -l /dev/sdh Disk /dev/sdh: 12.73 TiB, 14000519643136 bytes, 3418095616 sectors Disk model: ST14000NM001G-2K Units: sectors of 1 * 4096 = 4096 bytes Sector size (logical/physical): 4096 bytes / 4096 bytes I/O size (minimum/optimal): 4096 bytes / 4096 bytes Disklabel type: gpt Disk identifier: 4F70D89C-52AE-6843-A532-A5B5765B03B7 Device Start End Sectors Size Type /dev/sdh1 2048 3418077183 3418075136 12.7T Solaris /usr & Apple ZFS /dev/sdh9 3418077184 3418093567 16384 64M Solaris reserved 1 Here is the proper command, thanks for clarification. Regarding the import process in 7.1.4, I'm not wanting to have an array. Are your steps the same in that scenario - I tried this on 7.0 and I named it the same name as my zfs pool and it failed to import saying there was something there with the same name - I think? In other systems, I wouldn't normally create anything just do zfs import {exported pool} Thank you @JorgeB for your support and on a weekend at that!
-
Will do, anyway to automate that headlessly? Can I just move the gui safemode to the first location in syslinux.conf? EDIT Looks like just moving "menu default" from unraid OS to Unraid OS safe mode should work. Once I can boot up in safe mode, should I just delete the connect plugin? I don't really use it as I use my own certs and reverse proxy with vpn. the backup flash is nice though.
-
Fatal error: Uncaught Error: Call to undefined function var() in /usr/local/emhttp/plugins/dynamix.my.servers/include/state.php:144 Stack trace: #0 /usr/local/emhttp/plugins/dynamix.my.servers/include/state.php(130): ServerState->getWebguiGlobal('notify', 'unraidos') #1 /usr/local/emhttp/plugins/dynamix.my.servers/include/myservers2.php(15): ServerState->_construct() #2 /usr/local/emhttp/plugins/dynamix/include/DefaultPageLayout.php(593): include('/usr/local/emht...') #3 /usr/local/emhttp/plugins/dynamix/template.php(82): require_once('/usr/local/emht...') #4 {main} thrown in /usr/local/emhttp/plugins/dynamix.my.servers/include/state.php on line 144 seems like something iwth unraid API...? Jul 13 02:04:06 tower root: Starting Nginx server daemon... Jul 13 02:04:06 tower root: Starting Unraid API service... Jul 13 02:04:06 tower root: Backup file not found at '/boot/config/plugins/dynamix.my.servers/node_modules-for-v4.9.5.tar.xz'. Skipping restore. Jul 13 02:04:07 tower root: #033[32m[Nest] 25490 - #033[39m07/13/2025, 2:04:07 AM #033[32m LOG#033[39m #033[38;5;3m[PluginService] #033[39m#033[32mLoaded 0 plugins.#033[39m Jul 13 02:04:07 tower root: #033[95m[Nest] 25490 - #033[39m07/13/2025, 2:04:07 AM #033[95m DEBUG#033[39m #033[38;5;3m[PluginCliModule] #033[39m#033[95mFound 0 CLI plugins: #033[39m Jul 13 02:04:07 tower root: Starting the Unraid API Jul 13 02:04:08 tower root: ExecaError: Command failed with exit code 127: /usr/local/unraid-api/node_modules/pm2/bin/pm2 start /usr/local/unraid-api/ecosystem.config.json --update-env Jul 13 02:04:08 tower root: Jul 13 02:04:08 tower root: /usr/bin/env: 'node': No such file or directory Jul 13 02:04:08 tower emhttpd: shcmd (24): /etc/rc.d/rc.flash_backup start Jul 13 02:04:08 tower flash_backup: flash backup disabled, exiting Jul 13 02:04:08 tower emhttpd: shcmd (24): exit status: 1 I set it to autostart array so at least I can have my dockers up. Eveyrthings up except the gui. tower-diag-20250713-0129.zip
-
root@tower:~# zpool status -LP pool: hdd state: ONLINE scan: scrub repaired 0B in 1 days 03:31:50 with 0 errors on Wed Jul 2 07:51:51 2025 config: NAME STATE READ WRITE CKSUM hdd ONLINE 0 0 0 raidz1-0 ONLINE 0 0 0 /dev/sdi1 ONLINE 0 0 0 /dev/sdf1 ONLINE 0 0 0 /dev/sdk1 ONLINE 0 0 0 /dev/sdh1 ONLINE 0 0 0 raidz1-1 ONLINE 0 0 0 /dev/sdj1 ONLINE 0 0 0 /dev/sdm1 ONLINE 0 0 0 /dev/sdl1 ONLINE 0 0 0 /dev/sdg1 ONLINE 0 0 0 errors: No known data errors pool: nvme state: ONLINE scan: scrub repaired 0B in 00:18:50 with 0 errors on Tue Jul 1 04:38:51 2025 config: NAME STATE READ WRITE CKSUM nvme ONLINE 0 0 0 /dev/nvme0n1p1 ONLINE 0 0 0 errors: No known data errors root@tower:~# fdisk -l /dev/sdh1 Disk /dev/sdh1: 12.73 TiB, 14000435757056 bytes, 3418075136 sectors Units: sectors of 1 * 4096 = 4096 bytes Sector size (logical/physical): 4096 bytes / 4096 bytes I/O size (minimum/optimal): 4096 bytes / 4096 bytes Thank you @JorgeB. I'm assuming this means I'm not using whole disk, which was my intention. I'd love to understand anything I should expect due to not using whole disk. Specific export/import flags, "/dev/disk/by-id", UI capabilities, etc. Thank you again!
-
root@tower:/# zpool status pool: hdd state: ONLINE scan: scrub repaired 0B in 1 days 03:31:50 with 0 errors on Wed Jul 2 07:51:51 2025 config: NAME STATE READ WRITE CKSUM hdd ONLINE 0 0 0 raidz1-0 ONLINE 0 0 0 ata-ST14000NM001G-2KJ103_ZTM0CELT ONLINE 0 0 0 ata-ST14000NM001G-2KJ103_ZL2A9ZPK ONLINE 0 0 0 ata-ST14000NM001G-2KJ103_ZL2AM87Y ONLINE 0 0 0 ata-ST14000NM001G-2KJ103_ZLW2MKW8 ONLINE 0 0 0 raidz1-1 ONLINE 0 0 0 ata-ST14000NM001G-2KJ103_ZL2AN75Z ONLINE 0 0 0 ata-ST14000NM001G-2KJ103_ZTM0CD44 ONLINE 0 0 0 ata-ST14000NM001G-2KJ103_ZL2CJ47G ONLINE 0 0 0 ata-ST14000NM001G-2KJ103_ZL2BWGB3 ONLINE 0 0 0 errors: No known data errors pool: nvme state: ONLINE scan: scrub repaired 0B in 00:18:50 with 0 errors on Tue Jul 1 04:38:51 2025 config: NAME STATE READ WRITE CKSUM nvme ONLINE 0 0 0 nvme0n1 ONLINE 0 0 0 (trimming) errors: No known data errors root@tower:/# zdb -l /dev/disk/by-id/ata-ST14000NM001G-2KJ103_ZLW2MKW8 failed to unpack label 0 failed to unpack label 1 failed to unpack label 2 failed to unpack label 3 root@tower:/# zdb -l /dev/disk/by-id/ata-ST14000NM001G-2KJ103_ZLW2MKW8-part1 ------------------------------------ LABEL 0 ------------------------------------ version: 5000 name: 'hdd' state: 0 txg: 14043265 pool_guid: 5764276688367145208 errata: 0 hostname: 'tower' top_guid: 7301316167661736821 guid: 16225184805902845557 vdev_children: 2 vdev_tree: type: 'raidz' id: 0 guid: 7301316167661736821 nparity: 1 metaslab_array: 266 metaslab_shift: 34 ashift: 12 asize: 56001724153856 is_log: 0 create_txg: 4 children[0]: type: 'disk' id: 0 guid: 9689511457415648178 path: '/dev/disk/by-id/ata-ST14000NM001G-2KJ103_ZTM0CELT-part1' devid: 'ata-ST14000NM001G-2KJ103_ZTM0CELT-part1' phys_path: 'pci-0000:2e:00.0-sas-phy2-lun-0' whole_disk: 1 DTL: 9378 create_txg: 4 children[1]: type: 'disk' id: 1 guid: 10443037663573755569 path: '/dev/disk/by-id/ata-ST14000NM001G-2KJ103_ZL2A9ZPK-part1' devid: 'ata-ST14000NM001G-2KJ103_ZL2A9ZPK-part1' phys_path: 'pci-0000:2e:00.0-sas-phy7-lun-0' whole_disk: 1 DTL: 9377 create_txg: 4 children[2]: type: 'disk' id: 2 guid: 12687003923774484790 path: '/dev/disk/by-id/ata-ST14000NM001G-2KJ103_ZL2AM87Y-part1' devid: 'ata-ST14000NM001G-2KJ103_ZL2AM87Y-part1' phys_path: 'pci-0000:2e:00.0-sas-phy4-lun-0' whole_disk: 1 DTL: 9376 create_txg: 4 children[3]: type: 'disk' id: 3 guid: 16225184805902845557 path: '/dev/disk/by-id/ata-ST14000NM001G-2KJ103_ZLW2MKW8-part1' devid: 'ata-ST14000NM001G-2KJ103_ZLW2MKW8-part1' phys_path: 'pci-0000:2e:00.0-sas-phy1-lun-0' whole_disk: 1 DTL: 9375 create_txg: 4 features_for_read: com.delphix:hole_birth com.delphix:embedded_data labels = 0 1 2 3 I've always had the same partition labels X, X-part1, X-part2 - and this is my second zpool setup (Mirrored initially, now z1 w/4 disks) Am I going to have an issue with importing these? I have 2 Unraid premium (or whatever) licenses, but very worried about trying to export/import in my running 7.2.4 system.
-
Was literally looking for this yesterday! I wish I knew more about creating Docker containers, but unRAID has babysat me for too long..
-
Jorge, where are the identified "bugs" of 6.12 documented and/or the proposed changelogs for 6.12.1? I'd love to see if others are having issues that I may wish to stay on 6.11.5 if they match my setup. Thank you!!
-
Same, really kicking myself in the ass for trying to move my perfectly working server to RC5 because I was so stoked about ZFS! haha, it was running perfectly until then...Rolled it back, and it's been nothing but highly unstable. Tried restoring from the backup i made before my upgrade & reboot to a new flash drive, and now I'm stuck with a GUID error. Good luck, will be watching this to see if anyone has any solutions. Since my dockers and VMs are completely broken, I'm even down to creating clean install and just importing my ZFS pools if that works. I have backups of my docker templates, so probably will be my next step if nothing comes of this thread.
-
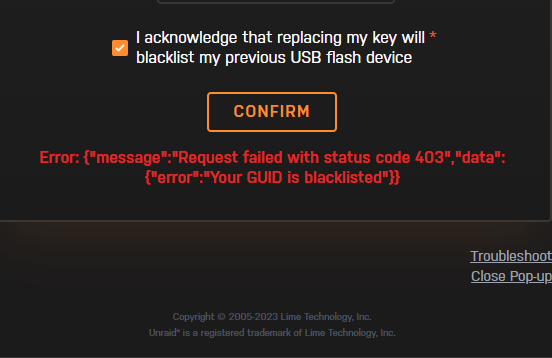
Followed this Changing the Flash Device post, works perfectly until "replace key". Popup comes on, and I clicked Acknowledge and then confirm. Doesn't make sense, since my old Sandisk drive in on my desk in front of me - and only my new one is plugged in. Is it too late to attempt to restore the backup to my older Sandisk drive, since this change is obviously not working? I just used my original flash drive and restored the same backup to it - no problem. I'll wait for Customer Support to reply back to my email - thanks.
-
Having this issue (smb all of a sudden not working) as well as constant hard locks, since upgrading to 12rc5, rolling back - even after restoring from backup before everything...will post my own thread once I power cycle and turn on syslog server
-
Prior to upgrade and reboot, I did export my pools. After upgrade and reboot and before array start, zpool status = no pools exist. Now that I'm where I'm at, what should I attempt, if I want to include it in my unRAID pools. Would love your thoughts on my questions, or any other people's. Thank you kindly for taking your time helping!
-
To clarify, I'm on RC5 now - but before starting array, I zpool import -a which brought in my hdd & nvme pools. The status are good and shares NFS/SMB work great. Then I created a pool in the UI called "hdd" which it let me, and I added the 8 drives with raidz & 2 groups of 4 devices. The pool shows up, but still has the "Unmountable:" error. However, everything seems to work fine, except that I had to increase permissions for some reason on my appdata/docker folder for a few containers - adminer & nextcloud.
-
tower-diagnostics-20230510-1309.zip Forgot to attach this on original, thank you and sorry for having to waste time requesting! Started looking, I can see mention of my nvme.cfg under shares, but want to remove it completely so I can eventually reuse it when figure this out. That would be a quick win for me, thank you!
-
I tried it initially following the paragraph from the RC1 & RC3 blog posts. That didn't work initially, because I seem to have some ghost user shares in a config file (not showing in UI Shares) with the same names as my zfs pools - nvme & hdd. I created new pools as above, and had to choose new names. After adding the new pools of 8 drives (2 raidz1 vdevs) & 1 nvme (raidz0), it changed my pool names. It couldn't find any data and it had the "Unmountable: Unsupported or no file system" error. I kinda freaked, and rolled back to 11. Still couldn't find my data, and then tried zpool import -a and it worked. To fix my existing shares/docker mappings, I zpool export <new pool names> zpool import <new pool names> <original pool names> Fine, back to "normal" except system was acting funny...ZFS pools wouldn't auto import at boot and weird docker behavior. Today I tried again, and just simply zpool import <original pool names>, and while it worked initially - I can't get them properly into a new pool. Still shows "Unmountable: Unsupported or no file system" even though everything else works fine. Questions: Any value to using my zfs pools as unRAID pools vs just keeping them "segregated"? If there is value, is there anything in my configuration that precludes importing them in as is in the current release? How should I set them up with "cache" settings when I don't really require that type of backend mgmt? System runs fabulously as is, with 2 flash drives as my "fake array", and 2 SSDs as my only pool to host my "appdata" - mainly docker folders, as i was having some crazy pain around how ZFS was creating infinite snapshots of their images.
-
I used the gui, and it wouldn't let me use the existing pool names. So I used new ones - but then it changed their pool names. Just I just imported them after downgrading, and then exported <old name> and imported <new name>. Do we have clear instructions on migrating? It seems like it would have been fine to stay on 12, and just do the same thing... It just wasn't what was documented.
-
I'm gonna need a proper writeup with pictures before I try that again. haha! It wouldn't let me reuse my pool names because it thinks I still have them as user shares. I deleted them forever ago and just use sharenfs locally, anyone have any idea where I can completely remove mentions of old user shares for next time I try this upgrade out? Thoughts on why it may have caused issues...I still had my drives "passed through" so I didn't accidentally mount them via Unassigned Disks. ****ZFS update scare - Rolled-back & zpool import -a + export/import to revert back pool names and set mountpoint back to /zfs/<pool>**** I really hope I didn't bork up my perfectly running 11.5 system... I followed these exact steps - "Pools created with the 'steini84' plugin can be imported as follows: First create a new pool with the number of slots corresponding to the number of devices in the pool to be imported. Next assign all the devices to the new pool. Upon array Start the pool should be recognized, though certain zpool topologies may not be recognized (please report)." Drives are showing empty, and neither original pools can be imported. It even renamed my 1st partition the new pool names (since I couldn't reuse my existing names - nvme & hdd because unraid thinks I have user shares named that still). I'm trying to roll back now, but OMG...haha! I didn't see any pop-up like above warning of formatting, so hoping it's just a "fun" scare. Should I have tried importing it via zpool import???
-
Hello, not sure what happened on my end - but I haven't been able to successfully download the updated driver. I've been stuck on 520.56.06 for a bit. I keep the window open so it keeps "Trying to redownload the Nvidia Driver v530.41.03", and I can keep it open for days - no dice. Any way to manually download that driver and update it via cli, vs this plugin? To be clear, all of my nvidia dockers & vms work great - love that I can do several streams and concurrently use on multiple containers/vms! Thank you. **Edit** tried to just delete it from /config/plugins/nvidia-driver/packages/5.19.17 and have it re-download again. It quickly downloaded the same file - but still showing stuck on the same "Downloading...This could take some time..." window
-
I found the options and syntax needed toake sharenfs work great! Tried replicating it via gui and/or go file, but they aer frustrating. Also added nfs to windows 11 pro, couldn't be happier.
-
same issue...can't figure out what's broken.
-
@HoopsterThank you for the quick reply. I haven't made a backup in sometime, but will try this this evening. Anyone else here with an AMD Ryzen 5 CPU - does your normal unRAID boot option show that option? Most things I'm seeing online says it should say amd_iommu=on iommu=pt or that it's unnecessary. Worst case, is it possible to download 6.10.3 and "start over"? I can save my docker templates, and my config files are on a separate zfs nvme pool. Probably just need to redo my cache ssd's which hold my docker subsystem (not using .img, but folders on the SSDs). Would that work as well? Thanks again to @Hoopster for advice! Used an old backup and looked up syslinux.cfg - didn't have the offending amd_iommu option. Deleted it from current cfg and voila! Not sure how it got there, but great lesson in using backups to validate changes and make them more often...
-
Captured the error which flashed very quickly: Loading /bzroot: ...ok Loading amd_iommu=pt...failed: No such file or directory Didn't change any other unRAID options or BIOs settings, besides downloading r4 update. Storms must have knocked out power long enough to cause UPS to kickoff shutdown. My BIOs has SV-IOV enabled, and I have diagnostics files 6 days ago after issue showed up and today. Things I tried: Rollback to 6.11.0.r3. Ran Memtest - 8 runs, no errors syslog in safemode keeps showing "Fatal error: Allowed memory size of 134217728 bytes exhausted (tried to allocate 4096 bytes) in /usr/local/emhttp/plugins/dynamix/include/Syslog.php on line 18" Renamed plugins & rebooted. Removed all plugins & rebooted. Manually edit out ohptions under regular boot option - PCIE passtrough & amd_iommu=pt, leaving only bzimage & bzroot Booted in safemode: reinstalled zfs plugin & others, zfs pools (all data) is fine and accessible after installation. SMART errors on 2 mirrored cache drives (reallocated sector counts 24) and several on my spinning rust (mirrored vdevs - still showing healthy)... UDMA CRC error count 2 Reallocated sector count 568 offline uncorrectable Thinking maybe reset CMOS or replace CMOS battery? Happy to post entire .zip or specific ones if this helps.
-
Thank you Marshalleq! I tired rolling back to 6.11.0.r3 and reboot, no bueno. I'll retry this again just in case, and come back to see how to get the updated plg installled. I did wget the link in first post, it downloaded it but not sure if that's the correct procedure.
-
Downloaded 6.11.0.r3 update before my trip (from 6.11.0.r2), but didn't reboot...in HI now, and a storm back home knocked out power long enough for server to intiate a shutdown. It updated, but won't boot unless in safe mode. Things I've tried - renames some/most plugins + reboot normally. Removed all settings for regular boot except normal (and immou and pcie stuff) + reboot. Seems it's a plugin, and the only one I haven't renamed is this one. Question, can I boot into safe mode and reinstall unRAID6-ZFS.plg to check my pools? I've done ample testing prior, feel confident data is good - just trying to troubleshoot while away to get at least zfs plugin up and running again. Good thing I setup wireguard on firewall and have access to IPMI...but damn good lesson I need some basic HA on critical apps like bitwarden...phone rebooted, and I can't access my phone's local DB. Luckily, my wife's iPhone either is different than android or hasn't rebooted - but what a PITA. Haha. I have diagnostics and am going through them, but they were run after I discovered the issue...
-
This is great stuff, thank you! I have 128GB of RAM and monitor/control it pretty aggressively (with docker parameters) due to doing so much in RAM (not to mention ZFS... :D) Haven't crashed yet, but very good to know. That parameter --mount type=tmpfs,destination=/tmp,tmpfs-size=8589934592 is exactly what I am looking for! Very easy to calculate & limit exactly what you want!! I'd be happy to create an outline and propose best answers w/links, for some kind of a pinned Best Practices or FAQ. For new users, that would help drastically vs. reading through 15 pages + additional topics like the one you posted! Not to mention lessen the amount of repeated answers you give! Thank you for creating, updating, and SUPPORTING this (and many other) dockers for unRAID!
-
I didn't create a RAMdisk, just /tmp. Makes sense re: /cache, I'll move that to my nvme where the docker config is. Re: /transcodes : /tmp, while it worked great for a day, it started throwing odd errors related to my frigate transcodes also being mounted to /tmp - specifically /tmp/frigate. [2022-04-13 15:21:26.763 -05:00] [ERR] [179] Jellyfin.Server.Middleware.ExceptionMiddleware: Error processing request. URL "POST" "/Sessions/Playing". System.UnauthorizedAccessException: Access to the path '/transcodes/frigate/cam-livingroom-20220413152052.mp4' is denied. ---> System.IO.IOException: Permission denied The only way this jellyfin docker doesn't look for other transcoding videos in /tmp is to put it in a separate directory, ie. /tmp/transcodes. Any ideas on how to keep it from looking in other directories under /tmp if it wants to transcode?


