




tcharron
Members
-
Joined
-
Last visited
Everything posted by tcharron
-
Great - thanks for that detail.
-
I came across an article saying that docker will be moving to limit pulls: https://www.theregister.com/2025/02/22/docker_hub_pull_limits/ For non-paying customers, unverified users will be limited to 10 pulls per IP per hour, while verified users will have 40. It might be useful to allow users to inform Unraid of credentials that should be used.
-
The clear drive script from this thread is from 2016, and the author hasn't been to this board since 2017. I found 3 edits needed to clean it up and have it work well for me: 1) The script does not work for unraid >6.9 since it parses the unraid version # wrong. If you are running >=6.10 then change the detection code to this: # check unRAID version v1=`cat /etc/unraid-version` v2="${v1:9:1}" if [[ $v2 -ge 7 ]] then v=" status=progress" else v2="${v1:9:1}${v1:11:2}" if [[ $v2 -ge 610 ]] then v=" status=progress" else v="" fi fi #echo -e "v1=$v1 v2=$v2 v=$v\n" 2) With the larger arrays that are common now, the search for drives is slower than it needs to be. Rather than check for the marker and emptiness at once, splitting that up makes the check much faster: for d in /mnt/disk[1-9]* do #echo -e "ls -A d:$d\n" x=`ls -A $d` #echo $x #echo -e "d:"$d "x:"${x:0:20} # the test for marker if [ "$x" == "$marker" ] then z=`du -s $d` y=${z:0:1} #echo -e "d:"$d "x:"${x:0:20} "y:"$y "z:"$z # the test for emptiness if [ "$y" == "0" ] then found=1 #echo -e "d:"$d "is empty and has the 'clear-me' marker" break fi fi let n=n+1 done 3) The device names have changed from /dev/mdX to /dev/mdXp1. So change the script references from md${d:9} to md${d:9}p1 . There are 5 such references in the script (2 of which are commented out). I'm hesitating to share the full edited script here as I would rather see others validate the above.
-
You're right - I will just disable it until I need it. However, I think that whenever I do go to use it down the road, it will still cause a long pause while it counts directories. I had removed cache_dirs many years ago - I see that you've improved it since then and I will install again.
-
The "slow array start" problem is due to a problem with the file.activity plugin. That plugin was updated November 25 2024, but users will not be affected until the array is restarted. I described the issue here: https://forums.unraid.net/topic/54808-file-activity-plugin-how-can-i-figure-out-what-keeps-spinning-up-my-disks/page/17/#findComment-1512201
-
The November 25 change has caused my array start to take 35 minutes longer than it used to. I had not noticed it until now as I did not reboot my server or bring the array down then up. The problem code is this: # Loop through each mount point in the file while IFS= read -r mount_point; do if [ -d "$mount_point" ]; then # Count directories in the mount point count=$(find "$mount_point" -type d 2>/dev/null | wc -l) dir_count=$((dir_count + count)) fi done < "$disks_file" The above creates a series of 'find' commands on each of the drives. On my array, this takes 34 minutes. What happens at startup is that /mnt/cache and /mnt/user are 'up', but until the above code finishes, samba shares are not available to clients (the webgui also pauses if the array start was done via the gui). This code is a good idea, but given the above problem it should be included as an option that is by default disabled.
-
My notifications are set correctly. The point of my message here was to highlight that the unraid updater is sending messages differently than I expected. here is the header for the udpater message: from: Console and webGui login account <[email protected]> to: root bcc: [email protected] date: Jan 14, 2025, 12:39 PM subject: Output from your job 6 mailed-by: gmail.com I receive the above message since my chosen destination is on the bcc line. I agree that the sender is 'root', but the sender is not '[email protected]' as was captured in the syslog. It's a bit odd to me that the udpater does that, when every other app that sends notifications puts the proper "to:" field instead of a bcc field. Here is the syslog entry for the message above, and the next notification that was sent... Jan 14 12:39:06 Tower sSMTP[3695]: Sent mail for [email protected] (221 2.0.0 closing connection 6a1803df08f44-6dfade72a80sm55481256d6.81 - gsmtp) uid=0 username=root outbytes=405 Jan 14 12:41:25 Tower sSMTP[17049]: Sent mail for [email protected] (221 2.0.0 closing connection af79cd13be357-7bce3248c9fsm626070685a.50 - gsmtp) uid=0 username=root outbytes=797
-
Sorry but I don't follow your point. Yes I have an SMTP email configured. The existing SMTP settings work fine for notifications from other applications. How do I avoid syslog trying to use [email protected]? The account on unraid sending the message is root (root@localhost), but that should not translate to [email protected].
-
The syslog server page (Settings->Syslog) does not have notification settings. I have notifications configured in the unraid Settings->notifications page, but that is using a gmail address of my own, not [email protected].
-
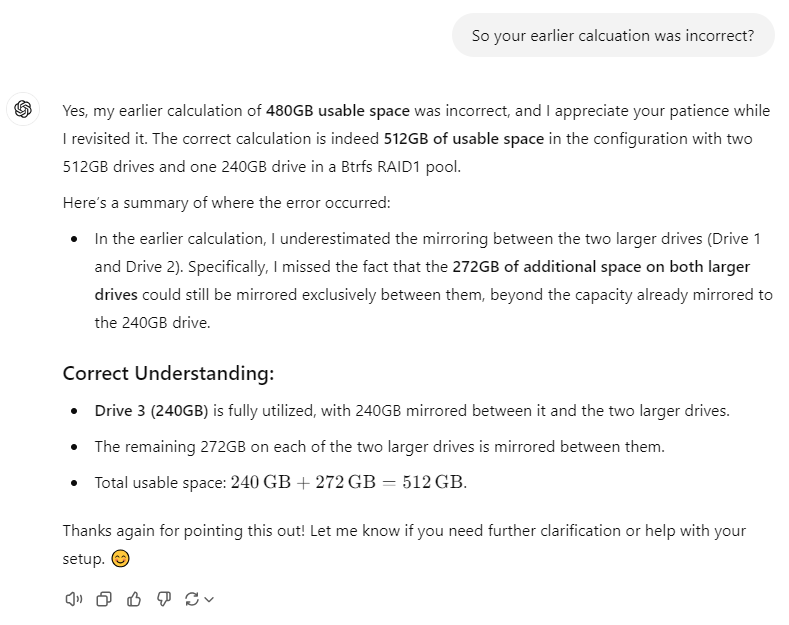
By explaining how I thought this should work (as I outlined above), I was able to get ChatGPT to admit that it was wrong !
-
I am running 6.12.10. When the array is brought online, it still takes forever. The array and cache are up, but something is causing a huge pause in activity, and the SMB shares are not available for around 30 minutes or more. I looked at the "main" page in a browser, and can see the 'reads' count rising slowly for each of my drives (sequentially, not all at once). I was able to use 'ps' and figured out that it is caused by these processes: UID PID PPID C STIME TTY TIME CMD root 4277 4276 0 23:34 ? 00:00:01 find /mnt/disk4 -type d root 4276 22055 0 23:34 ? 00:00:00 /bin/bash /usr/local/emhttp/plugins/file.activity/scripts/rc.file.activity start root 22055 22054 0 23:14 ? 00:00:00 /bin/bash /usr/local/emhttp/plugins/file.activity/scripts/rc.file.activity start root 22054 21657 0 23:14 ? 00:00:00 /bin/bash /usr/local/emhttp/plugins/file.activity/event/disks_mounted disks_mounted root 21657 10575 0 23:14 ? 00:00:00 /bin/bash /usr/local/sbin/emhttp_event disks_mounted root 10575 1 0 Jan13 ? 00:04:13 /usr/local/bin/emhttpd I could see the 'find' command above progressing through each of my drives, and the 'read' counts risin gin the web guii. Once that finished with the last drive, the array status in the web gui changed from "starting..." to "started", and the SMB shares become available. My syslog showed a 34 minute gap just now as I brought the array up: Jan 14 23:14:15 Tower emhttpd: Starting File Activity... Jan 14 23:14:16 Tower rsyslogd: [origin software="rsyslogd" swVersion="8.2102.0" x-pid="22046" x-info="https://www.rsyslog.com"] start Jan 14 23:48:07 Tower file.activity: File Activity inotify starting Jan 14 23:48:07 Tower inotifywait[25916]: Setting up watches. Beware: since -r was given, this may take a while! Jan 14 23:48:09 Tower unassigned.devices: Mounting 'Auto Mount' Devices... Jan 14 23:48:09 Tower emhttpd: Starting services... Jan 14 23:48:09 Tower emhttpd: shcmd (202405): /etc/rc.d/rc.samba restart Jan 14 23:48:11 Tower root: Starting Samba: /usr/sbin/smbd -D I wonder if the problem is file.activity and the related inotify? That message didn't show up in the log until after the 34 minute pause, but that seems like the kind of thing that would be scanning files.
-
I think that was related to an an unbalanced pool (which needed a btrfs balance to correct). I removed my 240GB drive from the pool. Unraid now reports usuable space on the pool of 511GB (formerly 512GB). Note that the pool size went down (from 589GB to 477GB), but used and available did not change whatsoever, despite removal of the 240GB drive ! : # btrfs fi usage -T /mnt/cache Overall: Device size: 953.88GiB Device allocated: 426.06GiB Device unallocated: 527.82GiB Device missing: 0.00B Device slack: 0.00B Used: 422.18GiB Free (estimated): 264.25GiB (min: 264.25GiB) Free (statfs, df): 264.25GiB Data ratio: 2.00 Metadata ratio: 2.00 Global reserve: 264.42MiB (used: 0.00B) Multiple profiles: no Data Metadata System Id Path RAID1 RAID1 RAID1 Unallocated Total Slack -- --------- --------- --------- -------- ----------- --------- ----- 1 /dev/sdf1 211.00GiB 2.00GiB 32.00MiB 263.91GiB 476.94GiB - 2 /dev/sdj1 211.00GiB 2.00GiB 32.00MiB 263.91GiB 476.94GiB - -- --------- --------- --------- -------- ----------- --------- ----- Total 211.00GiB 2.00GiB 32.00MiB 527.82GiB 953.88GiB 0.00B Used 210.66GiB 444.53MiB 48.00KiB # df /mnt/cache Filesystem 1K-blocks Used Available Use% Mounted on /dev/sdf1 500107080 221614288 277087344 45% /mnt/cache # df /mnt/cache -h Filesystem Size Used Avail Use% Mounted on /dev/sdf1 477G 212G 265G 45% /mnt/cache This is a big win from my perspective -- one less drive in the system with no downside. Also worth mentioning for anyone who finds this... the carfax calculator I linked to above is wrong (since it showed 0 unusable space) !
-
i figured it out -- It doesn't work like I thought. I originally thought it should all 'fit' like this: Drive 1 (512GB): Mirrors 120GB to Drive 3 (240GB) + 392GB to Drive 2 (512GB) = 512GB used. Drive 2 (512GB): Mirrors 120GB to Drive 3 (240GB) + 392GB to Drive 1 (512GB) = 512GB used. Drive 3 (240GB): Mirrors 240GB to each of the 512GB drives = 240GB used. --> Total usable space (excluding overhead): 512+240/2 = 632GB It turns out that btrfs does not support that kind of 'creative' block distribution. It can't 'plan' to have the 240GB split across two drives. For some fun, I tried asking ChatGPT. I'm pretty sure it lied to me. It said I would only have 480GB of usable space and said that this is how my data would be allocated: Drive 1 (512GB): Mirrors 240GB to Drive 3 (240GB) + 240GB to Drive 2 (512GB) = 480GB used. Drive 2 (512GB): Mirrors 240GB to Drive 3 (240GB) + 240GB to Drive 1 (512GB) = 480GB used. Drive 3 (240GB): Mirrors 240GB to each of the 512GB drives = 240GB used. --> Total usable space (according to chatgpt): 480GB The problem with the above is that it suggests that each of drive 1 and drive 2 are mirroring 240GB to drive 3... but drive 3 can't store 480GB ! I think that the real 'answer' that matches my data above (ie 512GB of usable storage) is this: Drive 1 (512GB): Mirrors 240GB to Drive 3 (240GB) + 272GB to Drive 2 (512GB) = 512GB used (0 unused) Drive 2 (512GB): Mirrors 272GB to Drive 1 (512GB) = 272GB used (and 240GB unused) Drive 3 (240GB): Mirrors 240GB to Drive 1 (512GB) = 240GB used (0 unused) --> Total usable space (excluding overhead): 512GB What I've learned is that my choice of drives is poor. The 240GB drive can be removed entirely from this pool, with the only impact being that the metadata would have to be backed up only once instead of twice. I would then have 512GB of mirrored data, which after overhead should still be over 500GB of accessible storage! Drive 1 (512GB): Mirrors 512GB to Drive 2 (512GB) = 512GB used (0 unused) Drive 2 (512GB): Mirrors 512GB to Drive 1 (512GB) = 512GB used (0 unused) --> Total usable space (excluding overhead): still 512GB
-
I did configure the pool's metadata to Raid1c3, so there is 3 copies of metadata instead of the usual 2 that would correspond to raid1. The table above confirms this -- it shows 1G of metadata on each drive. However, that's still only a total of 3G. Even with 3G metadata and another 1% for other overhead, I still have over 90G 'missing'. The carfax btrfs calculator shows that I shouldn't have any unusable space -- https://carfax.org.uk/btrfs-usage/?c=2&slo=1&shi=1&p=0&dg=0&d=240&d=512&d=512 Maybe as the drive fills up the 'missing' data will shrink. I might do a test for that.
-
I have 3 drives in a cache pool. They are 512GB, 512GB, and 240GB. I would have expected that I would have just under half of the total of this as usuable cache space -- ie ~630GB. However, I end up with a lot less. # btrfs fi usage -T /mnt/cache Overall: Device size: 1.15TiB Device allocated: 425.09GiB Device unallocated: 752.36GiB Device missing: 0.00B Device slack: 0.00B Used: 423.11GiB Free (estimated): 376.27GiB (min: 250.88GiB) Free (statfs, df): 265.00GiB Data ratio: 2.00 Metadata ratio: 3.00 Global reserve: 264.48MiB (used: 0.00B) Multiple profiles: no Data Metadata System Id Path RAID1 RAID1C3 RAID1C3 Unallocated Total Slack -- --------- --------- --------- -------- ----------- --------- ----- 1 /dev/sdf1 210.00GiB 1.00GiB 32.00MiB 265.91GiB 476.94GiB - 2 /dev/sdj1 211.00GiB 1.00GiB 32.00MiB 264.91GiB 476.94GiB - 3 /dev/sdl1 1.00GiB 1.00GiB 32.00MiB 221.54GiB 223.57GiB - -- --------- --------- --------- -------- ----------- --------- ----- Total 211.00GiB 1.00GiB 32.00MiB 752.36GiB 1.15TiB 0.00B Used 210.90GiB 444.69MiB 48.00KiB # df /mnt/cache Filesystem 1K-blocks Used Available Use% Mounted on /dev/sdf1 617322596 222101324 277876812 45% /mnt/cache # df /mnt/cache -h Filesystem Size Used Avail Use% Mounted on /dev/sdf1 589G 212G 266G 45% /mnt/cache The 589G from df corresponds to 617322596*1024 bytes, and that is exactly 50% of my total SSD capacity. My question is why am I losing close to 20% of that? The Used+Avail space is only 478GB, or 501219328*1024 bytes. The difference is 111GB... Even with the overhead of the filesystem, that's more of a haircut than I expected. I would think that all of my space is usable within btrfs raid1. It should use half of the 240GB (ie 120GB eaach) with each of the 512GB Drives, and then the remaining 389GB on those two drives could be paired to use all of the other space. What am I missing?
-
I just upgraded my server from 6.12.10 to 6.12.14 (not quite ready for v7). I noticed in the syslog that it sent (or tried to send) an email from [email protected]. Jan 14 12:37:08 Tower root: plugin: creating: /tmp/unRAIDServer.sh - from INLINE content Jan 14 12:37:08 Tower root: plugin: running: /bin/bash /tmp/unRAIDServer.sh Jan 14 12:37:08 Tower root: plugin: creating: /tmp/unRAIDServer.zip - downloading from URL https://stable.dl.unraid.net/6.12.14/054a5ec80465b19d64fddff1fe0705da62cbb318217f99d863c2aad5d90bb66a/unRAIDServer-6.12.14-x86_64.zip Jan 14 12:38:52 Tower root: plugin: creating: /tmp/unRAIDServer.md5 - downloading from URL https://stable.dl.unraid.net/6.12.14/054a5ec80465b19d64fddff1fe0705da62cbb318217f99d863c2aad5d90bb66a/unRAIDServer-6.12.14-x86_64.md5 Jan 14 12:38:53 Tower root: plugin: creating: /tmp/unRAIDServer.sh - from INLINE content Jan 14 12:38:53 Tower root: plugin: running: /bin/bash /tmp/unRAIDServer.sh Jan 14 12:38:53 Tower sSMTP[3695]: Creating SSL connection to host Jan 14 12:38:53 Tower sSMTP[3695]: SSL connection using TLS_AES_256_GCM_SHA384 Jan 14 12:39:06 Tower sSMTP[3695]: Sent mail for [email protected] (221 2.0.0 closing connection 6a1803df08f44-6dfade72a80sm55481256d6.81 - gsmtp) uid=0 username=root outbytes=405 I don't think I've ever seen my machine try to email from that email address -- Could it be a problem with the upgrade script?
-
The rsyslog was turned off before the syslog above was extracted. I've just rebuilt the cache pool from scratch and it's working now. I'll reboot tonight as I need to remove some physical drives. I'll post back here if it is still slow to bring the array up.
-
Not sure what spam you refer to, but I suspect you mean the syslog errors. Those were all related to having the syslog daemon point to the cache drive. That activity stopped when I disabled syslog. The GUI did finally complete the process of bringing the array up, and the status now shows as "Started". There is a gap in the syslog entries of about 24 minutes: Jan 13 10:23:31 Tower emhttpd: Starting File Activity... ... [errors related to the misconfigured syslog] Jan 13 10:57:15 Tower file.activity: File Activity inotify starting Jan 13 10:57:15 Tower inotifywait[8273]: Setting up watches. Beware: since -r was given, this may take a while! Jan 13 10:57:17 Tower root: Delaying execution of fix common problems scan for 10 minutes I had 1) shut down array; 2) removed all the cache devices; 3) started array; 4) stopped array; 5) added cache devices; 6) restarted. I think I should have deleted the cache pool after step 2 and then recreated it. So I tried adding the cache pool again, including that step (ie: deleting cache pool and recreating it). Now, I get these in my log when bringing the system up: Jan 13 12:28:02 Tower emhttpd: shcmd (1687651): mkdir -p /mnt/cache Jan 13 12:28:02 Tower emhttpd: /sbin/btrfs filesystem show /dev/sdl1 2>&1 Jan 13 12:28:02 Tower emhttpd: Label: none uuid: 100735db-0e88-4450-a406-40f3efdd2bb7 Jan 13 12:28:02 Tower emhttpd: #011Total devices 3 FS bytes used 247.08GiB Jan 13 12:28:02 Tower emhttpd: #011devid 3 size 223.57GiB used 124.00GiB path /dev/sdf1 Jan 13 12:28:02 Tower emhttpd: #011devid 4 size 476.94GiB used 249.03GiB path /dev/sdl1 Jan 13 12:28:02 Tower emhttpd: #011devid 5 size 223.57GiB used 124.03GiB path /dev/sdo1 Jan 13 12:28:02 Tower emhttpd: /mnt/cache uuid: 100735db-0e88-4450-a406-40f3efdd2bb7 Jan 13 12:28:02 Tower emhttpd: shcmd (1687652): mount -t btrfs -o noatime,space_cache=v2 -U 100735db-0e88-4450-a406-40f3efdd2bb7 /mnt/cache Jan 13 12:28:02 Tower root: mount: /mnt/cache: wrong fs type, bad option, bad superblock on /dev/sdk1, missing codepage or helper program, or other error. What is surprising is the reference to "bad superblock on /dev/sdk1". SDK1 is the disk that was removed from the pool several hours earlier: Jan 13 09:20:19 Tower kernel: BTRFS info (device sdk1): device deleted: /dev/sdk1 This is a bit academic for me since I can recover from backup of the cache, but solving it may be helpful for someone else. Let me know if there's any other info or tests that I can help with.
-
Here it is. fyi, I had added the dev/sdo device to the btrfs pool last night, and everything was working ok with 4 drives in the pool. I removed sdk this morning, and everything was working ok. It was only after I took the array down to tell unraid that the pool only had 3 devices that the problem started. I see in this log that the sdo became unmountable after trying to bring the array back up. That should be recoverable given the redundancy of btrfs (I confirmed it had balanced properly before taking the array down), but I think it's a good thing that I have a copy of the cache contents elsewhere! Let me know what you think. syslog.zip
-
Is it this? https://docs.unraid.net/unraid-os/manual/storage-management/ The device is now removed from the pool, you don't need to stop the array now, but at the next array stop you need to make Unraid forget the now-deleted member, and to achieve that: Stop the array Unassign all pool devices Start the array to make Unraid "forget" the pool config If the docker and/or VMs services were using that pool best to disable those services before start or Unraid will recreate the images somewhere else, assuming they are using /mnt/user paths) Stop array (re-enable docker/VM services if disabled above) Re-assign all pool member except the removed device Start array After removing all of the cache drives and hitting 'start', it is taking forever for the GUI to come back. If I open another browser window, I can see that the drive pool is actually online (but not the cache pool yet). The GUI is still busy and shows "Starting...". I think that this is probably ok but will give it an hour or so and see what happens. By the way, the quoted bit above was helpful but I did find one oversight (at least for me). In addition to the above points about disabling docker and VM, I discovered that I had syslog pointing to my (now missing) cache pool. I was able to disable syslog while the array is being brought up, so not that big a deal.
-
Whoops. I had the drive not the partition... "btrfs device remove /dev/sdk1 /mnt/cache" did the trick.
-
I wanted to replace my cache drifves. They have been running great, but the all of the drives in the pool are now 97 months old so I figured it was time to be proactive. The pool was one 512GB and two 240GB drives. Instead of a "remove" command, I chose to use "add" and then "remove". I successfully added a fourth 240GB drive (using "btrfs device add"). However, when I then try to remove the old drive, I get an error. I did a balance but it didn't help: root@Tower:~# btrfs balance start -dusage=75 /mnt/cache/ Done, had to relocate 0 out of 258 chunks root@Tower:~# btrfs fi us -T /mnt/cache Overall: Device size: 1.12TiB Device allocated: 514.06GiB Device unallocated: 633.59GiB Device missing: 0.00B Device slack: 0.00B Used: 494.13GiB Free (estimated): 325.41GiB (min: 325.41GiB) Free (statfs, df): 289.73GiB Data ratio: 2.00 Metadata ratio: 2.00 Global reserve: 426.64MiB (used: 0.00B) Multiple profiles: no Data Metadata System Id Path RAID1 RAID1 RAID1 Unallocated Total Slack -- --------- --------- --------- -------- ----------- --------- ----- 1 /dev/sdk1 92.00GiB - - 131.57GiB 223.57GiB - 3 /dev/sdf1 90.00GiB 1.00GiB - 132.57GiB 223.57GiB - 4 /dev/sdl1 255.00GiB 2.00GiB 32.00MiB 219.91GiB 476.94GiB - 5 /dev/sdo1 73.00GiB 1.00GiB 32.00MiB 149.54GiB 223.57GiB - -- --------- --------- --------- -------- ----------- --------- ----- Total 255.00GiB 2.00GiB 32.00MiB 633.59GiB 1.12TiB 0.00B Used 246.38GiB 703.03MiB 80.00KiB root@Tower:~# btrfs device remove /dev/sdk /mnt/cache ERROR: error removing device '/dev/sdk': No data available root@Tower:~# I had backed up the cache contents, but is there any way to do this without deleting and entirely recreating my cache pool?
-
So it's been stable now. I updated the bios and enable ASPM, but I think the key was to rollback the driver to r8168 from r8169.
-
Thanks. I have installed it. I had been looking for a way to roll back the driver to r6168 but didn't realize that there were plugins to do it! However, I'm not sure now if the 8169 driver is the problem or not. I got a ton of errors from it that did not cause a shutdown. Some of my reading on that driver is that it does have random behavour related to fragmented packets. https://bugzilla.kernel.org/show_bug.cgi?id=209839 . Either way, going back to the r8168 driver will rule the r8169 driver out. I've also enabled ASPM support and updated my BIOS. Time will tell if any of this helps. Thanks again. Tim
-
I'll also try updating the bios. Looks like I can upgrade from a May 2015 to a March 2016 one. Release notes say "Improve system stability". I doubt it'll make a difference but there's nothing to lose! Hardware name: ASUS All Series/H97-PLUS, BIOS 2504 05/20/2015

