




Dephcon
Members
-
Joined
-
Last visited
-
For those of us with a us basic/plus license, how long do we have to upgrade to pro if it's been something we're been putting off?
-
works now, *shrugs*
-
Doesn't seem to be available yet via "Update OS"
-
Going by this thread here, I believe this issue to originate with 6.10 when ipvlan was introduced. I've just recently needed to switch from macvlan to ipvlan as my sever started kernel panicking after adding some new hardware (nvme+ram). if 'Host access to custom networks' is Enabled while using ipvlan the server functions normally in terms of routing, reaching the internet, etc, and the routing table is all good: root@vault13:~# route Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface default 10.81.0.6 0.0.0.0 UG 0 0 0 br0 10.81.0.0 0.0.0.0 255.255.255.0 U 0 0 0 br0 172.18.0.0 0.0.0.0 255.255.0.0 U 0 0 0 br-f237a61f1b1e After starting the docker service, the shim interfaces get added to the routing table and everything seems fine: root@vault13:~# route Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface default 10.81.0.6 0.0.0.0 UG 0 0 0 br0 10.81.0.0 0.0.0.0 255.255.255.128 U 0 0 0 shim-br0 10.81.0.0 0.0.0.0 255.255.255.0 U 0 0 0 br0 10.81.0.128 0.0.0.0 255.255.255.128 U 0 0 0 shim-br0 172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0 172.18.0.0 0.0.0.0 255.255.0.0 U 0 0 0 br-f237a61f1b1e then after a minute or two of the docker service running all internet routing from the server comes to a halt, except for any containers on a br interface with their own IPs. Another capture of the routing table at this point doesn't show any changes from above. The only work around it setting 'Host access to custom networks' to disabled, but that's a not ideal.this seems to be an ongoing issue for folks. I'll close this ticket off as my orginal issue has been solved, thanks again @JorgeB+1 I recently added a NVMe drive and different RAM to my server and all of a sudden I was getting macvlan traces, so by advise of a community member I switched to ipvlan. I'm having the same issue, with ipvlan and "Host access to custom networks: Enabled" my unraid sever and any "bridge" containers can no longer route externally. It Disabling "Host access to custom networks" seems to have "fixed" the issue, but I'm not sure what I'm losing here. I recall turning it on for a good reaasonI've removed the nic bonding and the tagged vlan network and I'm still seeing the same behavior. it's really frustrating because the containers on the br0 interface with their own IPs work just fine, it's the containers in bridge mode that fail along with the unraidOS itself.seems the problem persists with the docker service running but with all the containers stopped. It's possible ipvlan doesn't jive well with vlan tagging networks, or LACP bonding. Do you have any idea why macvlan was causing my system to kernel panic?@JorgeB since switching to ipvlan, my unraid server seems to have problems with DNS/routing now. It's a bit hard to rationalize... On boot/array stop: everything is fine, i can resolve websites using cloudfare DNS (1.1.1.1/1.0.0.1) and ping them On array docker start: same behavior After about 3-4 minutes I can no longer ping/route to external addresses like cloudflare DNS and thus can't resolve anything If i disable the docker service, everything works again This was not an issue while running macvlan vault13-diagnostics-20221026-1109.zipswitched it over to ipvlan, I guess I'll know if a couple weeks if it was effective. Thank you!I added an NVME drive and replaced 4x4GB DIMMs with 2x16GB a few months ago. Seemed fine for a while but the last month or two it's kernel paniced almost weekly. Unfortunately i didn't have remote syslog enabled so this is the first time i've gotten anything useful. I'll include the diag from after reboot, but it doesn't contain anything pre-panic. I did verify the RAM with memtest for 24 hours. Oct 23 20:51:24 vault13 kernel: ------------[ cut here ]------------ Oct 23 20:51:24 vault13 kernel: WARNING: CPU: 5 PID: 0 at net/netfilter/nf_nat_core.c:594 nf_nat_setup_info+0x73/0x7b1 [nf_nat] Oct 23 20:51:24 vault13 kernel: Modules linked in: tcp_diag udp_diag inet_diag macvlan veth xt_nat xt_tcpudp xt_conntrack xt_MASQUERADE nf_conntrack_netlink nfnetlink xfrm_user xfrm_algo xt_addrtype iptable_nat nf_nat nf_conntrack nf_defrag_ipv6 nf_defrag_ipv4 br_netfilter xfs md_mod k10temp hwmon_vid fam15h_power efivarfs wireguard curve25519_x86_64 libcurve25519_generic libchacha20poly1305 chacha_x86_64 poly1305_x86_64 ip6_udp_tunnel udp_tunnel libchacha ip6table_filter ip6_tables iptable_filter ip_tables x_tables bridge 8021q garp mrp stp llc bonding tls ipv6 e1000e i915 x86_pkg_temp_thermal intel_powerclamp iosf_mbi drm_buddy coretemp i2c_algo_bit ttm kvm_intel drm_display_helper kvm drm_kms_helper crct10dif_pclmul crc32_pclmul crc32c_intel ghash_clmulni_intel aesni_intel mxm_wmi intel_wmi_thunderbolt crypto_simd cryptd rapl drm intel_cstate nvme input_leds intel_uncore mpt3sas intel_gtt led_class i2c_i801 i2c_smbus agpgart nvme_core i2c_core ahci raid_class syscopyarea libahci scsi_transport_sas Oct 23 20:51:24 vault13 kernel: sysfillrect sysimgblt fb_sys_fops intel_pch_thermal fan video thermal wmi backlight acpi_pad button unix [last unloaded: e1000e] Oct 23 20:51:24 vault13 kernel: CPU: 5 PID: 0 Comm: swapper/5 Tainted: G W 5.19.14-Unraid #1 Oct 23 20:51:24 vault13 kernel: Hardware name: MSI MS-7998/Z170A SLI PLUS (MS-7998), BIOS 1.E0 06/15/2018 Oct 23 20:51:24 vault13 kernel: RIP: 0010:nf_nat_setup_info+0x73/0x7b1 [nf_nat] Oct 23 20:51:24 vault13 kernel: Code: 48 8b 87 80 00 00 00 48 89 fb 49 89 f4 76 04 0f 0b eb 0e 83 7c 24 1c 00 75 07 25 80 00 00 00 eb 05 25 00 01 00 00 85 c0 74 07 <0f> 0b e9 6a 06 00 00 48 8b 83 88 00 00 00 48 8d 73 58 48 8d 7c 24 Oct 23 20:51:24 vault13 kernel: RSP: 0018:ffffc900001fc7b8 EFLAGS: 00010202 Oct 23 20:51:24 vault13 kernel: RAX: 0000000000000080 RBX: ffff88826d04cf00 RCX: ffff8881063ce3c0 Oct 23 20:51:24 vault13 kernel: RDX: 0000000000000000 RSI: ffffc900001fc89c RDI: ffff88826d04cf00 Oct 23 20:51:24 vault13 kernel: RBP: ffffc900001fc880 R08: 00000000cf00510a R09: 0000000000000000 Oct 23 20:51:24 vault13 kernel: R10: 0000000000000158 R11: 0000000000000000 R12: ffffc900001fc89c Oct 23 20:51:24 vault13 kernel: R13: 00000000cf005100 R14: ffffc900001fc978 R15: 0000000000000000 Oct 23 20:51:24 vault13 kernel: FS: 0000000000000000(0000) GS:ffff88884ed40000(0000) knlGS:0000000000000000 Oct 23 20:51:24 vault13 kernel: CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 Oct 23 20:51:24 vault13 kernel: CR2: 000000c000353010 CR3: 000000000400a002 CR4: 00000000003706e0 Oct 23 20:51:24 vault13 kernel: DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000 Oct 23 20:51:24 vault13 kernel: DR3: 0000000000000000 DR6: 00000000fffe0ff0 DR7: 0000000000000400 Oct 23 20:51:24 vault13 kernel: Call Trace: Oct 23 20:51:24 vault13 kernel: <IRQ> Oct 23 20:51:24 vault13 kernel: ? xt_write_recseq_end+0xf/0x1c [ip_tables] Oct 23 20:51:24 vault13 kernel: ? __local_bh_enable_ip+0x56/0x6b Oct 23 20:51:24 vault13 kernel: ? ipt_do_table+0x57a/0x5bf [ip_tables] Oct 23 20:51:24 vault13 kernel: ? xt_write_recseq_end+0xf/0x1c [ip_tables] Oct 23 20:51:24 vault13 kernel: ? __local_bh_enable_ip+0x56/0x6b Oct 23 20:51:24 vault13 kernel: __nf_nat_alloc_null_binding+0x66/0x81 [nf_nat] Oct 23 20:51:24 vault13 kernel: nf_nat_inet_fn+0xc0/0x1a8 [nf_nat] Oct 23 20:51:24 vault13 kernel: nf_nat_ipv4_local_in+0x2a/0xaa [nf_nat] Oct 23 20:51:24 vault13 kernel: nf_hook_slow+0x3a/0x96 Oct 23 20:51:24 vault13 kernel: ? ip_protocol_deliver_rcu+0x164/0x164 Oct 23 20:51:24 vault13 kernel: NF_HOOK.constprop.0+0x79/0xd9 Oct 23 20:51:24 vault13 kernel: ? ip_protocol_deliver_rcu+0x164/0x164 Oct 23 20:51:24 vault13 kernel: ip_sabotage_in+0x47/0x58 [br_netfilter] Oct 23 20:51:24 vault13 kernel: nf_hook_slow+0x3a/0x96 Oct 23 20:51:24 vault13 kernel: ? ip_rcv_finish_core.constprop.0+0x3b7/0x3b7 Oct 23 20:51:24 vault13 kernel: NF_HOOK.constprop.0+0x79/0xd9 Oct 23 20:51:24 vault13 kernel: ? ip_rcv_finish_core.constprop.0+0x3b7/0x3b7 Oct 23 20:51:24 vault13 kernel: __netif_receive_skb_one_core+0x68/0x8d Oct 23 20:51:24 vault13 kernel: netif_receive_skb+0xbf/0x127 Oct 23 20:51:24 vault13 kernel: br_handle_frame_finish+0x476/0x4b0 [bridge] Oct 23 20:51:24 vault13 kernel: ? br_pass_frame_up+0xdd/0xdd [bridge] Oct 23 20:51:24 vault13 kernel: br_nf_hook_thresh+0xe2/0x109 [br_netfilter] Oct 23 20:51:24 vault13 kernel: ? br_pass_frame_up+0xdd/0xdd [bridge] Oct 23 20:51:24 vault13 kernel: br_nf_pre_routing_finish+0x2c1/0x2ec [br_netfilter] Oct 23 20:51:24 vault13 kernel: ? br_pass_frame_up+0xdd/0xdd [bridge] Oct 23 20:51:24 vault13 kernel: ? NF_HOOK.isra.0+0xe4/0x140 [br_netfilter] Oct 23 20:51:24 vault13 kernel: ? br_nf_hook_thresh+0x109/0x109 [br_netfilter] Oct 23 20:51:24 vault13 kernel: br_nf_pre_routing+0x226/0x23a [br_netfilter] Oct 23 20:51:24 vault13 kernel: ? br_nf_hook_thresh+0x109/0x109 [br_netfilter] Oct 23 20:51:24 vault13 kernel: br_handle_frame+0x27c/0x2e7 [bridge] Oct 23 20:51:24 vault13 kernel: ? br_pass_frame_up+0xdd/0xdd [bridge] Oct 23 20:51:24 vault13 kernel: __netif_receive_skb_core.constprop.0+0x4f6/0x6e3 Oct 23 20:51:24 vault13 kernel: ? slab_post_alloc_hook+0x4d/0x15e Oct 23 20:51:24 vault13 kernel: ? __alloc_skb+0xb2/0x15e Oct 23 20:51:24 vault13 kernel: ? __kmalloc_node_track_caller+0x1ae/0x1d9 Oct 23 20:51:24 vault13 kernel: ? udp_gro_udphdr+0x1c/0x40 Oct 23 20:51:24 vault13 kernel: __netif_receive_skb_list_core+0x8a/0x11e Oct 23 20:51:24 vault13 kernel: netif_receive_skb_list_internal+0x1d7/0x210 Oct 23 20:51:24 vault13 kernel: gro_normal_list+0x1d/0x3f Oct 23 20:51:24 vault13 kernel: napi_complete_done+0x7b/0x11a Oct 23 20:51:24 vault13 kernel: e1000e_poll+0x9e/0x23e [e1000e] Oct 23 20:51:24 vault13 kernel: __napi_poll.constprop.0+0x28/0x124 Oct 23 20:51:24 vault13 kernel: net_rx_action+0x159/0x24f Oct 23 20:51:24 vault13 kernel: ? e1000_intr_msi+0x114/0x120 [e1000e] Oct 23 20:51:24 vault13 kernel: __do_softirq+0x126/0x288 Oct 23 20:51:24 vault13 kernel: __irq_exit_rcu+0x79/0xb8 Oct 23 20:51:24 vault13 kernel: common_interrupt+0x9b/0xc1 Oct 23 20:51:24 vault13 kernel: </IRQ> Oct 23 20:51:24 vault13 kernel: <TASK> Oct 23 20:51:24 vault13 kernel: asm_common_interrupt+0x22/0x40 Oct 23 20:51:24 vault13 kernel: RIP: 0010:cpuidle_enter_state+0x11b/0x1e4 Oct 23 20:51:24 vault13 kernel: Code: e4 0f a2 ff 45 84 ff 74 1b 9c 58 0f 1f 40 00 0f ba e0 09 73 08 0f 0b fa 0f 1f 44 00 00 31 ff e8 0e bf a6 ff fb 0f 1f 44 00 00 <45> 85 ed 0f 88 9e 00 00 00 48 8b 04 24 49 63 cd 48 6b d1 68 49 29 Oct 23 20:51:24 vault13 kernel: RSP: 0018:ffffc90000107e98 EFLAGS: 00000246 Oct 23 20:51:24 vault13 kernel: RAX: ffff88884ed40000 RBX: 0000000000000004 RCX: 0000000000000000 Oct 23 20:51:24 vault13 kernel: RDX: 0000000000000005 RSI: ffffffff81ec95aa RDI: ffffffff81ec9a8a Oct 23 20:51:24 vault13 kernel: RBP: ffff88884ed75300 R08: 0000000000000002 R09: 0000000000000002 Oct 23 20:51:24 vault13 kernel: R10: 0000000000000020 R11: 0000000000000221 R12: ffffffff821156c0 Oct 23 20:51:24 vault13 kernel: R13: 0000000000000004 R14: 0000af79da1529b8 R15: 0000000000000000 Oct 23 20:51:24 vault13 kernel: ? cpuidle_enter_state+0xf5/0x1e4 Oct 23 20:51:24 vault13 kernel: cpuidle_enter+0x2a/0x38 Oct 23 20:51:24 vault13 kernel: do_idle+0x187/0x1f5 Oct 23 20:51:24 vault13 kernel: cpu_startup_entry+0x1d/0x1f Oct 23 20:51:24 vault13 kernel: start_secondary+0xeb/0xeb Oct 23 20:51:24 vault13 kernel: secondary_startup_64_no_verify+0xce/0xdb Oct 23 20:51:24 vault13 kernel: </TASK> Oct 23 20:51:24 vault13 kernel: ---[ end trace 0000000000000000 ]--- vault13-diagnostics-20221024-0933.zipis that capture taken when you first start watching the movie and it's building a buffer, or after? it's not as staggeringly less burdened than my 7700K as I would have thought: Still considering upgrading to a 12500/600 as audio transcoding can be a real CPU hog.
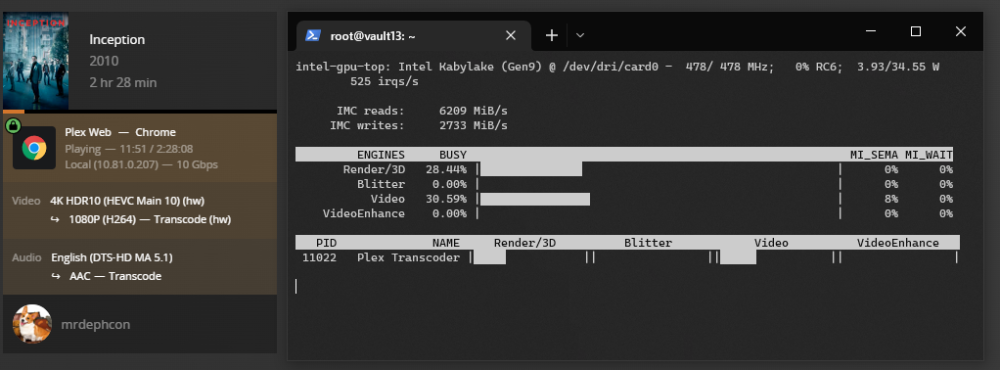 Sorry, can you elaborate on that a bit? Was about to pull the trigger on 11th gen, but would prefer 12th. so with 12th gen: it's stable with unraid in general it does plex docker hardware h264 encode/decode and h265 decode it does plex docker HDR tone mapping while hardware encode/decode is enabled (and actually working) thanks!is the tone mapping an issue with the driver included in unraid or software issue with plex? i just started getting 4k/HDR content to find out my 7th gen doesn't support tone mapping at all and need a replacement =\
Sorry, can you elaborate on that a bit? Was about to pull the trigger on 11th gen, but would prefer 12th. so with 12th gen: it's stable with unraid in general it does plex docker hardware h264 encode/decode and h265 decode it does plex docker HDR tone mapping while hardware encode/decode is enabled (and actually working) thanks!is the tone mapping an issue with the driver included in unraid or software issue with plex? i just started getting 4k/HDR content to find out my 7th gen doesn't support tone mapping at all and need a replacement =\



