





Kosmos
Members
-
Joined
-
Last visited
Everything posted by Kosmos
-
Hey everyone, how can I set the directory of my persistent container data to be in the appdata folder on the array? right now, the compose file is created on the boot usb device and all my paths in the compose file are relative to it. However, I'd like to store the data in the same location as the "normal" docker implementation. I found working_dir and context but received errors on trying it. Btw. can I circumvent the error "Configuration not found. Was this container created using this plugin?" when updating the container from the gui? Best regards
-
Probably, yes, I will ask SanDisk about this. Thanks again for your continued help! See you on the next one 😛 p.s: you may flag this topic solved, I can not do it, because I missed creating a new one and took over from johnsanc (😇)
-
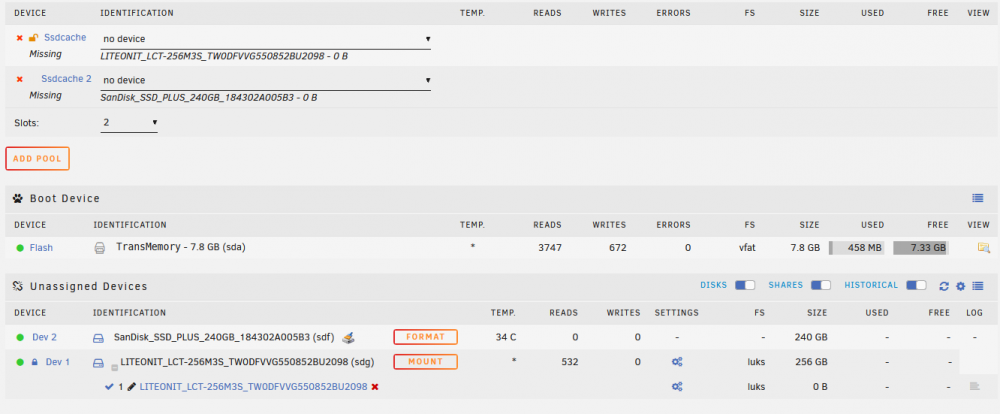
In my opinion, it could be both. It appears, the partition information is lost at some point, so Unraid does not detect there is a cache partition on the ssd. As a consequence, nothing can be decrypted. However, the problem appears without encryption as well. I tried to change the sata controller and cable as well, but it didn't help either. Anyway, I wonder why this particular disk is recognized correctly sometimes, but sometimes not after reboots. So either unraid is not reading the disk correctly, or the ssd is resetting/deleting it's partition (headers) sometimes for unknown reasons... I attached a screenshot of the unassigned drives after the problem occured (encryption lock symbol and partition gone) and a SMART report of this ssd as well. server-smart-20210915-1213.zip
-
Too bad, I guess the problem might be that the docker vdisk can only be read very slowly when it's stored on a busy HDD. I solved the problem by moving it to a SSD cache instead.
-
It should be decrypted only after entering the password and starting the array, right? However, Unraid doesn't show the encrypted volume properly before starting the array, already (after boot) Also, when usind the "failing" ssd in another pool (single, not raid) it's working properly. The combination of the "failing" ssd with a different HDD continued to fail, but the combination of the other "working" ssd with the other HDD did not fail after many reboots. (logs attached) So it seems to me that this particular disk is not working properly in a (encrypted) btrfs raid1 (pool). Could it be due to the pcie -> sata addon card they are attached to (all 3)? I may try to change ports or use the pool without encryption. 1a_before-reboot-diagnostics-20210830-2036.zip 1b_after-reboot-diagnostics-20210830-2100.zip 2a_before-reboot-diagnostics-20210901-1613.zip 2b_after-reboot-diagnostics-20210901-1735.zip 3a_before-reboot-diagnostics-20210901-2343.zip 3b_after-reboot-diagnostics-20210901-2351.zip
-
I managed to get logs before and after rebooting when the problem occured (attached). This time, I created a new pool (different name) from the same ssd drives just before it happened. With the old name, it did'nt happen in the last 10 +- 2 reboots. So maybe it's a cache management issue after all? Best regards after-reboot.zip before_reboot.zip
-
Hey everyone, thanks for sticking with me. In the meantime, I moved my hard drives to completely new hardware. The problem persists: Sometimes after reboots, the encryption symbol of the second cache disk goes missing and when the array starts, it's throwing the "missing disk" errors. Furthermore, I have a feeling that it appears more often when there was data written to the disk before rebooting - maybe a coincidence and not a causality... When I changed the disk order in the pool, the disk went missing as well, unfortunately losing all its data. This leads me to the conclusion that the ssd (controller) is damaged. I will continue to try and grab logs before and after a reboot with the problem occuring.
-
Hey, did you ever find out what's the issue with the slow ui during heavy hdd loads? Best regards
-
Thanks for looking into this 😃 I will try to get the logs in this order (after my vacations). From the current point of view, do you think it's some hardware failure? Best regards
-
Alright, it just started happening again. Here is a log. The thing is, it only occurs after restarts - not while running, so I can't really provide logs from before. One thing i noticed is the encryption symbol (green lock, left from the pool name) was there before the reboot and now is gone. So maybe it's some issue with the drive header being corrupted? server-diagnostics-20210716-1300_again.zip
-
I tried this previously as suggested by some other post (and intended to point out with "When setting up the pool (again) everything works fine"), but it didn't help making the pool consistent over reboots/time. The last time I tried this, the problem reoccured after a while. I checked the SSD but it seems OK, data is stored persistently for a week even without power. server-diagnostics-20210714-1857-newpool.zip
-
my bad, you can find them attached to the previous post
-
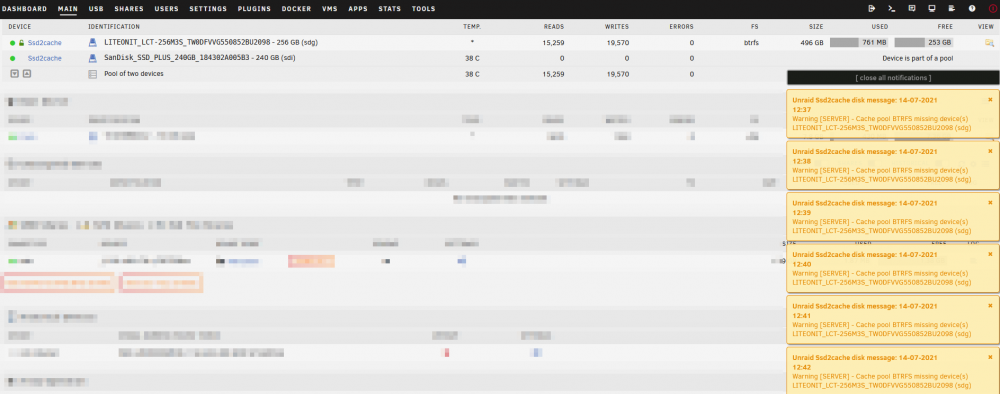
Greetings everyone, I do have a similar problem, but there is a key difference: Only after rebooting the server, my cache pool device can not be reassigned. So my server starts throwing this error message every minute: Cache pool BTRFS missing device(s). Then of course the "pool" continues on a single drive only. Logs below. Consequently, I can not run the balance command to raid1. The pool size is displayed as the sum of both drives, which should not be the case, free space is displayed correctly, though. When setting up the pool (again) everything works fine with raid1 and r/w access. Curiously, the missing device is displayed as the one continuing to work. But maybe thats just for identification of the respective pool. When I'm using the SSDs individually, they work as intended. They are even attached to the same SATA controller. I'm happy to get your opinions. Best regards UNRAID Version: 6.9.2 server-diagnostics-20210714-1540.zip
-
This would actually be the thing I'm looking for. I would like to assign one gpu to multiple VMs. Can we somehow make this work? Maybe as an Unraid plugin? rel: https://github.com/DualCoder/vgpu_unlock


