




mproberts
Members
-
Joined
-
Last visited
Everything posted by mproberts
-
I am having the same issue: operation failed: unable to find any master var store for loader: /usr/share/qemu/ovmf-x64/OVMF_CODE-pure-efi.fd Unraid is clean - no special configs and should work with the default settings (validated locations, etc) I also don't have another VM to use to edit the nvram line.
-
Understood. Thanks for the time!
-
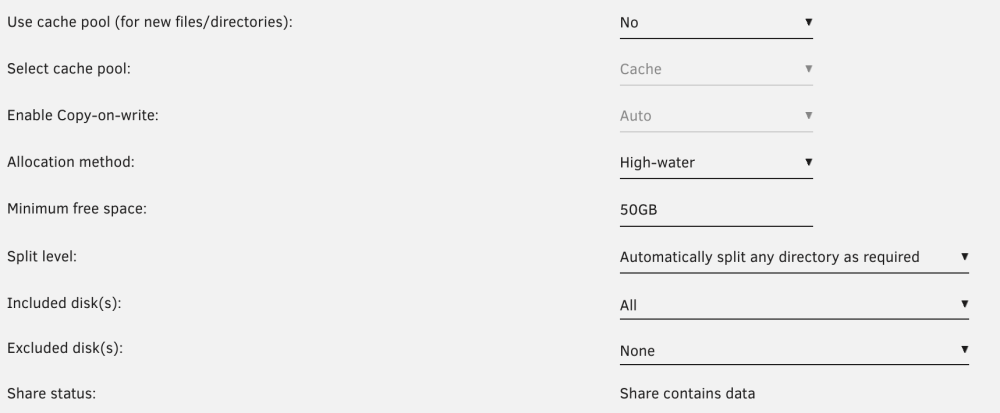
To add, thank you for the link (note: read the manual). So looks like I'll be going for third pass on high-water. And ignore the 80% warnings?
-
Yes, I believe...
-
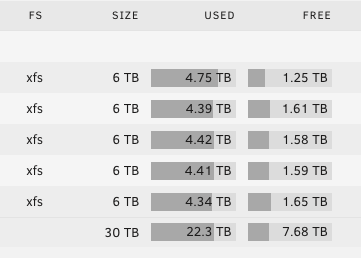
Quick question - as my array fills I understand it fills one disk to a point, then the next disk, etc. As I near the first 80% warning, will the disk at/over 80% continue to fill - or will it stop at a percentage (90%) and start on the next disk? IE, will I get an 80% warning on disk 1 below, then UnRaid will start using disk 2 until 80%, then disk 3? Trying to maximize my 7.5TB free but have a safe buffer.
-
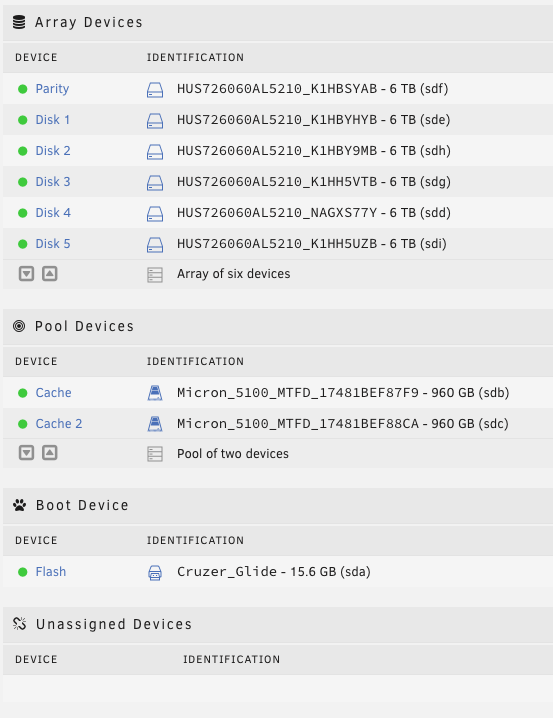
I'm using a Dell T710 for Unraid 6.11.5. This has 8 internal slots for drives and I'm currently using two of those for the Cache drives. What are my options to move the Cache drives? I'd like to use all 8 slots for the array to expand my overall storage. I am using a Dell H310 HBA card in IT Mode - with both channels used for the drive cages. I also have an unused eSata card installed. Use the eSata card for an external enclosure to house the SSD drives (create a new pool, or use Unassigned Drives)? Current Config: Dell T710 II - Two x5690 Xeon CPU’s (12 cores, 3.47 Ghz) 96GB DDR3 Mulit-bit ECC Ram Dual 1100 watt PS Nvidia Quadro P2000 video card for transcoding (love the T710 for this easy install as opposed to the R710) Dell H310 HBA card – IT Mode (6) Hitachi HUS726060AL5210 6TB SAS Drives (30TB Array) (2) Micron 5100 MTFD - Enterprise 980GB SSD Drives (Cache) Dell / Intel XYT17 / X520-DA2 10GB FH Network Adapter (2 ports) running as bonded, active-backup Thoughts and advice much appreciated.
-
That did it! I'd thought of the spaces in the Windows directory earlier, but assumed since the OS (UnRaid & Krusader) saw it and worked to browse it was ok. Probably a best practice to follow anyway (no spaces) when mixing OS's. Thank you!
-
root@Wilhelmina:~# df -a Filesystem 1K-blocks Used Available Use% Mounted on rootfs 49391344 2174116 47217228 5% / proc 0 0 0 - /proc sysfs 0 0 0 - /sys tmpfs 32768 1192 31576 4% /run /dev/sda1 15248800 965472 14283328 7% /boot /dev/loop0 - - - - /lib/firmware overlay 49391344 2174116 47217228 5% /lib/firmware /dev/loop1 - - - - /lib/modules overlay 49391344 2174116 47217228 5% /lib/modules hugetlbfs 0 0 0 - /hugetlbfs devtmpfs 8192 0 8192 0% /dev devpts 0 0 0 - /dev/pts tmpfs 49474148 0 49474148 0% /dev/shm fusectl 0 0 0 - /sys/fs/fuse/connections cgroup_root 8192 0 8192 0% /sys/fs/cgroup cpuset 0 0 0 - /sys/fs/cgroup/cpuset cpu 0 0 0 - /sys/fs/cgroup/cpu cpuacct 0 0 0 - /sys/fs/cgroup/cpuacct blkio 0 0 0 - /sys/fs/cgroup/blkio memory 0 0 0 - /sys/fs/cgroup/memory devices 0 0 0 - /sys/fs/cgroup/devices freezer 0 0 0 - /sys/fs/cgroup/freezer net_cls 0 0 0 - /sys/fs/cgroup/net_cls perf_event 0 0 0 - /sys/fs/cgroup/perf_event net_prio 0 0 0 - /sys/fs/cgroup/net_prio hugetlb 0 0 0 - /sys/fs/cgroup/hugetlb pids 0 0 0 - /sys/fs/cgroup/pids tmpfs 131072 2240 128832 2% /var/log cgroup 0 0 0 - /sys/fs/cgroup/elogind rootfs 49391344 2174116 47217228 5% /mnt tmpfs 1024 0 1024 0% /mnt/disks tmpfs 1024 1024 0 100% /mnt/remotes tmpfs 1024 0 1024 0% /mnt/addons tmpfs 1024 0 1024 0% /mnt/rootshare nfsd 0 0 0 - /proc/fs/nfs nfsd 0 0 0 - /proc/fs/nfsd /dev/md1 5858435620 4394856084 1463579536 76% /mnt/disk1 /dev/md2 5858435620 4394282504 1464153116 76% /mnt/disk2 /dev/md3 5858435620 4396368904 1462066716 76% /mnt/disk3 /dev/md4 5858435620 4395751364 1462684256 76% /mnt/disk4 /dev/md5 5858435620 3561133184 2297302436 61% /mnt/disk5 /dev/sdb1 1875382960 467431776 1406625568 25% /mnt/cache shfs 29292178100 21142392040 8149786060 73% /mnt/user0 shfs 29292178100 21142392040 8149786060 73% /mnt/user /dev/loop2 104857600 16292992 87988752 16% /var/lib/docker /dev/loop2 104857600 16292992 87988752 16% /var/lib/docker/btrfs /dev/loop3 1048576 4164 926140 1% /etc/libvirt nsfs 0 0 0 - /run/docker/netns/default //BACKUP/UnRaid OS Backup 37043960800 20978234480 16065726320 57% /mnt/remotes/BACKUP_UnRaid OS Backup nsfs 0 0 0 - /run/docker/netns/bb81da434bbc nsfs 0 0 0 - /run/docker/netns/65b742e4bef7 nsfs 0 0 0 - /run/docker/netns/6a03bf945432 nsfs 0 0 0 - /run/docker/netns/22334e7d40a0 root@Wilhelmina:~#
-
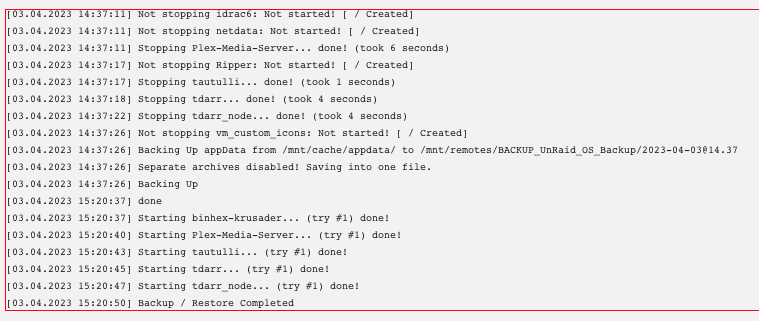
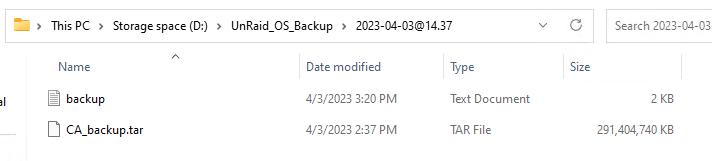
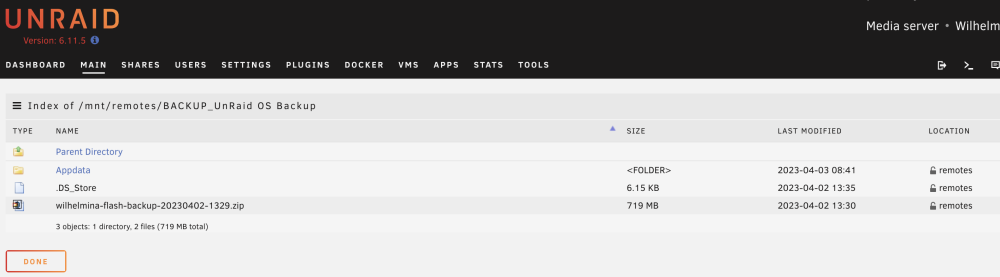
Target directory from UnRaid below. I tried target configs with both: /mnt/remotes/BACKUP_UnRaid OS Backup/ and /mnt/remotes/BACKUP_UnRaid OS Backup/Appdata/ Aside from my flashbackup file and the .DS_Store file (from my Mac touching the directory), there are no other files in the target directory.
-
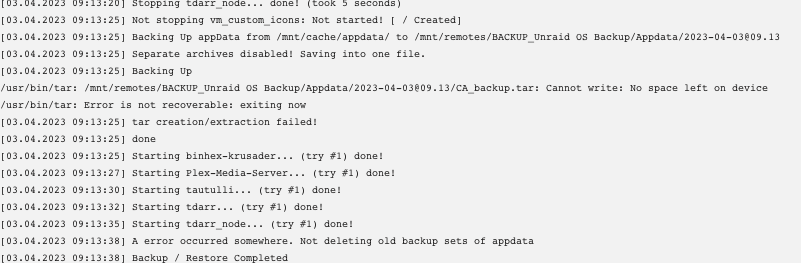
Trying to use CA Appdata 2.5 using /mnt/remotes for destination. I am getting the error: CA_backup.tar: Cannot write: No space left on device. My remote target is an SMB share properly set up and working (I can browse and write from Plex) and with 16tb free. Any thoughts?

-
The Docker.Patch plugin fixed it! Thank you for taking the time.
-
Just recently, my TDARR docker updates are showing "unavailable". I read a couple of posts that mention checking DNS or running a script, but that seemed to be for those where no docker updates were working. This is only happening with TDARR. TDARR support said they are not aware of an issue. Any thoughts or guidance? Screenshot 2023-02-15 at 4.38.38 PM
-
Fixed! Removing second node port from Server and the only/one node port from Node restored the containers!









