




Przemek
Members
-
Joined
-
Last visited
-
@JorgeB you were right. Thank you. I have run the memtest and it got failed after couple of seconds. I swap the memory modules between slots to be sure is the memory module and not the socket or something else. One of the module was failing. I'll send it back to warranty but keep an eye how the system stability looks now. Do you know any tools to be notified once some corruption occur in the system. Does the scrub do the job? If yes, how often do you recommend to run it?
-
Dear Unraid Community, Out of nowhere, my cache pool and some shares become read-only. This is the second time I face such issue. First time I though it just some hiccup and and I reformat the cache pool drives and recover the filesystem. But this happened to me again. I would like to find the root cause. Would you please help me and direct me, what should I check first? I am attaching current diagnostics: .tower-diagnostics-20260201-1551.zip
-
I tried adding more memory since that was my main suspect, and luckily, the problem hasn't reoccurred since then.
-
Hello, is anybody able to help me with this?
-
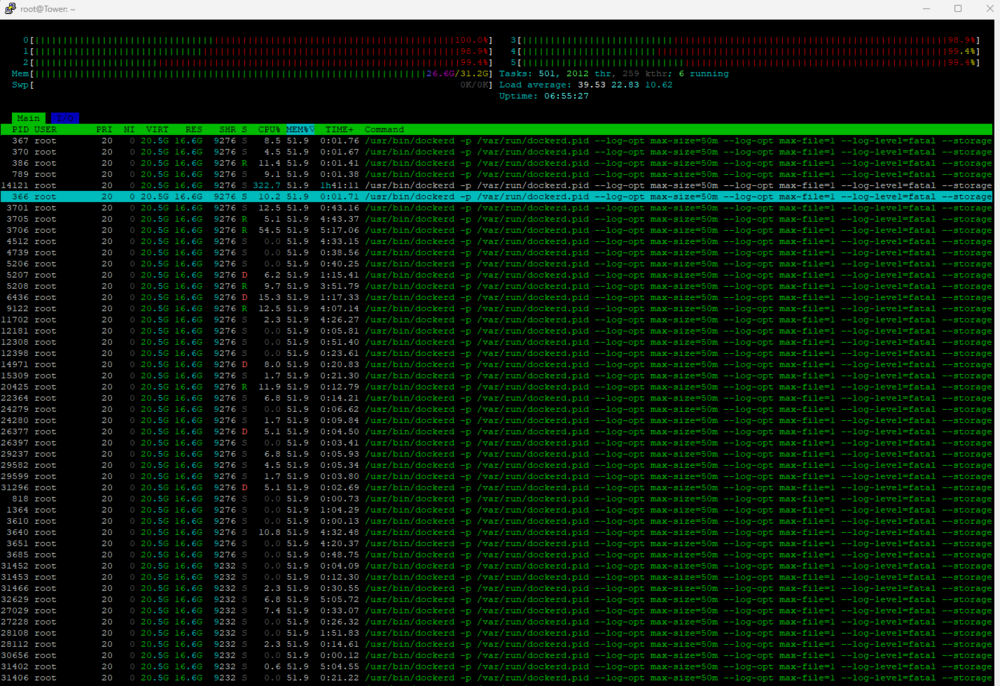
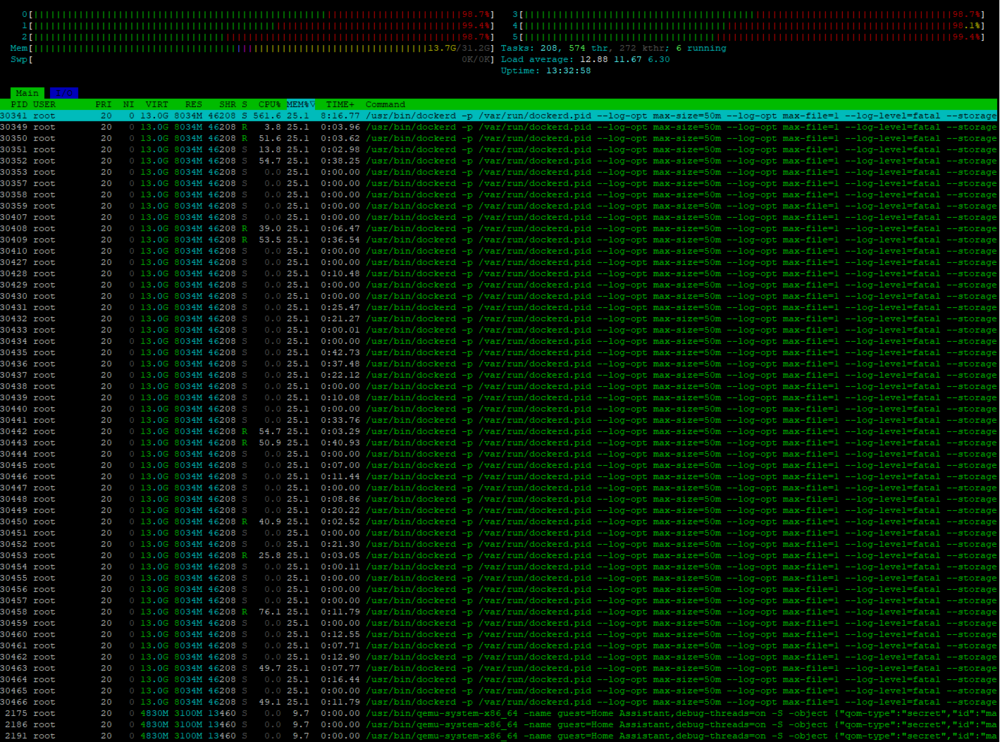
Hello Dear community, I've been struggling with server crashes during appdata backups. From my observations, it doesn't matter which container is being backed up - it crashes randomly. While trying to understand this better yesterday, even when I pressed "Manually Run Backup" and then stopped the backup process to check something, the server crashed anyway. So there must be some kind of process initiated at the beginning that causes a memory leak or something else. I ran htop (while backup run) and sorted by memory usage. I noticed a bunch of /usr/bin/dockerd processes were slowly eating up the memory which was still available. I didn't want my server to crash, so around 90% of memory usage I went to settings and disabled Docker service. After that, the memory was freed up, and I was able to enable Docker again. I tried changing the method to stop all containers, perform a backup, and start them again, but this didn't help either. I also disabled the USB Flash backup and compression, but this didn't resolve the issue either. Diagnostic attached. tower-diagnostics-20250105-1941.zip
-
Sorry, I didn't post the screenshot earlier. There is no one particular docker which consume RAM. Seems it is the docker itself, as all of the processes share the same amount memory.
-
Around 40 right now.
-
Additional information: I ran htop and sorted by memory usage. I noticed a bunch of /usr/bin/dockerd processes were slowly eating up the memory until the server crashed. I didn't want my server to crash, so I went to settings and disabled Docker before it happened. After that, the memory was freed up, and I was able to enable Docker again.I tried changing the method to stop all containers, perform a backup, and start them again, but this didn't help either. I also disabled the USB Flash backup, but this didn't resolve the issue.
-
Hello @KluthR Since around mid-November, I've been struggling with server crashes during appdata backups. Going through this thread, I've noticed at least two similar situations since November. From my observations, it doesn't matter which container is being backed up - it crashes randomly. While trying to understand this better yesterday, even when I pressed "Manually Run Backup" and then stopped it to check something, the server crashed anyway. So there must be some kind of process initiated at the beginning that causes a memory leak or something else. Do you have any ideas what to check and where I should start?
-
Hello Dear Community, For the past 3 weeks, I have been dealing with my Unraid server crashing every Saturday night. When I wake up on Saturday morning, Unraid is completely unresponsive. I cannot SSH into it or access it via the GUI. I have managed to determine that this occurs around 3 AM when the appdata backup starts. I am using Appdata Backup (2024.11.21) for this purpose. I suspect that at some point the RAM becomes full and all processes stop, but I am unable to determine what exactly is causing this. I have been using the Appdata Backup plugin successfully until now, so I believe one of the Docker images might be causing this issue, but I don't know how to identify which one. I am attaching some screenshots from Netdata for the 3 AM period and diagnostics after the crash (though I'm not sure if Diagnostic will help). I would appreciate any suggestions on what I can do or check. tower-diagnostics-20241214-0912.zip
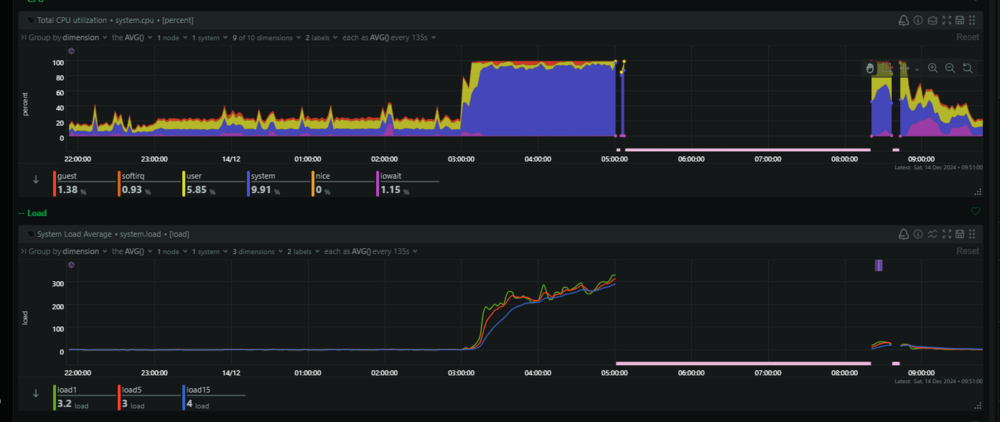
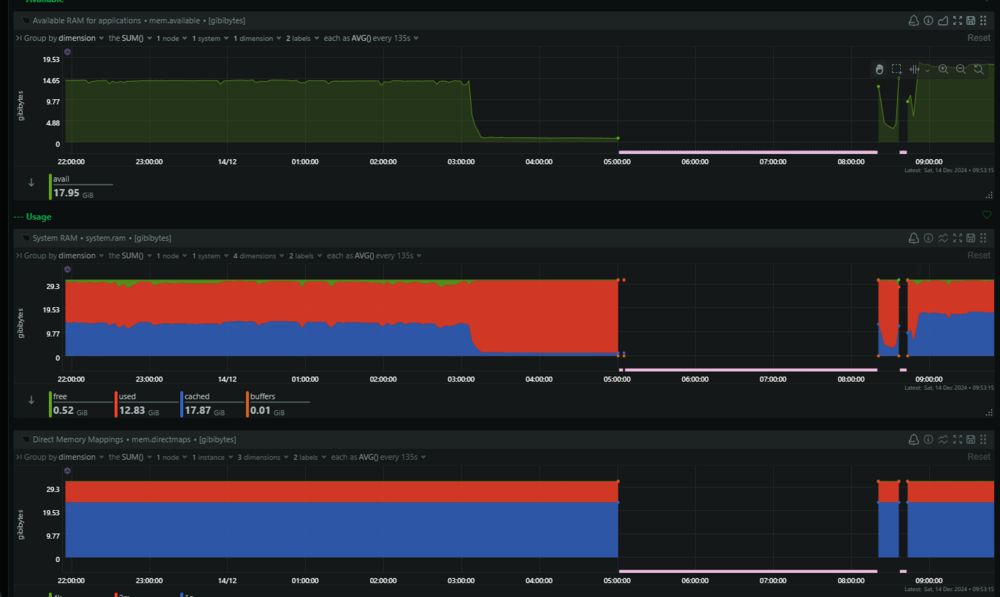
-
Driver re-formatted and scurbing done without errors. Anything else I should check? Do you recommend to run scrub from time to time?
-
Is this the correct guide to follow along to do the re-formatting? https://docs.unraid.net/unraid-os/manual/storage-management/#reformatting-a-drive
-
I rebooted the server and run Scrub but it seems to be aborted after 3 minutes. tower-diagnostics-20240603-1339.zip
-
I clicked on "Scurb" with tic on "Repair corrupted blocks". But it seems to aborted it immediately. tower-diagnostics-20240603-1227.zip
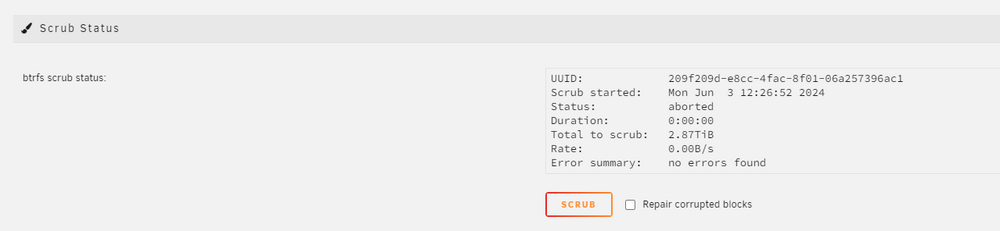
-
Hello, I think I have a problem with one of my array drives. Last year, I replaced a few drives with WD RED Pros, and a couple of days later, I saw a bunch of CRC errors for one drive, and then for another one (both new WDs). I thought it could be something with the SATA cables and replaced them. The issue seemed to be resolved until now. One drive's SMART report has one attribute marked as an error, but since the cable replacement, it has remained at the same level. Recently, however, I noticed that I was unable to delete or create any files in one of my shares, and it turned out that the file system was read-only. I restarted the Unraid server, and it returned to normal operation. I've noticed a "BTRFS error (device md3p1): read time tree block corruption detected on logical" error. md3p1 seems to be the one that still has SMART errors. Does this mean it needs to be replaced, or what are your suggestions? Diagnostic attached. tower-diagnostics-20240602-2108.zip




