




TurboStreetCar
Members
-
Joined
-
Cant install new version because the minimum version is still set to 7.0. I could try removing that from the PLG file and try installing. Maybe ill give that a shot. But it works with the V10.02 just fine on pre V7 unraid.
-
@VladoPortos Much appreciated. Question, would it be possible for you to update the archive file for version 2024.10.02 for those of us not using Unraid Version 7? I attempted to create my own archive file, but when installing the plugin, it downloads the archive txz from github and overwrites the custom txz archive file. Not sure what the best way to go about this is. To fix on pre Unraid version 7, you must upload a fixed folder.js file, and copy it to the correct directory manually. In my experience, folders still work without the fix, but creating new folders is broken. Ive attached a fixed folder.js file for pre Unraid Version 7. It must be placed into the directory "/usr/local/emhttp/plugins/folder.view/scripts" after installation for anyone attempting to fix in the mean time. folder.js
-
Are there any plans to implement user permissions? For example an admin user that has access to settings/config, and other users that can only view cameras?
-
I agree, but i didnt know if the ZFS part needed to be there or not, so i figured id leave it alone.
-
Figured i would put the whole script here for anyone else looking to make this change. One thing to note, the origional trim function is run with an echo, which outputs to the syslog information about what was trimmed. The later trim function has no echo statement and will not output any data to the syslog. Ive added an echo statement that outputs that information to the syslog. The updated script: #!/usr/bin/php -q <?PHP /* Copyright 2005-2023, Lime Technology * Copyright 2012-2023, Bergware International. * * This program is free software; you can redistribute it and/or * modify it under the terms of the GNU General Public License version 2, * as published by the Free Software Foundation. * * The above copyright notice and this permission notice shall be included in * all copies or substantial portions of the Software. */ ?> <? $docroot = $docroot ?? $_SERVER['DOCUMENT_ROOT'] ?: '/usr/local/emhttp'; require_once "$docroot/webGui/include/Wrappers.php"; extract(parse_plugin_cfg('dynamix',true)); // cron operation if ($argc==2 && $argv[1]=='cron') { // trim btrfs, xfs //echo shell_exec("fstrim -va 2>/dev/null"); // trim zfs zfs_trim(false); //exit(0); } // add translations $_SERVER['REQUEST_URI'] = 'settings'; $login_locale = _var($display,'locale'); require_once "$docroot/webGui/include/Translations.php"; function write(...$messages){ $com = curl_init(); curl_setopt_array($com,[ CURLOPT_URL => 'http://localhost/pub/plugins?buffer_length=1', CURLOPT_UNIX_SOCKET_PATH => '/var/run/nginx.socket', CURLOPT_POST => 1, CURLOPT_RETURNTRANSFER => true ]); foreach ($messages as $message) { curl_setopt($com, CURLOPT_POSTFIELDS, $message); curl_exec($com); } curl_close($com); } function is_hdd($disk) { $disk = explode('/',$disk); $disk = preg_replace('/^(sd[a-z]+|nvme[0-9]+n1)p?1$/','$1',end($disk)); return file_get_contents("/sys/block/$disk/queue/rotational")==1; } function zfs_info($name) { $trim = preg_replace('/(.$)/',' $1',exec("zfs list -Ho used $name"))."iB"; $bytes = exec("zfs list -Hpo used $name"); exec("zpool list -vHP $name|grep -Po '^\s+\K/\S+'",$devs); foreach ($devs as &$dev) if (is_hdd($dev)) $dev = ''; return "/mnt/$name: $trim ($bytes bytes) trimmed on ".implode(', ',array_filter($devs)); } function zfs_trim($write) { if (!file_exists('/proc/spl/kstat/zfs/arcstats')) return; exec("zfs list -d0 -Ho name",$pools); foreach ($pools as $name) { if ($write) { write("/mnt/$name: ... <i class='fa fa-spin fa-circle-o-notch'></i>\r"); if (exec("zpool trim -w $name 2>&1")=='') write(zfs_info($name)."\r","\n"); else write("\r"); } else { if (exec("zpool trim -w $name 2>&1")=='') echo zfs_info($name)."\n"; } } } write(_("TRIM operation started")."\n","\n","\n"); echo "Trim Operation Started\n"; // trim btrfs, xfs exec("findmnt -lnt btrfs,xfs -o target,source|awk '\$2!~\"\\\\[\"{print \$1,\$2}'",$mounts); foreach ($mounts as $mount) { [$target,$source] = explode(' ',$mount); if (is_hdd($source)) continue; write("$target: ... <i class='fa fa-spin fa-circle-o-notch'></i>\r"); $trim = exec("fstrim -v $target 2>/dev/null"); echo $trim,"\n"; //Echo information to syslog. if ($trim) write("$trim on $source\r","\n"); else write("\r"); } // trim zfs zfs_trim(true); write(_("Finished")."\n",'_DONE_',''); echo "Trim Operation Finished\n"; ?>
-
Hello, i was having a problem with scheduled trim. It seems that when you run the ssd_trim script manually in a terminal, or by clicking the "trim now" button in the scheduler page, the script would run as expected, but when the script was run on a cron schedule, it would bypass the check to see if the disk was a "spinning disk" and trim ALL drives. With the help of members in the general support section, it was determined the initial check in the script, checks to see if the script is being run by a cron job, and if so, runs trim on ALL drives. I believe this is a bug, unless it is the intended functionality to run a trim on all drives, regardless of SSD/HDD when using the cron schedule. Link to thread of original issue:
-
Trim just ran on the new script with the cron check commented out as shown above. Script ran as i now expected it to run, gave me output to the ssd_trim.log file specified, and skipped the spinning disks. Looks like its fixed. Marking the above post as the solution and going to make a post in bug reports. Thanks so much!!!!
-
@shorty_ Ah Ha! I think thats the key right there! I wonder why they have it check for to see if its running as a cron job, and then have it run differently? Maybe thats a bug? I will make those changes and change the schedule to run it again later tonight to see if it runs properly and report back!
-
OK so i added some debug commands to the ssd_trim script found in /usr/local/emhttp/plugins/dynamix/scripts/ssd_trim. This is the final function of the script now: $myfile = fopen("ssd_trim.log", "a"); $timestamp = date("m/d/Y - H:i:s"); ### Open Log File fwrite($myfile,"Trim Started at $timestamp\n\r"); ### Write Timestamp of beginning of Trim write(_("TRIM operation started")."\n","\n","\n"); // trim btrfs, xfs exec("findmnt -lnt btrfs,xfs -o target,source|awk '\$2!~\"\\\\[\"{print \$1,\$2}'",$mounts); foreach ($mounts as $mount) { [$target,$source] = explode(' ',$mount); fwrite($myfile,"Checking Source: $source Target: $target\n\r"); ### Write current $source and $target being checked if (is_hdd($source)) continue; fwrite($myfile,"$source Is HDD\n\r"); ### Result of HDD Check write("$target: ... <i class='fa fa-spin fa-circle-o-notch'></i>\r"); $trim = exec("fstrim -v $target 2>/dev/null"); if ($trim) write("$trim on $source\r","\n"); else write("\r"); if ($trim) fwrite($myfile, "Trimming $source\n\r"); else fwrite($myfile, "Not Trimming $source\n\r"); ### Write to log file when drive is trimmed } // trim zfs zfs_trim(true); write(_("Finished")."\n",'_DONE_',''); fwrite($myfile, "Finished Trim \n\r\n\r\n\r"); ### Write end of trimming operation fclose($myfile); ### Close log file When i run this in a terminal using the command: root@Backup:/usr/local/emhttp/plugins/dynamix/scripts# php ssd_trim The log file received this output: Trim Started at 07/06/2024 - 13:47:42 Checking Source: /dev/md1p1 Target: /mnt/disk1 Checking Source: /dev/nvme0n1p1 Target: /mnt/cache /dev/nvme0n1p1 Is HDD Trimming /dev/nvme0n1p1 Checking Source: /dev/sde1 Target: /mnt/cctv Checking Source: /dev/nvme1n1p1 Target: /mnt/deluge_pool /dev/nvme1n1p1 Is HDD Trimming /dev/nvme1n1p1 Checking Source: /dev/sdb1 Target: /mnt/plex /dev/sdb1 Is HDD Trimming /dev/sdb1 Checking Source: /dev/loop2 Target: /var/lib/docker /dev/loop2 Is HDD Trimming /dev/loop2 Checking Source: /dev/loop3 Target: /etc/libvirt /dev/loop3 Is HDD Trimming /dev/loop3 Finished Trim I received this output ALSO when i click the "Trim Now" button in the scheduler page. HOWEVER........ I changed the schedule to run a trim at 1400 Hours (44 minutes ago, my local time) and it is taking WAY longer to run, AND im receiving "disk full" errors in my Frigate container. SO i checked "system processes" on the tools page, and i see these entries related to SSD Trim: root 888 0.0 0.0 3972 2832 ? S 14:00 0:00 /bin/sh -c /usr/local/emhttp/plugins/dynamix/scripts/ssd_trim cron|logger &> /dev/null root 911 0.0 0.0 95616 27620 ? SL 14:00 0:00 /usr/bin/php -q /usr/local/emhttp/plugins/dynamix/scripts/ssd_trim cron root 912 0.0 0.0 2588 900 ? S 14:00 0:00 logger root 913 0.0 0.0 3976 2880 ? S 14:00 0:00 sh -c fstrim -va 2>/dev/null root 914 0.0 0.0 3332 1068 ? D 14:00 0:01 fstrim -va Which leads me to believe, that its running the same script that im running both manually in terminal, and by hitting the Trim Now button. So im not sure whats going on, but it definitely seems to be running a different script on the schedule vs pressing the trim now button, or running that same script in a terminal. Is there anything i can do to more thoroughly check what is the difference between these two different methods of running (seemingly) the same script?
-
Hmm. I think before i do this, im going to try to add a debug line to the script to write an output to a file to make sure the scheduled trim is running the same script.
-
Thats what i would expect too, but seems to be different. Maybe its running with a different level of permission or something? Ill admit when it comes to these things its beyond my depth. I can google some code stuff and get by, but ill admit im not sure how to diagnose whats going on. It doesnt seem unraid has user settable mount options. How would i go about trying this? I guess another question, If i have the drives set for "AutoTrim = ON", do i need to run a scheduled trim at all?
-
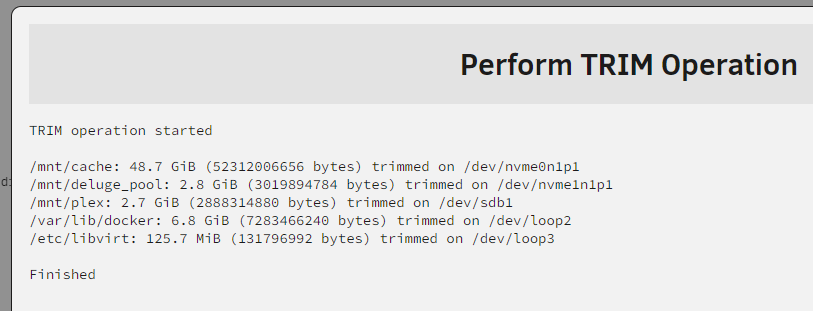
Yea I'm not sure why it didn't show cache. When i ran it, it displayed the path, but then it seemed to overwrite that line with the deluge pool line. I just ran it again, and it shows cache now. Cache has always existed and was never disconnected. So not sure why it wasn't listed. Ive attached my diagnostic Zip. @shorty_ I changed the trim schedule this past Sunday, to run it Tuesday instead of on Monday, so that should have taken care of that. backup-diagnostics-20240703-1416.zip
-
Im using a WD Purple HDD. It apparently supports trim, but this may be a bug in the scheduled trim function of unraid, as the script checks for "spinning disks", but scheduled trim seems to operate differently then the script in the dynamix folder.
-
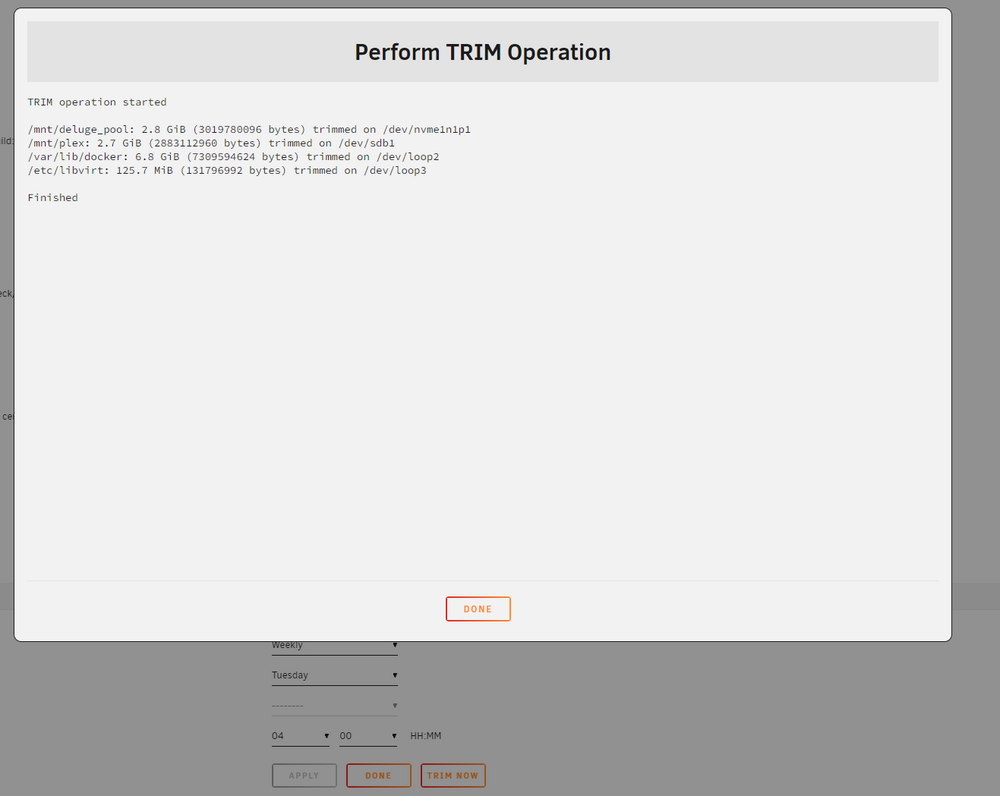
@_Shorty and @JorgeB : that back and fourth you guys just had is a little above my level, so im not sure. I just ran a "trim now" from the schedule page, and this was the results. So it appears the scheduled trim function, is separate from the script at /usr/local/emhttp/plugins/dynamix/scripts. I ran the command @JorgeB mentioned to check the other script and this was the output: root@Backup:/# cat /boot/config/plugins/dynamix/ssd-trim.cron # Generated TRIM schedule: 0 4 * * 2 /usr/local/emhttp/plugins/dynamix/scripts/ssd_trim cron|logger &> /dev/null So it seems to reference the other script when ran. Is there a way i can find out what is actually running when the scheduled trim is triggered? It seems like it must be a different script/command then the script at that location, or else i wouldnt be getting mixed results. Is this potentially a bug that I've inadvertently discovered?
-
So I did a test, i changed the final function to this: exec("findmnt -lnt btrfs,xfs -o target,source|awk '\$2!~\"\\\\[\"{print \$1,\$2}'",$mounts); foreach ($mounts as $mount) { [$target,$source] = explode(' ',$mount); echo "before $source \r\n"; if (is_hdd($source)) continue; echo "continue $source \r\n"; write("$target: ... <i class='fa fa-spin fa-circle-o-notch'></i>\r"); $trim = exec("fstrim -v $target 2>/dev/null"); if ($trim) write("$trim on $source\r","\n"); else write("\r"); } And this was the output: root@Backup:/usr/local/emhttp/plugins/dynamix/scripts# php ssd_trim_test before /dev/md1p1 before /dev/nvme0n1p1 continue /dev/nvme0n1p1 before /dev/sde1 <------Does not continue before /dev/nvme1n1p1 continue /dev/nvme1n1p1 before /dev/sdb1 continue /dev/sdb1 before /dev/loop2 continue /dev/loop2 before /dev/loop3 continue /dev/loop3 So it seems when i run the script manually, it skips the drive, but when it runs on schedule, it definitely trims all the drives. So i guess, maybe its a different script that it runs on the schedule?



