




shabos
Members
-
Joined
-
Last visited
Everything posted by shabos
-
Replaced all disks with SMART errors, parity works now.
-
I did individual RAM tests on each pair and they passed. I think faulty disks is most likely the problem - I'm replacing disk 1, 5, 9 and 10. (Disk 7 is empty) I will let you know how it goes, will be a 3 day process at least. Thanks for the help.
-
Yes. I did a non-correcting check for a few minutes after two back to back parity correcting checks just to see if the errors still occured. I have definitely done correcting checks.
-
Sync errors are different every time, that box is indeed checked.
-
Hi I am getting sync errors every time I run a parity check. I have done a memtest for 24 hours and the RAM is solid, passed all the tests. At my wits end here - parity checks take 2 days! bitpartnas-diagnostics-20240517-0920.zip
-
Once again, after updating - it is still stuck on umounting disks. bitpartnas-syslog-20230904-1629.zip
-
Several problems with this: 1) When I started rebuilding the drive from parity it still said "unmountable" - not "rebuilding" or anything - I wasn't sure it was doing the right thing - so I canned it - this is poor UI 2) Once I formatted it - it still let me rebuild from parity. Why?? So then it merrily "rebuilt" for 2 days and did absolutely nothing in the end - poor design to still allow the rebuild button if it will only spin my entire array for 2 days to achieve nothing. Both of these issues are poor design and UI feedback - previously when I have installed a brand new unused drive and purposefully replaced a failed one, it would give the correct feedback (not "unmountable") - although that was on reiserfs - maybe different prompts for XFS? Frustrating to say the least.
-
No dude - it was marked as emulated and unmountable. I am a software engineer that has been using plex for 10 years - I'm not making this up - since the last few updates I have noticed a ton of errant behaviour - and the problem is its not reflected in the logs.
-
So why would unraid mark a brand new disk as unmountable when it has never been formatted?
-
Hi I wanted to replace an old drive that was possibly failing, and so I put in a new one. It was then immediately "unmountable file system". So I formatted it - then I started the data rebuild. The rebuild took 2 days and has just finished - the drive is still empty!!!! Please help. Thanks bitpartnas-syslog-20230831-1709.zip
-
Hi In the last while since I have formatted and upgraded most of my disks from Reiserfs to XFS, I am unable to stop the array - it keeps getting stuck unmounting disks. Please help! Thanks! bitpartnas-syslog-20230829-2022.zip
-
My point is this filesystem is SO much less robust than reiserfs - I've had multiple power failures, system interrupts, etc over more than 10 years - the moment I move to XFS - this is the second drive that has done this in 2 weeks (first one after a power failure), and they instantly corrupt. How is that remotely better? The point of unraid is to make sure I don't lose data..... this seems to be a massive step backwards. UFS explorer - am I going to have to use that in windows?
-
This is the outcome of a -vL operation: No resolution it seems? I'm out of ideas - did I really just lose 2TB of data because of an interrupted unmount???
-
I didn't, no
-
root@BitpartNas:~# blkid /dev/sda1: LABEL_FATBOOT="UNRAID" LABEL="UNRAID" UUID="B4EA-2880" BLOCK_SIZE="512" TYPE="vfat" PARTUUID="04dd5721-01" /dev/loop1: TYPE="squashfs" /dev/sdf1: UUID="03d2824f-a980-43d5-8c1f-3eb12afdff6b" BLOCK_SIZE="512" TYPE="xfs" PARTUUID="4bbd886f-1b64-4713-b938-1fd5f7f7d00e" /dev/md9p1: UUID="c90c83cb-1c67-431f-8fdb-f0efca047f4c" BLOCK_SIZE="512" TYPE="xfs" /dev/sdd1: UUID="c90c83cb-1c67-431f-8fdb-f0efca047f4c" BLOCK_SIZE="512" TYPE="xfs" PARTUUID="75b100a4-1383-468c-9afa-574ef8384a62" /dev/md2p1: UUID="391043f8-a362-42b4-9ca2-4d0a290f7b04" BLOCK_SIZE="512" TYPE="xfs" /dev/sdm1: UUID="c87871ca-05e8-4519-9179-447c1fb0de8c" BLOCK_SIZE="512" TYPE="xfs" PARTUUID="6b60ec31-8d56-4d0b-a9be-e3cd44de10b1" /dev/sdb1: UUID="d97cc953-ee9a-404f-83ba-c998aa13e771" UUID_SUB="063d30a7-a090-43fe-b6e3-7c2873febdec" BLOCK_SIZE="4096" TYPE="btrfs" /dev/md5p1: UUID="e6a6b944-0e65-48a5-9caf-e181a95ec119" BLOCK_SIZE="512" TYPE="xfs" /dev/sdk1: UUID="e6a6b944-0e65-48a5-9caf-e181a95ec119" BLOCK_SIZE="512" TYPE="xfs" PARTUUID="64267629-6e1c-4eb5-a5bc-885bc94d23dd" /dev/md11p1: UUID="03d2824f-a980-43d5-8c1f-3eb12afdff6b" BLOCK_SIZE="512" TYPE="xfs" /dev/md8p1: UUID="226ecde4-d538-4acb-a790-7931a52f70eb" BLOCK_SIZE="512" TYPE="xfs" /dev/sdi1: UUID="65411ed0-2cc7-46ee-822f-c7b8542ba8d2" BLOCK_SIZE="4096" TYPE="reiserfs" /dev/md1p1: UUID="c87871ca-05e8-4519-9179-447c1fb0de8c" BLOCK_SIZE="512" TYPE="xfs" /dev/sdg1: UUID="391043f8-a362-42b4-9ca2-4d0a290f7b04" BLOCK_SIZE="512" TYPE="xfs" PARTUUID="4551df66-7274-4a79-95f8-06c7d71b7584" /dev/md4p1: UUID="65411ed0-2cc7-46ee-822f-c7b8542ba8d2" BLOCK_SIZE="4096" TYPE="reiserfs" /dev/loop0: TYPE="squashfs" /dev/sde1: UUID="e4e076d9-a029-4d1f-b232-58c28e5f986f" BLOCK_SIZE="512" TYPE="xfs" PARTUUID="b12b60ba-9824-4bad-b01a-64c18740bef0" /dev/md10p1: UUID="e4e076d9-a029-4d1f-b232-58c28e5f986f" BLOCK_SIZE="512" TYPE="xfs" /dev/sdc1: UUID="226ecde4-d538-4acb-a790-7931a52f70eb" BLOCK_SIZE="512" TYPE="xfs" /dev/sdj1: UUID="0753e2e4-27f9-463f-bb93-34f446824e08" BLOCK_SIZE="4096" TYPE="reiserfs" /dev/md3p1: UUID="0753e2e4-27f9-463f-bb93-34f446824e08" BLOCK_SIZE="4096" TYPE="reiserfs" /dev/sdh1: PARTUUID="16d2ff3f-6584-46dd-9c12-2da4a8484628" root@BitpartNas:~# ^C root@BitpartNas:~# root@BitpartNas:~# fdisk -l /dev/sdl Disk /dev/sdl: 1.82 TiB, 2000398934016 bytes, 3907029168 sectors Disk model: ST2000DL003-9VT1 Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disklabel type: dos Disk identifier: 0x00000000 Device Boot Start End Sectors Size Id Type /dev/sdl1 64 3907029167 3907029104 1.8T 83 Linux root@BitpartNas:~#
-
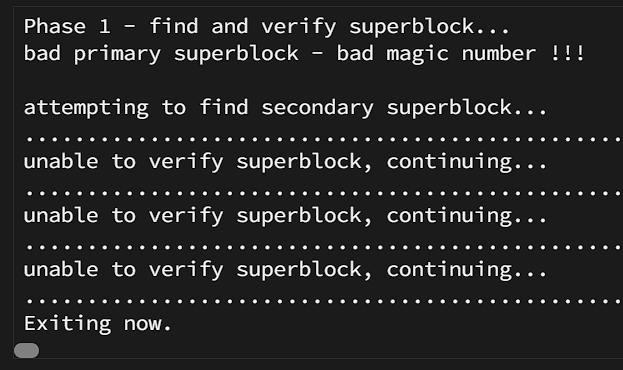
Can I run this while running the repair still? Should I cancel the repair? (It still hasnt found the second superblock)
-
It was definitely formatted and runnning - I used unBalance to fill it.
-
I'm using the GUI - with the -n parameter
-
I notice on the unmount - the drive in question wasn't in the unmount script: (Disk 6) - this possibly caused the array to stall on unmount and forced me to reboot. Aug 28 18:24:37 BitpartNas emhttpd: shcmd (172): /usr/sbin/zfs unmount -a Aug 28 18:24:37 BitpartNas emhttpd: shcmd (173): umount /mnt/user0 Aug 28 18:24:37 BitpartNas emhttpd: shcmd (174): rmdir /mnt/user0 Aug 28 18:24:37 BitpartNas emhttpd: shcmd (175): umount /mnt/user Aug 28 18:24:37 BitpartNas emhttpd: shcmd (176): rmdir /mnt/user Aug 28 18:24:37 BitpartNas emhttpd: shcmd (178): /usr/local/sbin/update_cron Aug 28 18:24:37 BitpartNas emhttpd: Unmounting disks... Aug 28 18:24:37 BitpartNas emhttpd: shcmd (179): umount /mnt/disk1 Aug 28 18:24:37 BitpartNas kernel: XFS (md1p1): Unmounting Filesystem Aug 28 18:24:37 BitpartNas emhttpd: shcmd (180): rmdir /mnt/disk1 Aug 28 18:24:37 BitpartNas emhttpd: shcmd (181): umount /mnt/disk2 Aug 28 18:24:37 BitpartNas kernel: XFS (md2p1): Unmounting Filesystem Aug 28 18:24:37 BitpartNas emhttpd: shcmd (182): rmdir /mnt/disk2 Aug 28 18:24:37 BitpartNas emhttpd: shcmd (183): umount /mnt/disk3 Aug 28 18:24:38 BitpartNas emhttpd: shcmd (184): rmdir /mnt/disk3 Aug 28 18:24:38 BitpartNas emhttpd: shcmd (185): umount /mnt/disk4 Aug 28 18:24:39 BitpartNas emhttpd: shcmd (186): rmdir /mnt/disk4 Aug 28 18:24:39 BitpartNas emhttpd: shcmd (187): umount /mnt/disk5 Aug 28 18:24:39 BitpartNas kernel: XFS (md5p1): Unmounting Filesystem Aug 28 18:24:39 BitpartNas emhttpd: shcmd (188): rmdir /mnt/disk5 Aug 28 18:24:39 BitpartNas emhttpd: shcmd (189): umount /mnt/disk8 Aug 28 18:24:39 BitpartNas kernel: XFS (md8p1): Unmounting Filesystem Aug 28 18:24:39 BitpartNas emhttpd: shcmd (190): rmdir /mnt/disk8 Aug 28 18:24:39 BitpartNas emhttpd: shcmd (191): umount /mnt/disk9 Aug 28 18:24:39 BitpartNas kernel: XFS (md9p1): Unmounting Filesystem Aug 28 18:24:39 BitpartNas emhttpd: shcmd (192): rmdir /mnt/disk9 Aug 28 18:24:39 BitpartNas emhttpd: shcmd (193): umount /mnt/disk10 Aug 28 18:24:39 BitpartNas kernel: XFS (md10p1): Unmounting Filesystem Aug 28 18:24:39 BitpartNas emhttpd: shcmd (194): rmdir /mnt/disk10 Aug 28 18:24:39 BitpartNas emhttpd: shcmd (195): umount /mnt/disk11 Aug 28 18:24:39 BitpartNas kernel: XFS (md11p1): Unmounting Filesystem Aug 28 18:24:39 BitpartNas emhttpd: shcmd (196): rmdir /mnt/disk11 Aug 28 18:24:39 BitpartNas emhttpd: shcmd (197): umount /mnt/cache Aug 28 18:24:39 BitpartNas emhttpd: shcmd (198): rmdir /mnt/cache
-
Hi For some reason my drive was unmountable after a restart (I am regretting switching from Reiserfs!!!) - now the primary superblock is bad and searching for the secondary superblock has run almost 12 hours - and it's only a 2TB drive. It seems the FS was corrupted because I had to do a reboot while the drives were unmounting - I assume it was this drive that it was stuck on. Do I stop the operation and add -L to the parameters? How do I see if the drive is causing the FS to corrupt? Any helpful suggestions would be appreciated. bitpartnas-syslog-20230828-2054.zip
-
Legend. Worked like a charm.
-
Diagnostics bitpartnas-diagnostics-20230827-1012.zip
-
Hi One of my disks become unmountable after a power failure. After doing some searching the suggestion was that I remove it from the array and rebuild it using parity. So I did this, it said successful but still shows the same thing!!! Any suggestions would be helpful! bitpartnas-syslog-20230827-1711.zip
-
Hi I installed and ran this for the first time today and got the following: Lucee 5.3.10.120 Error (application) Message Error invoking external process Stacktrace The Error Occurred in /var/www/ScanControllers.cfm: line 2044 2042: <CFFILE action="write" file="#PersistDir#/#exe()#_lsblk_-o_export_dev_#DriveID##P##Part.Partitions[NR].PartNo#_exec.txt" output="/sbin/blkid #Args#" addnewline="NO" mode="666"> 2043: <CFIF URL.Debug NEQ "FOOBAR"><cfmodule template="cf_flushfs.cfm"></CFIF> 2044: <cfexecute name="/sbin/blkid" arguments="#Args#" variable="PartInfo2" timeout="90" /> 2045: <CFIF StripCRLF(PartInfo2) EQ ""> 2046: <!--- No output, try without partition id ---> called from /var/www/ScanControllers.cfm: line 2013 2011: <CFSET Part.Partitions[NR].PartNo=ListGetAt(CurrLine,1,":",true)> 2012: <CFSET Part.Partitions[NR].Start=Val(ListGetAt(CurrLine,2,":",true))> 2013: <CFSET Part.Partitions[NR].End=Val(ListGetAt(CurrLine,3,":",true))> 2014: <CFSET Part.Partitions[NR].Size=Val(ListGetAt(CurrLine,4,":",true))> 2015: <CFSET Part.Partitions[NR].FileSystem=ListGetAt(CurrLine,5,":",true)> called from /var/www/ScanControllers.cfm: line 1860 1858: </CFIF> 1859: </CFLOOP> 1860: </CFLOOP> 1861: 1862: <!--- Admin drive creation ---> Java Stacktrace lucee.runtime.exp.ApplicationException: Error invoking external process at lucee.runtime.tag.Execute.doEndTag(Execute.java:266) at scancontrollers_cfm$cf.call_000155_000156(/ScanControllers.cfm:2044) at scancontrollers_cfm$cf.call_000155(/ScanControllers.cfm:2013) at scancontrollers_cfm$cf.call(/ScanControllers.cfm:1860) at lucee.runtime.PageContextImpl._doInclude(PageContextImpl.java:1056) at lucee.runtime.PageContextImpl._doInclude(PageContextImpl.java:948) at lucee.runtime.listener.ClassicAppListener._onRequest(ClassicAppListener.java:65) at lucee.runtime.listener.MixedAppListener.onRequest(MixedAppListener.java:45) at lucee.runtime.PageContextImpl.execute(PageContextImpl.java:2493) at lucee.runtime.PageContextImpl._execute(PageContextImpl.java:2478) at lucee.runtime.PageContextImpl.executeCFML(PageContextImpl.java:2449) at lucee.runtime.engine.Request.exe(Request.java:45) at lucee.runtime.engine.CFMLEngineImpl._service(CFMLEngineImpl.java:1216) at lucee.runtime.engine.CFMLEngineImpl.serviceCFML(CFMLEngineImpl.java:1162) at lucee.loader.engine.CFMLEngineWrapper.serviceCFML(CFMLEngineWrapper.java:97) at lucee.loader.servlet.CFMLServlet.service(CFMLServlet.java:51) at javax.servlet.http.HttpServlet.service(HttpServlet.java:764) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:227) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162) at org.apache.tomcat.websocket.server.WsFilter.doFilter(WsFilter.java:53) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:189) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:162) at org.apache.catalina.core.StandardWrapperValve.invoke(StandardWrapperValve.java:197) at org.apache.catalina.core.StandardContextValve.invoke(StandardContextValve.java:97) at org.apache.catalina.authenticator.AuthenticatorBase.invoke(AuthenticatorBase.java:541) at org.apache.catalina.core.StandardHostValve.invoke(StandardHostValve.java:135) at org.apache.catalina.valves.ErrorReportValve.invoke(ErrorReportValve.java:92) at org.apache.catalina.valves.AbstractAccessLogValve.invoke(AbstractAccessLogValve.java:687) at org.apache.catalina.valves.RemoteIpValve.invoke(RemoteIpValve.java:769) at org.apache.catalina.core.StandardEngineValve.invoke(StandardEngineValve.java:78) at org.apache.catalina.connector.CoyoteAdapter.service(CoyoteAdapter.java:360) at org.apache.coyote.http11.Http11Processor.service(Http11Processor.java:399) at org.apache.coyote.AbstractProcessorLight.process(AbstractProcessorLight.java:65) at org.apache.coyote.AbstractProtocol$ConnectionHandler.process(AbstractProtocol.java:890) at org.apache.tomcat.util.net.NioEndpoint$SocketProcessor.doRun(NioEndpoint.java:1789) at org.apache.tomcat.util.net.SocketProcessorBase.run(SocketProcessorBase.java:49) at org.apache.tomcat.util.threads.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1191) at org.apache.tomcat.util.threads.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:659) at org.apache.tomcat.util.threads.TaskThread$WrappingRunnable.run(TaskThread.java:61) at java.base/java.lang.Thread.run(Thread.java:829) Timestamp 8/11/23 7:37:22 PM SAST Any help would be appreciated! Thanks!
-
Ah good to know - if the drives aren't fried I will copy then!
