




Wachuwamekil
Members
-
Joined
-
Last visited
-
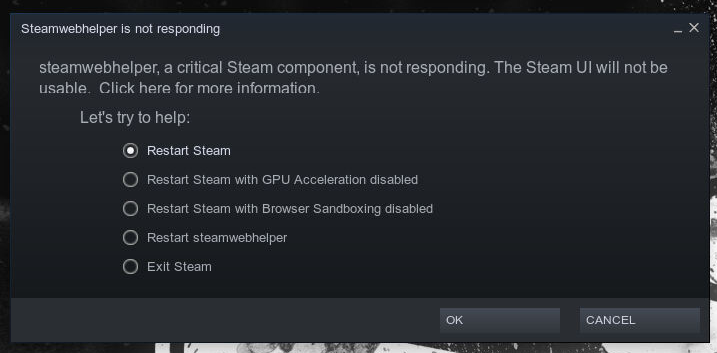
6:27PM CST Update - It looks like steam installs but does not boot strap and any time I start steam via the .sh script it segfaults and I get a dump. May need to open a bug for this one. I'm going to attempt a full install after cleaning everything up this evening. 5:54PM CST Update -- Ok so I got the docker to work but it kept failing on the install, I did some digging and saw that the script was failing with a dump. I took a swing and ran the steam.sh script with "sudo bash whatever" and it installed w/o a problem. We'll see if it keeps on 1:00pm CST Update -- I nuked everything, and started over from the app store docker. After a bit of mucking around I was able to get it working on via unraid app store, can't speak to why docker.compose was borking though. I don't honestly recall what I did to make it finally work I was doing so many things. -- <solved> The unraid version kept crashing, so I decided to use docker.compose manager and it was able to start up. I'm getting now "Steamwebhelper is not responding" error. Looking at the logs it isn't super clear what the issue is but I do see a random PID starting and stopping. I'm using a 1080ti, and have the GPU setup correctly (it's showing up in the container). I turned off any other docker that has that GPU associated with it (just my AI dockers). Every now and then in the steam bootstrap_log I'm seeing that it attempts to download an update finishes but skips applying it? It doesn't matter what option I select it still fails and pops this message back up. lmk if there is anything I can look at to troubleshoot this issue.
-
I've got a system upstream that uses lets encrypt and has it configured. Can I use this proxy manager as a transparent proxy to just pass along traffic to an upstream system without having to mess with the packets? The upstream system is very sensitive and tends to not like proxies trying to inspect traffic. I'd want to go from URL : 443 -> Nginx : URL Translate to IP :443 -> server ip : 443
-
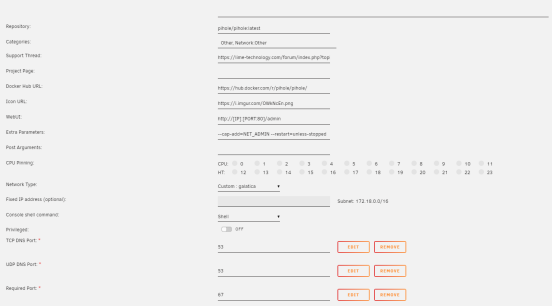
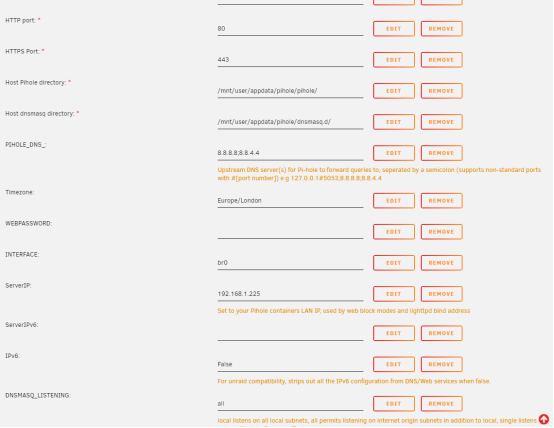
Hi All! I've been having issues getting this container configured. When I define an IP address I still get this error "Error starting userland proxy: listen tcp4 0.0.0.0:80: bind: address already in use." I don't see where else to define the container IP. I do have to use clean up app data every time I install otherwise it fails with another error message.
-
I was getting warnings that i was at 95% utilization of docker.img, so I increased it a ton to avoid the issue. I'm going to drop that back down to 30G and see if I can't find out what is chewing up space. This is likely related to all the moving around I had to do with system data. Is there a safe way to ensure that all array data/info gets moved to to appdata and domians on my cache drive? What started this whole thing was a 3GB drive that had errors, the drive was similar to the other one and I grabbed the wrong one. I verified SMART status to ensure I was acting on the correct drive. I do not, adding notifications is next on my list to tackle so I won't be in this position again.
-
Wachuwamekil changed their profile photo
-
Thank you fro the help trurl, that fixed the issue I really appreciate it. If you can review the diagnostics blob that would be awesome! thetwelve-diagnostics-20211126-2208.zip
-
Brilliant thank you, I'm going to make this change once mover fails and see what magic happens. I found this out the hard way, I've updated the labels to have the Serial number moving forward. I made a massive assumption that crashplan was able to backup everything needed, however when I was in the middle of this and I looked at the console it wasn't backed up correctly. I am revisiting my backup strategy and ensuring that crashplan is configured correctly. I'm also going to be doing an off site backup at a friends house and adding others as we get additional external drives. We are building a bit of a mesh backup network between friends and I'm going to take advantage of it. I appreciate the replies and feedback!
-
I'll start by saying I likely did everything wrong in this scenario. The Story: I have been acquiring upgrades for my server over the past year, and finally had a chance to add them all. Several 14T drives, an HBA card, and a cache drive. Drives were pre-cleared a long time ago and have just been sitting on my desk until I had time. I took a picture of my array before I shut it down so I would know what order drives were supposed to be in because also as part of this I had planned on labeling my drives in the system for easy identification. When looking at the picture I noticed there were a number of errors on one of the drives and thought that the drive is failing it's good that I am doing this maintenance. Parity at this point was good and all I needed to do is reconfigure the drives and add all the new stuff. This is also about the time I noticed my crashplan backups were not working as expected so I now have one copy of data that is parity protected ... I'm freaking out a bit at this point but feel comfortable knowing the parity is good. So in the process I added all the things and configured things to be correct as I thought they were. I selected the WRONG 14T drive as the parity drive. This started a parity rebuild, but it was going at a glacial pace ~700kb/s. So now I have no backup, no parity and this is where true panic sets in. After about 19 array restarts I was finally able to get the drive to function normally. I then used Unbalance to move all of my VM's and some of my ROM data to a safe drive since I was getting full write speed. This action caused those drives to get written to cache not the drive out right so now I have a 1TB cache drive full and mover won't move content over. My array is safe now, and the bad drive has been replaced, however now when I try to use mover to move data over it says that the cache is full and it can't move files. My question: So now I have good parity, a good drive in place of the bad drive, and my cache is full of actual data, how can I get that data moved over so that the system knows it is on the right drive? Every time I try to start mover it just says Cache is full, those shares are all set to Prefer cache but it shouldn't fail when it can't use cache. I'm kind of lost at this point. Lessons Learned: Use Hard drive serial numbers NOT it's place on the /dev/ file system to designate what it is if you are using an HBA controller.



