




Nodiaque
Members
-
Joined
-
Last visited
-
I know about the doc, I've read it many times. Using the CA is actually not supported, St least when I opened ticket since its not directly their container. It also says right at the start of the doc The Unraid template uses a community made image and is not officially supported by Immich This is for the aio. It is not official per immich, it's not even supported. Docker compose plugin is a way. Doing it manually with the other CA that are separate of each docker from the docker compose yaml is also supported since its the exact same docker as docker compose but with template. I got support on more then one occasion with using only the official docker, using compose or not. This AIO as 0 support from dev.
-
This is one way using this docker, that is all in one with the machine learning and doesn't use official image. The guide I provide some post behind is using all official container using unraid CA. It's replicating Docker Compose way of doing it without the plugin, all with CA. There's even a guide with all the setup for files which, since we are using official docker, we can now use all env variables properly. The choice is to the user in the end. I made the switch so I now have full support from Immich dev.
-
Someone said they downgrade when not in use? All slots are pcie 3.0 according to spec. It's also in the recommend slot from Dell to put gpu in
-
Restoring to a working version of your dB at the same version of the container... If you simply restore with the latest version, it's normal the issue is following.
-
Ah! Good to know
-
Yeah he's doing exactly the same as me but he automated it. I'm not very github / docker knowledable so I know nothing about automation. What he does is the automation check nightly if a new windroseserver/windroseserver docker image is built. If yes, import, extract /home/ue_user/app/ (where all the linux binary are) and then copy them into it's image. It's what I'm going but manually. We both use a debian-trixie image and we even have many things in comon on how our image are built. Maybe he looked at ich777 original work (or the one he based it off). In the end, it's not rocket science for that. He also start directly with debian-trixie-slim and build from there. while I start from a custom debian image ich777 keep updated (I have made mine but since I have nothing to keep everything updated automatically or simply notify, I still use his). Those "custom" image are tailored for Unraid thus better anyway (respect uid and guid as parameters, properly set permission on run, etc). edit: Restarting his docker (netdy tech blog) won't update your binary when looking at the code in github. It's a new docker image, so it's more then restart, you have to update the image, just like any normal docker image. edit 2: I did learn from his docker though. I didn't think I could copy files directly from another docker in a dockerfile. I'm currently testing it out. If it work, I'll have to learn automation for the next. Thing is now, how I find version since I was doing it manually. edit 3: Well it work, so it make updating the image much easier and faster. I read on the automation in github and my head hurt so I haven't got anywhere for now. I'm thinking I could do a fetch at the beginning of the image but this would take a long time at each boot. To be continued
-
Oh I don't contradict your information, I did found out the broadcom information about the LSI SAS 2008 which says it's PCIe Gen 2 (https://docs.broadcom.com/doc/12352283) So it's the plugin that is in the wrong then, cause it shows as 2.5gbps But the NVidia is downgraded to PCI gen 1 though LnkSta: Speed 2.5GT/s (downgraded), Width x16
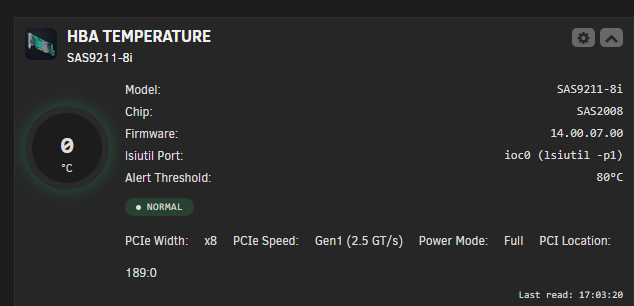
-
I'm unsure if it's really an error, the whole page on amazon speak of gen 3, even the title say gen 3. It's been far too long for me to return. But shouldn't it show gen 2 and not gen 1?
-
So I got sold something that isn't what spec on the seller page if I understand correctly, cause they say it's a PCIe Gen 3 x8. But if it's gen 2, why does it connect at gen1 speed?
-
NVidia Quadro and SAS HBA
-
Here it is lspci.txt
-
The problem is the template, when you load it, doesn't load the default host path properly. It only put /mnt/user/appdata/redis instead of /mnt/user/appdata/redis/conf/. I don't see how changing the container path would fix that. Is there something behind the scene that prevent a container path /config to have a specific path name? I never saw that kind of problem on any other template, normally, path are working fine
-
Hello everyone, I'm looking at various plugin and information about my server. It is a Dell Precision 5820 with a Xeon W-2275. According to specs, it has all PCIE Gen 3 slots. But looking at lspci output and various other plugin like hbaviewer and GPUStats, they are reporting connected as Gen1 speed but Gen 3 available. Does anyone know how to enable it to be on Gen 3? Both card connected are Gen3. Thank you
-
That's why I made it a different container. Some might want to go to the Linux container instead of wine compatibility layer. I just really don't like how they did it. I never saw a game company release a docker and not use the distribution mechanic. I open a ticket with them asking to push the Linux server on steam like they did with Windows.
-
But why does it truncate the path in my XML? I never had that problem. I tried recreating the template and it still did that.


