




Aquenon
Members
-
Joined
-
Last visited
-
I get this error intermittently from every container that uses NZBGet. "Unable to communicate with NZBGet. Http request timed out." I get one of those per minute, until it resolves itself with "The following is now resolved: Unable to communicate with NZBGet. Http request timed out." All the containers are running on the same Docker network. Every time I look at each container's config for NZBGet it is correct and when I test it, it always passes. Since they are all running on the same Docker network, each config uses the containers name to resolve the IP. This issue doesn't happen all the time. It may go weeks or months and not do it. But when it happens, it's constantly losing connection and then reconnecting, rinse and repeat. The only reason I posted in here is NZBGet is the only container that this issue has in common. Anyone else have anything like this happen? Thanks!
-
Ok, so this is expected behavior then. I can accept that as this is a one-time event as I convert. Any idea why I can't stop the array after the transfers/Unbalanced is finished?
-
Hi, I have been replacing some hard drives. With parity checks and when rebuilding the replacement hard drives, the speeds were in line with what I’m used to at around 130-175 MB/s But after the replacement HDDs were in, I have been converting to ZFS so have been using Unbalanced to empty drives so I can convert each empty drive to ZFS without losing any data. The problem is when I move data from one drive to the other, whether directly or using Unbalanced, the transfer rates are very slow at around 20-25 MB/s. Is this normal? Why such the discrepancy between file transfers vs data rebuilds/parity checks? I’m assuming I have something configured wrong, but I can’t figure out what it might be. Also, after some of these long multi-day file transfers and after some data rebuilds, I can no longer stop the array. The only thing it will let me do is restart the server with the Unraid WebUI, but when it comes back up, it complains about unclean shutdown and has to do a parity check. Parity has never found a problem when this happens, but I would like to know why I cannot stop the array in these situations. Thanks! server-diagnostics-20250115-0121.zip
-
Thank you! This is the second version of this reply, because I’d already shut down Docker and VM, which shouldn’t have made a difference anyway as they are entirely on my NVMe drive pool. I had deleted half my plugins already. I couldn’t figure out what else it could be. But your reply reminded me that I hadn’t deleted the rest of my plugins. At first thought, I wanted to use glances, but that would’ve meant re-enabling docker. I knew I could get some info from the top plug-in, and when I ran it, I saw the issue. I had multiple ssh processes running. Turns out it was the Dynamix File Integrity plug in. Deleted that plug-in, and suddenly I’m back to under a day to complete. So I came back here, erased what I had written, and started over. All that seems to be running now is unraidd0 mostly, but also a little bit from shfs, mdrecoveryd, and kworker/1:1H-kblockd. There’s a few other processes that show up briefly, but those are the only ones consistently active at ~1 to ~2% except for unraidd0 which is running around 10%. I like to think I would have caught that eventually, but it’s been months so maybe not as I had thought I had already turned everything off. So thank you so much for the kick!
-
I attached the diagnostics to the original post. I’m also getting these notices in mail as it rebuilds parity: Event: Unraid Status Subject: Notice [SERVER] - array health report [FAIL] Description: Array has 10 disks (including parity & pools) Importance: alert Parity - WDC_WD80EFBX-68AZZN0_VGGSV5BG (sdf) - active 91 F [DISK INVALID] Parity 2 - WDC_WD80EFBX-68AZZN0_VGGX0XXK (sdi) - active 90 F [DISK INVALID] Disk 1 - WDC_WD40EFRX-68N32N0_WD-WCC7K3HRJUPK (sdc) - active 84 F [OK] Disk 2 - WDC_WD40EFRX-68N32N0_WD-WCC7K1EJS37C (sdj) - active 86 F [OK] Disk 3 - WDC_WD40EFZX-68AWUN0_WD-WXA2DA164VE6 (sde) - active 81 F [OK] Disk 4 - WDC_WD40EZAZ-00SF3B0_WD-WX32DC08ETF5 (sdb) - active 82 F [OK] Cache - WDC_WDS500G1R0A-68A4W0_21436W801671 (sdg) - active 88 F [OK] Cache 2 - WDC_WDS500G1R0A-68A4W0_214513800434 (sdh) - active 91 F [OK] Nvme - Samsung_SSD_970_EVO_250GB_S465NX0KA08969Z (nvme0n1) - active 88 F [OK] Nvme 2 - Samsung_SSD_970_EVO_250GB_S465NB0K921298F (nvme1n1) - active 84 F [OK] Parity-Sync in progress. Total size: 8 TB Elapsed time: 6 hours, 43 minutes Current position: 415 GB (5.2 %) Estimated speed: 1.3 MB/sec Estimated finish: 65 days, 22 hours, 59 minutes Sync errors corrected: 0
-
Thanks, I knew I was forgetting something. Those 8TB have been in there for a year or so and were running fine. By the time I thought I needed to start thinking about adding more in, this parity issue was happening.
-
I've not had a successful parity check in 3 months, and it's been abysmally slow for 6 months.. The speed is 1 MB/sec or less at points, and its estimated time bounces between 60-110+ days, when it used to normally take about 17 hours, give or take. The speed is equivalent to the write speed on the parity drives, as it is rebuilding. I ran the disk speed docker and it was giving me errors on a 1TB seagate drive I had in there, but had nothing on it. So I moved those folders to another drive, and removed it from the array thinking that might be the issue. But parity is rebuilding at the same rate as it was checking before. Strangely, the read speed of all my drives is way up there from 30+ MB/sec to hundreds of MB/sec. The network dashboard is also showing tons of traffic exiting the network interface, yet my network controller says there is barely any traffic coming and going to it at all, measured in a few bps either up or down. Docker and VM's are disabled as well, not that that matters, as both Docker and VM's are on the Nvme drives and not on the array at all. Temps on all drives are between 79 - 91 degrees F depending on the drive. Running Unraid 6.12.13 It has an i9-13900F processor, with 64GB RAM, Motherboard ASUSTek Prime H770-Plus D4 2 8TB parity drives 4 4TB data drives (was going to add in more until this parity problem started, so that's why there are no 8TB data drives at the moment) Anyone have any ideas of why parity has slowed down so much. The last time it ran with normal speed was back in March. Thanks, Scott server-diagnostics-20241008-1818.zip
-
After rebuilding my server, my CloudBerry Backup is telling me “First argument must be a string, Buffer, ArrayBuffer, Array, or array-like object.” when I try to launch the WebUI. Is this because it’s a new machine other than the hard drives?
-
Hi, This is an afterthought, but I do have 2 5.25” empty drive bays that I’d like to do something with. Ideally fan control/temp sensor that interfaces with the motherboard if possible. Now I don’t have much room especially in the top bay because of the tubes for the radiator. Picture of room (or lack thereof) in my 2 5¼” drive bays Looking for possibilities, but it’s not something I’m dead set on doing. Just something I’d like to install if it’s possible. This is a Fractal Design R5 Define case. The radiator is so close because it’s a 140mm x 420mm radiator… I might went overkill… but it is cooling a 13900F CPU. If anyone has any ideas, I’d appreciate it. Thanks!
-
Thanks Hoopster. Not sure why I couldn’t find that. I unchecked this option and I haven’t seen this error again since so I’ll mark your post as a solution. Though I had this exact same setup on the old hardware, and it never caused problems on the network.
-
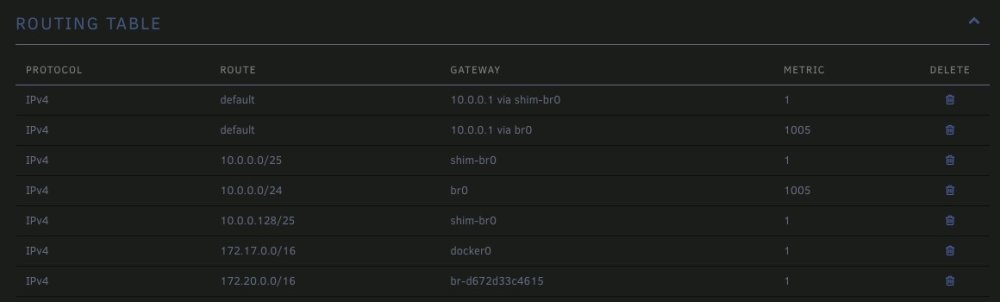
Thanks. I should have thought about that to begin with. That took care of the old bonded interface, but not the network outages. Before I start docker, there are only 2 entries in the routing table: default 10.0.0.10 via br0 10.0.0.10/24 br0 When docker starts, I get the routing table attached. Using the 'docker network ls' and 'docker network inspect', the entries for 172.17.0.0/16 and 172.20.0.0/16 appear. I don't know where the shim-br0 entries are coming from. They're obviously related to docker, but don't show up with the 'docker network' commands, and my theory is these are the problems. Unable to delete them. Only way to get rid of them is to disable Docker again.
-
Hi, I've been troubleshooting this for a week and have finally found what's causing it, I just don't know how to fix it. I recently had my unRaid server die. Probable motherboard issue. So I bought new motherboard and new CPU (old CPU was 6600K). New CPU is 13900F. Some issues persist, as I wasn't planning on upgrading and so never got to undo some things before upgrading. One thing was the old system had two NICs and I had them bonded in a failover. The new system seems to be operating fine, but upon boot up, it seems to hang for a bit and then mentions network bond failed. I don't know if this is causing the problems or not, but thought I'd mention it. There's nothing to change in the network settings, but there is some config left over from the first machine. The problem comes in when I start up Docker. As long as Docker isn't running, everything on the network is fine. When I start it up however, I have two MAC addresses getting the same IP. The MAC address of the NIC has been entered into my DHCP server so unRaid always gets the same IP. But there is another MAC address getting the same IP. What ends up happening is something in docker fights my DHCP server, and then suddenly my entire network goes down. Every device gets a self-assigned IP (169.254.x.x) for a few minutes until the DHCP server gets control again, then the IP addresses get assigned like their supposed to, and I get my network back. Then it happens again a few minutes later. The only way I have found to stop it is to shut Docker down on my unRaid server. I don't know if that second MAC address getting the same IP is what is causing this, but I have tried to block that other MAC on the network. When I do, unRaid/Docker just changes the MAC and the same behavior starts again. I finally found what that MAC address belongs to today. shim-eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 10.0.0.10 netmask 255.255.255.255 broadcast 0.0.0.0 inet6 fe80::582b:1cff:feb4:5806 prefixlen 64 scopeid 0x20<link> ether 5a:2b:1c:b4:58:06 txqueuelen 1000 (Ethernet) RX packets 21069 bytes 4794289 (4.5 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 188380 bytes 20486189 (19.5 MiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 This interface doesn't exist unless Docker is running. And this is what shows up in my DHCP logs when the issue happens: Date Facility Severity Process PID Line 2023-05-12T10:57:49-04:00 23 Error dhcpd 67826 dhcp.c:4164: Failed to send 300 byte long packet over igc1 interface. 2023-05-12T10:57:49-04:00 23 Error dhcpd 67826 send_packet: No buffer space available 2023-05-12T10:57:46-04:00 23 Error dhcpd 67826 dhcp.c:4164: Failed to send 300 byte long packet over igc1 interface. 2023-05-12T10:57:46-04:00 23 Error dhcpd 67826 send_packet: No buffer space available 2023-05-12T10:57:46-04:00 23 Error dhcpd 67826 dhcp.c:4164: Failed to send 300 byte long packet over igc1 interface. 2023-05-12T10:57:46-04:00 23 Error dhcpd 67826 send_packet: No buffer space available 2023-05-12T10:57:44-04:00 23 Error dhcpd 67826 dhcp.c:4164: Failed to send 300 byte long packet over igc1 interface. 2023-05-12T10:57:44-04:00 23 Error dhcpd 67826 send_packet: No buffer space available 2023-05-12T10:57:38-04:00 23 Error dhcpd 67826 dhcp.c:4164: Failed to send 300 byte long packet over igc1 interface. 2023-05-12T10:57:38-04:00 23 Error dhcpd 67826 send_packet: No buffer space available 2023-05-12T10:57:24-04:00 23 Error dhcpd 67826 dhcp.c:4164: Failed to send 300 byte long packet over igc1 interface. 2023-05-12T10:57:24-04:00 23 Error dhcpd 67826 send_packet: No buffer space available 2023-05-12T10:57:24-04:00 23 Error dhcpd 67826 dhcp.c:4164: Failed to send 300 byte long packet over igc1 interface. 2023-05-12T10:57:24-04:00 23 Error dhcpd 67826 send_packet: No buffer space available 2023-05-12T10:57:22-04:00 23 Error dhcpd 67826 dhcp.c:4164: Failed to send 300 byte long packet over igc1 interface. 2023-05-12T10:57:22-04:00 23 Error dhcpd 67826 send_packet: No buffer space available 2023-05-12T10:57:21-04:00 23 Error dhcpd 67826 dhcp.c:4164: Failed to send 300 byte long packet over igc1 interface. 2023-05-12T10:57:21-04:00 23 Error dhcpd 67826 send_packet: No buffer space available Does anyone have any idea what I need to do to stop this? I've included the server diagnostics if it's needed. Thanks, Scott server-diagnostics-20230513-1627.zip
-
Hi, with Dynamix Fan Auto Control, there are no fan controllers listed in PWM controllers. I’m using the motherboard right now. What PWM controllers are compatible with this plug-in? Thanks!
-
Hi, I know this is an odd question. But I need to back these files up, and the only thing I have to send them to is an old 2008 Mac Pro who's only reason for running these days is as a Time Machine server (and possibly a Tdarr node again, but I digress). I tried rsync but wouldn't work and I think I found out why when I tried LuckyBackup. macOS comes with an ancient version of rsync, and I can't get rid of it. I installed the latest version with Homebrew and while it works on the Mac, when rsync with or without LuckyBackup tries to connect, it still connects to that old version. Duplicati is out, as no matter what I try to do, it's incredibly slow, and has been like that for every system I've tried it on, not just this scenario. Looking for options that would work in my scenario. I've though about creating a macOS VM on unRaid (if that's even possible) and then have it backup via Time Machine, or make a Linux VM on the Mac Pro for LuckyBackup to connect to. But I hate VMs, all those resources locked to it whether it needs them at that moment or not. So if I have to, I will... but I would rather find a solution that doesn't involve VMs if I can. I'm mainly looking for open-source solutions before I go searching for paid solutions, but will welcome suggestions from both categories for me scenario. PS: I did try to turn the Mac Pro into another unRaid server, but it would not boot from the unRaid drive. Honestly, that is my preferred method here, but I just can't get unRaid to boot on it. Thanks in advance!
-
Apologies if this isn’t the right place, but this is where the image Support Forums sent me. I’ve been trying to get BackupPC up and running (off and on) for probably a year. Most info I can find online is years or decades old. I research a bit, lose patience, then it sits there not running for a couple months. Trying to backup a Windows 10 machine, I downloaded Cygwin-rsyncd to it (and I’ve tried the default SMB as well). When trying to run the backup, I get “backup failed (No files dumped for share C$)” Any ideas? And I’m hoping this was the correct place. Thanks
