




Nick_J
Members
-
Joined
-
Last visited
-
Hi @alicex, Did you get this working? I'm having the same challenge. I've tried: !qB .!qB *.!qB Yet they always seem to get picked up and moved. Maybe the exclamation mark is causing issues? Cheers, Nick
-
Worked for me - thanks @pinion
-
Interesting, I might give it a try when I upgrade to 6.11 then. Probably not for another month or two. Will report back here!
-
@JorgeB - just a thought... as a general rule, do you think it's worth also adding some SMART attributes to the custom SMART attribute notifications list for NVMe SSDs in a cache pool? Maybe: 0: Critical Warning 3: Available Spare 160: Media Errors It looks like these codes are pretty universal for NVMe, at least looking at Intel, Kingston and Samsung documentation. Or does this functionality just not work with NVMe SSDs at all given there don't seem to be built in threshold values in the smartctl output array like there is for SATA/SAS disks? There is a separate threshold attribute for Available Spare (4: Available Spare Threshold) but not the others, and without Unraid being aware of the relationship I'm not sure how it would know to use it anyway, and whether above or below is cause for concern.
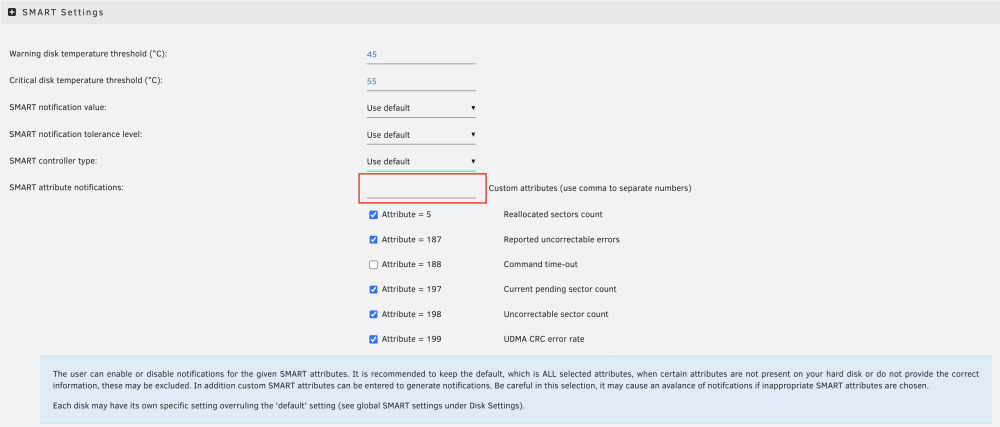
-
Oh really? I thought these were pretty solid devices. If my experience is any indication of wider experiences, I guess not! I shouldn't have bought the same replacement while I wait for the RMA process on the original haha. At least the new one is from a different batch. Both the new and old ones appear to be the new Elpis chipset units, but the originals have a manufacture date of August 2021 (so must have been amongst the first units with an Elpis chipset off the production line - interestingly enough, the serial numbers are only 21 apart). The new one has a manufacture date of January 2022. So fingers crossed it was an issue with that one batch. I'll keep a real close eye now on Available Spare SMART stats and Btrfs errorrs. It's a shame Unraid isn't alerting on this out of the box, but I found your wonderful entry @JorgeB in the FAQ thread that will hopefully help with some monitoring. It's also about time I setup some proper monitoring and alerting with Prometheus or something anyway!
-
Very true, I did have the same thought - but I figured better to check with the brains trust here in case there's anything else I could be checking.
-
Hi there, I built a new Unraid server in October last year, after replacing my trusty old one that had been running for over 10 years. I installed two brand new Samsung 970 EVO Plus 1TB NVMe M.2 SSDs that I purchased new from a reputable retailer that month in a RAID-1 BTRFS cache pool. Last night, my MariaDB and InfluxDB docker containers stopped. Upon investigation, my syslog was full of errors and I discovered it was because one of my SSDs had pretty much died. I managed to get a SMART report while the drive was still accessible (but in read only mode), and I discovered that there was 0% Available Spares left, and 97 Media and Data Integrity Errors & Error Information Log Entries. Shortly after it completely stopped registering as even being present in the server. I rebooted and was able to start the array with the second cache drive as missing. I'd normally just chalk this up to luck of the draw and some defective hardware... however what is very concerning to me is the other NVMe SSD appears to be on the same trajectory with a rapid decline in Available Spare SMART attribute values, and a rapid increase in Media and Data Integrity Errors. I've ordered a replacement to the one that completely died to hopefully prevent any further loss if the other suddenly dies, and am increasing backup frequency in the meantime. I'm a little nervous throwing in the replacement, in case it too ends up catching whatever is going on here! Some key stats on the SSDs: Less than a year old - purchased new at the same time Only ~6700 hours powered on Only ~25TB written (these are covered under warranty for 600TBW) Percentage Used SMART attribute is only 1% Are installed in some pretty neat heatsinks and have never been above 50°c Does anyone know what could account for this? Is it possible TRIM is actually not running? Although my understanding is for some reason it's not required due to the discard=async parameter being used when the devices are mounted since Unraid 6.9? Is it possible something to do with BTRFS RAID-1 itself could somehow be cause bad sectors on one device to appear on another (I know as I write this that that doesn't make much sense!)? I'm running Unraid 6.10.3. Below are the SMART reports (I've deliberately removed the serial number) and some interesting charts of some selected SMART attributes over time (I record SMART attributes on all disks throughout the day using telegraf into an Influx time series DB, and visualise in Grafana). nvme0 is what has died, and nvme1 doesn't look like it's too far behind it. I can also provide diagnostics if it would help. nvme0 (the dead one): smartctl 7.3 2022-02-28 r5338 [x86_64-linux-5.15.46-Unraid] (local build) Copyright (C) 2002-22, Bruce Allen, Christian Franke, www.smartmontools.org === START OF INFORMATION SECTION === Model Number: Samsung SSD 970 EVO Plus 1TB Serial Number: Firmware Version: 3B2QEXM7 PCI Vendor/Subsystem ID: 0x144d IEEE OUI Identifier: 0x002538 Total NVM Capacity: 1,000,204,886,016 [1.00 TB] Unallocated NVM Capacity: 0 Controller ID: 6 NVMe Version: 1.3 Number of Namespaces: 1 Namespace 1 Size/Capacity: 1,000,204,886,016 [1.00 TB] Namespace 1 Utilization: 509,339,967,488 [509 GB] Namespace 1 Formatted LBA Size: 512 Namespace 1 IEEE EUI-64: 002538 5811508fb1 Local Time is: Sun Sep 25 02:41:16 2022 AEST Firmware Updates (0x16): 3 Slots, no Reset required Optional Admin Commands (0x0017): Security Format Frmw_DL Self_Test Optional NVM Commands (0x0057): Comp Wr_Unc DS_Mngmt Sav/Sel_Feat Timestmp Log Page Attributes (0x0f): S/H_per_NS Cmd_Eff_Lg Ext_Get_Lg Telmtry_Lg Maximum Data Transfer Size: 128 Pages Warning Comp. Temp. Threshold: 82 Celsius Critical Comp. Temp. Threshold: 85 Celsius Supported Power States St Op Max Active Idle RL RT WL WT Ent_Lat Ex_Lat 0 + 7.54W - - 0 0 0 0 0 0 1 + 7.54W - - 1 1 1 1 0 200 2 + 7.54W - - 2 2 2 2 0 1000 3 - 0.0500W - - 3 3 3 3 2000 1200 4 - 0.0050W - - 4 4 4 4 500 9500 Supported LBA Sizes (NSID 0x1) Id Fmt Data Metadt Rel_Perf 0 + 512 0 0 === START OF SMART DATA SECTION === SMART overall-health self-assessment test result: FAILED! - available spare has fallen below threshold - media has been placed in read only mode SMART/Health Information (NVMe Log 0x02) Critical Warning: 0x09 Temperature: 40 Celsius Available Spare: 0% Available Spare Threshold: 10% Percentage Used: 1% Data Units Read: 18,657,378 [9.55 TB] Data Units Written: 48,497,767 [24.8 TB] Host Read Commands: 73,351,176 Host Write Commands: 644,468,416 Controller Busy Time: 4,519 Power Cycles: 26 Power On Hours: 6,723 Unsafe Shutdowns: 4 Media and Data Integrity Errors: 97 Error Information Log Entries: 97 Warning Comp. Temperature Time: 0 Critical Comp. Temperature Time: 0 Temperature Sensor 1: 40 Celsius Temperature Sensor 2: 47 Celsius Error Information (NVMe Log 0x01, 16 of 64 entries) No Errors Logged nvme1 (the dying one): smartctl 7.3 2022-02-28 r5338 [x86_64-linux-5.15.46-Unraid] (local build) Copyright (C) 2002-22, Bruce Allen, Christian Franke, www.smartmontools.org === START OF INFORMATION SECTION === Model Number: Samsung SSD 970 EVO Plus 1TB Serial Number: Firmware Version: 3B2QEXM7 PCI Vendor/Subsystem ID: 0x144d IEEE OUI Identifier: 0x002538 Total NVM Capacity: 1,000,204,886,016 [1.00 TB] Unallocated NVM Capacity: 0 Controller ID: 6 NVMe Version: 1.3 Number of Namespaces: 1 Namespace 1 Size/Capacity: 1,000,204,886,016 [1.00 TB] Namespace 1 Utilization: 586,881,011,712 [586 GB] Namespace 1 Formatted LBA Size: 512 Namespace 1 IEEE EUI-64: 002538 5811508fc6 Local Time is: Sun Sep 25 02:42:27 2022 AEST Firmware Updates (0x16): 3 Slots, no Reset required Optional Admin Commands (0x0017): Security Format Frmw_DL Self_Test Optional NVM Commands (0x0057): Comp Wr_Unc DS_Mngmt Sav/Sel_Feat Timestmp Log Page Attributes (0x0f): S/H_per_NS Cmd_Eff_Lg Ext_Get_Lg Telmtry_Lg Maximum Data Transfer Size: 128 Pages Warning Comp. Temp. Threshold: 82 Celsius Critical Comp. Temp. Threshold: 85 Celsius Supported Power States St Op Max Active Idle RL RT WL WT Ent_Lat Ex_Lat 0 + 7.54W - - 0 0 0 0 0 0 1 + 7.54W - - 1 1 1 1 0 200 2 + 7.54W - - 2 2 2 2 0 1000 3 - 0.0500W - - 3 3 3 3 2000 1200 4 - 0.0050W - - 4 4 4 4 500 9500 Supported LBA Sizes (NSID 0x1) Id Fmt Data Metadt Rel_Perf 0 + 512 0 0 === START OF SMART DATA SECTION === SMART overall-health self-assessment test result: PASSED SMART/Health Information (NVMe Log 0x02) Critical Warning: 0x00 Temperature: 38 Celsius Available Spare: 52% Available Spare Threshold: 10% Percentage Used: 1% Data Units Read: 18,829,812 [9.64 TB] Data Units Written: 48,664,852 [24.9 TB] Host Read Commands: 67,161,253 Host Write Commands: 638,333,250 Controller Busy Time: 4,531 Power Cycles: 26 Power On Hours: 6,740 Unsafe Shutdowns: 4 Media and Data Integrity Errors: 33 Error Information Log Entries: 33 Warning Comp. Temperature Time: 0 Critical Comp. Temperature Time: 0 Temperature Sensor 1: 38 Celsius Temperature Sensor 2: 45 Celsius Error Information (NVMe Log 0x01, 16 of 64 entries) No Errors Logged Cheers, Nick
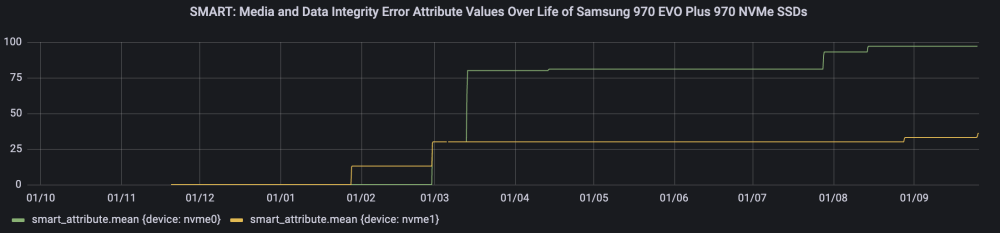
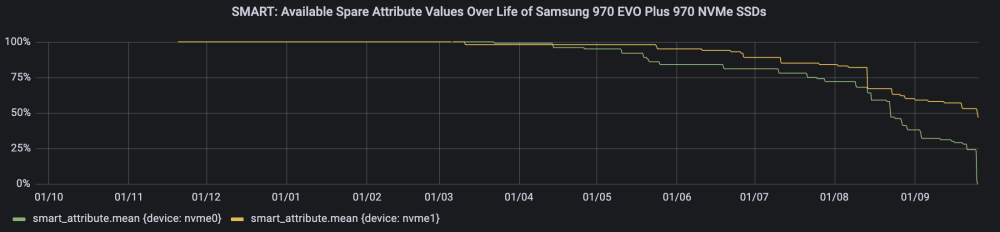
-
I had the same problem after upgrading to 4.4. All my settings disappeared, and torrents would just sit in "Stalled". The tracker addresses weren't displayed. After downgrading to 4.3.9.-2-01 everything was back to normal 🤔.
-
Ah yes, right you are! I completely missed that subtlety! Thanks @ChatNoir!
-
Thanks heaps @hoppers99! Have you tried with 6x SATA disks hooked up, as well as the 2x M2s? MSI's spec seems to read that at least one SATA port will be disabled in this configuration (SATA2 unavailable if M2_2 is populated, or both SATA5 and SATA6 unavailable if M2_3 is populated):

-
Hey there @hoppers99, How did your build go? I've been trying to spec up my next build to replace my current server that's been running for 12-13 years. Pretty certain I'll be going with an LGA1200 CPU, probably an i5 just from a power usage perspective... but I'm having a real tough time deciding on a motherboard. I'm scared I'll have problems with Unraid. How did the MSI MAG z590 Torpedo go for you? Did it work out of the box, even the onboard network interface? It looks like the 2.5gbps NIC is a I225-V, which it sounds like Unraid supports fine in 6.9: Cheers, Nick





