




Hornz
Members
-
Joined
-
Last visited
-
Das könnte natürlich sein, aber leider hatte ich keine andere Möglichkeit. Meine Connect Backups waren deaktiviert warum auch immer und sonst hatte ich keine mehr. Es war ein "neuer" Stick, also nicht nagelneu aber noch nicht in Unraid in Verwendung. Nein hab ich nicht, wusste nichtmal das ein Stick solche Möglichkeiten hat. Ich werde mir mal für die Zukunft eine Mac oder Linux alternative suchen zu deinem genannten Programm. sde ist meine zweite nvme, schickt unraid auch SSDs in den Sleep? Auffällig ist er nicht gewesen, zumindest nicht laut SMART Selftest und Scrunity Speichertest wäre eine Möglichkeit wenns wieder auftritt. ABER jetzt ist es seitdem nicht mehr aufgetreten. Der Unterscheid ist jetzt das der Stick hinten am Server steckt und nicht vorne. Da es auch mit dem neuen Stick vorgekommen ist, war es evtl. eine Kombination aus kaputten Stick und einem leicht defekten Front I/O ? Sorry für die späte Antwort, also ich behalte es mal im Auge. Mal sehen ob es in naher Zukunft wieder Auftritt. Danke dir schon mal für die Ideen.
-
Hallo Zusammen, seit einigen Tagen hab ich ein komisches Problem und hoffe jemand hat eine Idee. Der Server bleibt aus dem nichts einfach quasi hängen. Also alle Dienste die meine Docker bereitstellen wie Nextcloud melden offline. Die WebUI ist auch nicht mehr zu erreichen. Was noch teilweise geht ist die Konsolenanmeldung über PiKVM. Der Cursor blinkt und ich kann noch root eingeben aber dann bleibt springt er runter und es bleibt leer, keine Passwort Abfrage o.ä. Drücke ich dann die Powertaste fängt er mit dem runterfahren an bis er dann bei "Stopping Unraid" Api hängen bleibt. Ab da gehts nicht weiter. Maximal geht noch der Reset Button oder lange halten. Nach einem Reboot läuft dann auch wieder alles ganz normal. Ich hatte den Stick in verdacht und wollte ihn backupen zur Sicherheit da hat er sich beim kopieren am Mac selbst ausgeworfen, also hab ich stück für stück den config Ordner kopiert und ein neuen Stick gemacht und dann lief wieder alles und heute ist er auf einmal wieder genau gleich hängen geblieben. Während er in diesem Zustand ist hören sich auch die Lüfter anders an. Im Log hab ich nicht viel gefunden, hab extra zur Analyse auf einem Mac mini ein syslog server eingerichtet um zu sehen ob was interessantes kommt aber da war nichts. Die letzte Meldung aus dem Log vor dem hängen bleiben scheint die zu sein: Feb 11 12:32:19 192.168.65.1 emhttpd: spinning down /dev/sde Keine Ahnung was das für eine IP ist, schon mal keine aus meinem Netz Gibts Ideen oder Ansätze ?
-
wie würdest du die Daten am besten kopieren? sind ja gesplittet auf beide Platten, per CLI oder Gui?
-
Ich kann das Array sogar nur mit den beiden Platten starten und die Daten sind da, aber das ist keine Dauerlösung würde ich mal sagen
-
Hallo Zusammen, ich würde gern mein Array umbauen, dachte mir das geht ganz einfach indem ich nach und nach die Platten ersetze, aber das geht wohl doch nicht. Ziel ist es mein 3x3TB Array auf ein 2x12TB zu wechseln. Bisher habe ich die Parity rausgezogen und mit einer der 12er getauscht und rebuilded und das selbe mit der zweiten Array Disk mit der Hoffnung das mir unraid anbietet das Array auf die Zwei platten zu builden. Aber die Array Größe lässt sich nicht auf 2 runter setzen sondern bleibt auf 4, da 2 Paritys angegeben sind warum auch immer. Wie würdet ihr vorgehen oder wo liegt bei mir der Denkfehler. Hab jetzt meine alten Platten draußen und die neuen drinnen, notfalls kann ich wohl auch wieder zurück und von neu beginnen. Ich wäre super Dankbar für eure Hilfe
-
nein das ist tatsächlich einfach so passiert, ich hab das update gemacht und gebootet und zack war es da ich hab ganz normal drei platten über sata im array gehabt und die cache als m2 SSDs, das einzige was über usb läuft ist die backup platte in Unassigned devices
-
Hab gerade gesehen das die Shares Appdata und System verstellt waren und hab sie korrigiert und rebootet. Jetzt ist alles wieder da. Also für künftige Kollegen mit dem Problem, Neustart -> SSDs wieder neu zuweisen und Array Starten -> Shares prüfen und ggf Pfad anpassen -> Reboot
-
Gude Zusammen, eben hab ich das Update gemacht und nach dem Reboot ist das Aray einfach ohne gemountete Cache und Cachebackup gestartet. Dann hab ich nochmal rebootet, dann ist das Array nicht gestartet und ich sollte den beiden Pools wieder die SSDs zuweisen, hab ich dann auch gemacht und gestartet, Daten sind noch da, aber der Docker Service meint es sind keine Docker Container installiert. Hat Jemand eine Idee was ich machen kann? Hab nochmal die Pfade geprüft die stimmen soweit. Hab das Gefühl das die Docker.img überschrieben wurde aber da bin ich mir nicht sicher. Die Docker Daten sind in Appdata alle noch da.
-
Hey Guys, it´s not really a thing of Unraid but maybe u can help me anyways. I have to build up some Wiki Docker Containers in my company. But the xwiki docker can´t reach his ubuntu archives through apt get. Is there a parameter i can put in the compose file which ads our company repository to the container?
-
Ich wünsche dir das es so bleibt, aber es war bei mir auch knapp über einem Jahr ohne Probleme, aber wir kennen ja den Murphy, der kommt immer unverhofft. Ich glaube auch eher dass das BTRFS zusammenbricht als das eine der Platten kaputt geht ehrlich gesagt, zumindest nach dieser Erfahrung jetzt 😅
-
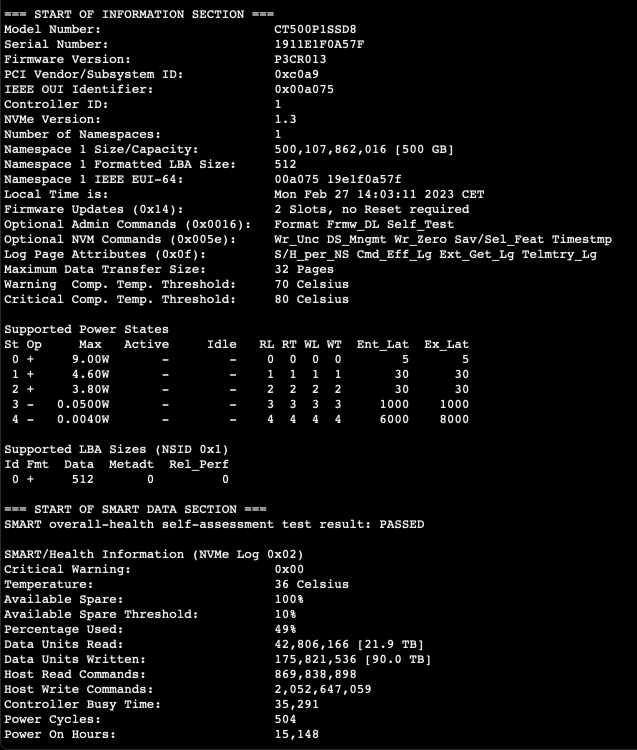
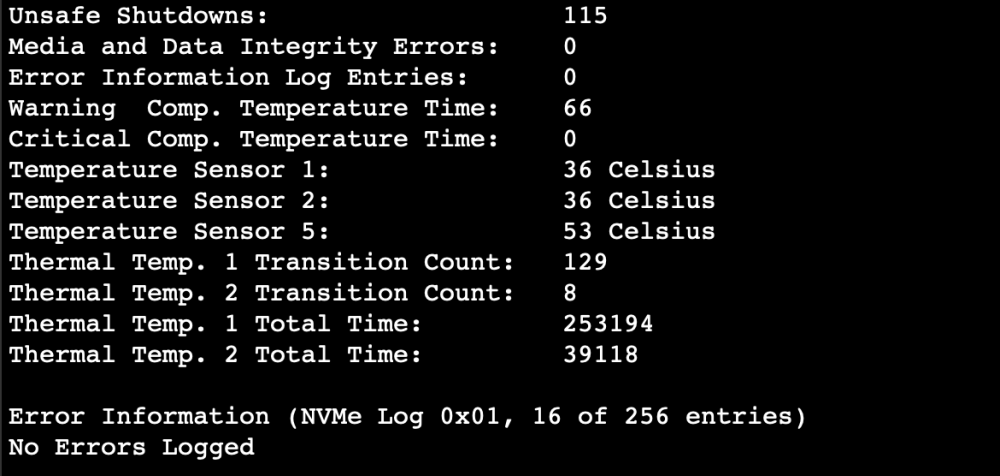
Also es wurde dann alles doch noch komplizierter als gedacht. Neue Crucial SSD ist angekommen und hab sie direkt auf m2 Slot 1 eingebaut und die alte nvme auf slot 2 eingebaut um 2x500gb zu haben -> server bleibt beim Asrock Bootlogo hängen SSDs in den Slots getauscht -> selbes Problem. Neue SSD raus alte WD SSD wieder rein -> Server bootet aber erkennt die nvme in Slot 2 nicht SSDs in slots getauscht -> sieh an alles war wie vorher und lief, erst da ist mir der Gedankenblitz gekommen, das der zweite m2 slot ja nur m2 SSDs mit SATA Protokoll nimmt. Dann nochmal zum testen die neue SSD einzeln in dem richtigen Slot eingebaut -> selbes Boot Problem Also eine m2 SATA SSD bestellt mit 500GB und nun hab ich die alte crucial nvme m2 mit 500gb als cache und eine m2 SATA SSD als cache backup laufen, brauche nur noch eine Möglichkeit um das Cache quasi 1zu1 drauf zu kopieren Übrigens hab ich dann die neue Crucial SSD in mein gaming Rechner eingebaut, dort lief sie ohne Probleme und hat da jetzt einfach eine alte Intel m2 mit 128GB ersetzt Außerdem kann ich bei der alten Crucial SSD immer noch keine Smartwerte ordentlich auslesen, obwohl sie jetzt als XFS und alleinstehend läuft. Bei der neuen SATA m2 von Intenso gehts ohne Probleme. Also was lernen wir daraus, Crucial SSDs sind bei Unraid nicht optimal und man sollte sich immer vor dem Kauf Gedanken machen welche m2 Slots man auf dem MB hat 😅 Im Anhang ist das was mir für die Crucial ausgespuckt wird auf der CLI. Nachdem der short Test per CLI nach nicht mal einer Sekunde fertig sein soll.
-
Ich würde mich morgen dann mal dran machen und alles auf die neue 500GB nvme zu schieben und dann die alte 500er quasi als schnelles Backup nutzen, ich hab an sich ja sowieso schon tägliche backups auf eine lokale Platte die per USB angeschlossen ist und ein Wöchentliches das auf ein andere Unraid geht, welches hundert Kilometer weit weg bei meinen Eltern läuft. Die Frage wäre jetzt wie mach ich das am einfachsten ohne das ich alles neu konfigurieren muss. Kann ich eine Platte aus dem BTRFS rausziehen, die neue einstecken als xfs Pool und dort alles drauf ziehen und laufen lassen? Bzw ich muss dem Unraid dann bestimmt klar machen das er nun das Appdata etc auf dem hfs nutzen soll und nicht das im btrfs Würde mich freuen wenn du/ihr mir bei dem Umzug etwas beisteht Gut nacht erstmal
-
kannst du es dir denn erklären warum ich den selftest auf der NVME nicht machen kann? Bzw wenn ich in der GUI auf egal welchen test drücke, ist der kurz grau dann wieder orange ohne mir ein Ergebnis zu liefern. Außerdem steht auch dort "No self-tests logged on this disk"
-
Ich denke mal du meinst das Scrub repair ? Lasse es gerade mal durchlaufen und bei 15% hat er schon 1087 corrected.
-
Hornz changed their profile photo
-
Moin Moin, ich hoffe mir kann Jemand erklären was da genau los ist. Ich habe gestern beim üblichen Anlagencheck gemerkt, dass sich meine Docker nicht mehr Neustarten lassen bzw. nur nach reboot und auch nicht alle. Ich bekam öfters den Fehler 403. Mein Cache besteht aus einer 240gb WD Green m2 Sata und einer 500gb Crucial CT500P1 m2 Nvme. Die laufen im Btrfs Raid1 Mode. (Komische Konfiguration ich weiß aber damals war das Geld knapp und da hab ich genommen was da war). Meine bisherigen Schritte waren zum einen Smart Tests im Maintenance Mode, dort lässt sich aber nur die WD testen genauso wie mit smartctl, bei der nvme ist der Test in der gui quasi nie passiert und in der CLI in einer Sekunde fertig selbst der long test. Dort angeblich alles passed, aber dem Test schenke ich kein Glauben. Dann hab ich noch Check Filesystem Status im BTRFS gemacht, dort angeblich auch alles i.O. genauso wie im Scrub Status. Gestern hab ich noch mit dem Docker.img rumgespielt, weil ich erst nichts von den Meldungen in den Logs wusste und vermutete das mir das image wieder voll gelaufen ist. Heute hab ich das Image gelöscht und die Docker neu runtergeladen und bisher läuft alles wieder wie gewohnt. Die Logs von vorgestern wo der Fehler das erste mal auftrat: Die Logs von eben, nach löschen des Docker images und erneuten Download der Docker und testweise eine Iso Datei auf den cache geschoben. Was meint ihr, ist eine der Platten hin oder liegt es an was anderem ? Vorsichtshalber hab ich noch eine neue 500gb Crucial bestellt und würde die dann entweder durch die womöglich kaputte tauschen oder wenn alles i.O. ist dann das BTRFS mit den zwei 500gb nvme´s laufen lassen.








