




frank80
Members
-
Joined
-
Last visited
Everything posted by frank80
-
Das versuche ich morgen einmal. Es hat keinen Unterschied gemacht. Es ist als wäre die „defekte“ HDD im Array. Wie du weiter oben im Post auch schreibst, habe ich wieder ein defektes Dateisystem.
-
Hallo mgutt, ich habe die „defekte“ HDD durch eine neue identische HDD ersetzt. Hier bin ich nach der Anleitung aus dem Link von cz13 inkl. Punkt 7 vorgegangen. Ich vermute, dass genau das passiert ist. Die ausgebaute HDD habe ich einmal testweise per USB an meine Synology DS gestöpselt. Hier kann ich auf alle Daten zugreifen und auch die vdiks löschen, die in unraid auf Read-Only standen. Gruß Frank
-
Hallo zusammen, so, hier ein ernüchterndes Update... 🙈 Das Rebuild ist fertig und ich habe unraid neu gestartet, nach ca. 10 Min. hatte ich die ersten Benachrichtigungen. Die Fehler kamen in Dauerschleife bei Zugriff auf die Daten.. Feb 7 19:02:38 unraid kernel: BTRFS critical (device md1: state EA): unable to find logical 9455870400099729408 length 4096 Feb 7 19:02:38 unraid kernel: BTRFS critical (device md1: state EA): unable to find logical 9455870400099729408 length 16384 Feb 7 19:02:38 unraid kernel: BTRFS critical (device md1: state EA): unable to find logical 9455870400099729408 length 4096 Feb 7 19:02:38 unraid kernel: BTRFS critical (device md1: state EA): unable to find logical 9455870400099729408 length 16384 Feb 7 19:02:38 unraid kernel: BTRFS critical (device md1: state EA): unable to find logical 9455870400099729408 length 4096 Feb 7 19:02:38 unraid kernel: BTRFS critical (device md1: state EA): unable to find logical 9455870400099729408 length 16384 Fix Common Problems Feb 7 19:08:06 unraid root: Fix Common Problems: Error: Unable to write to disk1 Was kann ich jetzt noch machen? Gruß Frank

-
Hallo cz13, danke für den Link!! Das Rebuild läuft und ich habe mich für das "Normal replacement" mit der Option 7 entschieden. Gruß und danke Frank
-
Hallo zusammen, ein kurzes Update. Leider geht aktuell nicht mehr viel. Ich habe noch einmal eine Rsync-Sicherung gestartet, nach ca. 5 Std. war unraid nicht mehr erreichbar und ich musste den Rechner hart neu starten. Als unraid wieder hochgefahren war, hat der Parity Check begonnen, was ebenfalls dazu geführt hat, dass unraid nach ein paar Stunden nicht mehr erreichbar war und ich wieder hart neu starten musste. Was mir ebenfalls aufgefallen ist, es waren nicht nur die 2 vdisks, sondern mehrere Dateien die Read-Only sind. So, heute ist meine neue HDD gekommen (brauchte sowieso eine), wie würdet ihr jetzt am besten vorgehen? Array stop > HDD Defekt raus > Array start > Array stop > HDD neu rein > Array start ? Gruß Frank
-
ich habe nur diesen Eintrag Jan 30 21:25:10 unraid ool www[5434]: /usr/local/emhttp/plugins/dynamix/scripts/btrfs_scrub 'start' '/mnt/disk1' ''
-
Hallo mgutt, Das befürchte ich auch 😩 Hier das Log Ein Backup habe ich gemacht. Der scrub aus der GUI bringt keine Fehler, aber irgendwie glaube ich nicht das er funktioniert, weil er nach dem klick eigentlich auch schon wieder fertig ist. UUID: 0c6db0b0-7bd0-48bd-890b-a9aab341325f Scrub started: Mon Jan 30 20:22:01 2023 Status: aborted Duration: 0:00:00 Total to scrub: 8.06TiB Rate: 0.00B/s Error summary: no errors found Ja, mir ist auch aufgefallen, dass unraid sich meistens beim Backup auf meine Unraid-Backupserver mit deinem Rsync-Script oder beim Backup auf den PBS verabschiedet.
-
Hallo mgutt, Voll auf keinen Fall, ich habe noch über 6 TB frei. root@unraid:~# df -h Filesystem Size Used Avail Use% Mounted on rootfs 16G 1.1G 15G 7% / tmpfs 32M 848K 32M 3% /run /dev/sda1 29G 3.7G 25G 13% /boot overlay 16G 1.1G 15G 7% /lib/firmware overlay 16G 1.1G 15G 7% /lib/modules devtmpfs 8.0M 0 8.0M 0% /dev tmpfs 16G 0 16G 0% /dev/shm cgroup_root 8.0M 0 8.0M 0% /sys/fs/cgroup tmpfs 128M 684K 128M 1% /var/log tmpfs 1.0M 0 1.0M 0% /mnt/disks tmpfs 1.0M 0 1.0M 0% /mnt/remotes tmpfs 1.0M 0 1.0M 0% /mnt/rootshare /dev/md1 15T 8.1T 6.5T 56% /mnt/disk1 /dev/nvme0n1p1 932G 67G 865G 8% /mnt/cache /dev/sdb1 472G 86G 380G 19% /mnt/vm shfs 15T 8.1T 6.5T 56% /mnt/user0 shfs 15T 8.1T 6.5T 56% /mnt/user /dev/sdg1 932G 158G 774G 17% /mnt/disks/PBS-Backup /dev/loop2 30G 17G 13G 57% /var/lib/docker /dev/loop3 1.0G 5.0M 904M 1% /etc/libvirt tmpfs 3.2G 0 3.2G 0% /run/user/0 root@unraid:~# Löschen würde ich gerne, die vdisk´s sind halt Read-only. root@unraid:/mnt/user/06_Backup# rm -r 11_ProxmoxBackupServer rm: cannot remove '11_ProxmoxBackupServer/Debian/vdisk2.img': Read-only file system rm: cannot remove '11_ProxmoxBackupServer/PBS/vdisk2.img': Read-only file system root@unraid:/mnt/user/06_Backup# Ich habe eine VM mit Proxmox Backup Server für meine Proxmox VE Server. Da meine PVE`s auch je 1 TB haben und ich noch genug TB´s habe, warum nicht? Gruß Frank

-
Hallo liebes Forum, ich brauche mal eure Hilfe. Fix Common Problems hatte mir gestern eine rote Fehlermeldung angezeigt. Unable to write to disk1 Ich glaube, es handelt sich um 2 vdisk Dateien. root@unraid:/mnt/user/06_Backup/11_ProxmoxBackupServer/Debian# ls -lh total 4.0K -rwxrwxrwx 1 nobody users 1.0T Feb 27 2022 vdisk2.img* ----------- root@unraid:/mnt/user/06_Backup/11_ProxmoxBackupServer/PBS# ls -lh total 337G -rwxrwxrwx 1 root users 1.0T Jan 26 01:50 vdisk2.img* Die VM´s habe ich gesichert und die vdisks könnte man löschen. Kann mir jemand sagen, wie ich das Problem lösen kann? Gruß Frank
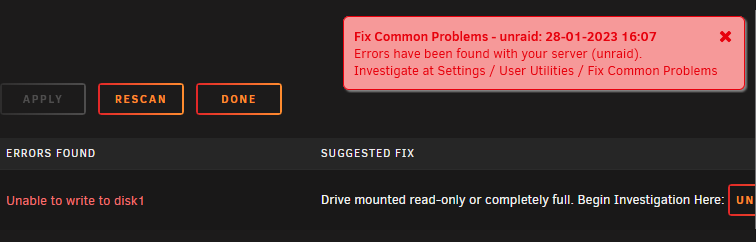

-
Wenn der USB-Stick eine Macke hätte, müsste ich dann nicht auch andere Probleme haben. Das System läuft ca. 1 Jahr und als Stick habe ich einen SanDisk Cruzer Fit USB-2.0 mit 32Gbit. Kann man den Stick prüfen?
-
Die HDD ist über einen Wechselrahmen im Servergehäuse angeschlossen, also schon über SATA.
-
Hallo mgutt, das Passwort habe ich in UD hinterlegt. Mein Array ist nicht verschlüsselt. Scheinbar nicht. Ich habe schon mehrere Stunden damit verbracht, eine Lösung zu finden und mich danach durchgehangelt. Das YT-Video ist von 2019, ich glaube, da konnte man noch nicht über UD verschlüsseln. (mein Englisch ist nicht sonderlich gut) Erst hatte ich einen Passwortgenerator benutzt, nach der zweiten Formatierung hat das Passwort Buchstaben, Zahlen, @ und _. Ich konnte die HDD vor dem Reboot mounten und unmounten. Dann sollten das Passwort funktionieren, denke ich. Ja, die HDD ist über unRAID formatiert und verschlüsselt. Auf die Kommandozeile bin ich erst im Video gekommen, dort hat es so funktioniert. Gruß Frank
-
Hallo zusammen, ich habe ein ähnliches Problem. Ich habe meine Backupstrategie etwas geändert, bzw. teste gerade meinen besten Weg. In meine unRaid-Server habe ich ein Wechselrahmen mit einer HDD, diese ist mit btrfs-encrypt formatiert, mit einem Passwort verschlüsselt und in Unassigned Devices-Plugin eingetragen. Wird unRAID neu gestartet, kann ich die HDD nicht mehr mounten. Erst dachte ich, dass ich ein falsches Passwort eingegeben habe. Also habe ich die HDD neu formatiert und ein neues Passwort vergeben und im Plugin eingetragen. Mount und unmount funktioniert, wieder die Daten mit dem Script von mgutt angestoßen und 2 Tage gewartet. Nach einem Reboot kann ich die HDD wieder nicht mounten. Nov 13 11:42:26 unraid unassigned.devices: Adding partition 'BackupHDD'... Nov 13 11:42:26 unraid unassigned.devices: Mounting partition 'BackupHDD' at mountpoint '/mnt/disks/BackupHDD'... Nov 13 11:42:26 unraid unassigned.devices: Using disk password to open the 'crypto_LUKS' device. Nov 13 11:42:28 unraid unassigned.devices: luksOpen result: No key available with this passphrase. Nov 13 11:42:28 unraid unassigned.devices: Partition 'X1X0A0U7FVGG' cannot be mounted. In einem YT-Video habe ich gesehen, dass man das keyfile neu erstellen kann (/root/keyfile). root@unraid:~# echo -n "Passwort" > keyfile #Ausgabe... root@unraid:~# cat keyfile Passwort@unraid:~# Leider alles ohne Erfolg. Das habe ich ebenfalls ohne Erfolg versucht... root@unraid:~# /usr/sbin/cryptsetup luksOpen /dev/sdh1 BackupHDD --allow-discards --key-file=/root/keyfile No key available with this passphrase. ## /usr/local/sbin/emcmd 'cmdCryptsetup=luksOpen /dev/sdh1 BackupHDD --allow-discards' Habt Ihr noch eine Idee? Gruß Frank
-
Hallo, ich habe die HDD jetzt noch einmal mit diesem Befehl überschrieben. (sdX natürlich angepasst) dd if=/dev/zero of=/dev/sdX bs=4096 status=progress habe ich bei mir nicht gemacht. Danke noch einmal für eure Hilfe 👍
-
Guten Morgen zusammen, wie löscht oder nullt ihr HDD´s richtig? Ich habe jetzt 3 Durchgänge mit Eraser und 1 Durchgang mit WipeDisk. EaseUS data Recovery findet immer noch Dateien.
-noVNCMozillaFirefox.png.353e31f293e09f296512af419236b829.png)
-
Hallo mgutt, danke für die Info, ich habe Syslog jetzt aktiviert. Gestern Morgen war unraid auch nicht mehr erreichbar, auch direkt am Monitor hatte ich keine Reaktion. Es half nur noch ein Reset, dann kam der Parity-Check, als dieser heute fertig war, hat er ihn noch einmal gestartet. Bei der Platte habe ich aktuell wieder keine Fehler, das ist echt verrückt. Ich hoffe, ich bekomme die Platte ohne Probleme getauscht.
-
Naja, wie man es nimmt, ich habe aktuell ziemlich viel um die Ohren, das lenkt etwas ab 😅 Ich habe jetzt ein Reset gemacht und unraid ist wieder da. Aktuell läuft der Parity-Check. Ich habe die Platte beim Händler reklamiert, ist ja bis 2026 Garantie drauf! Gruß und danke für eure Hilfe!
-
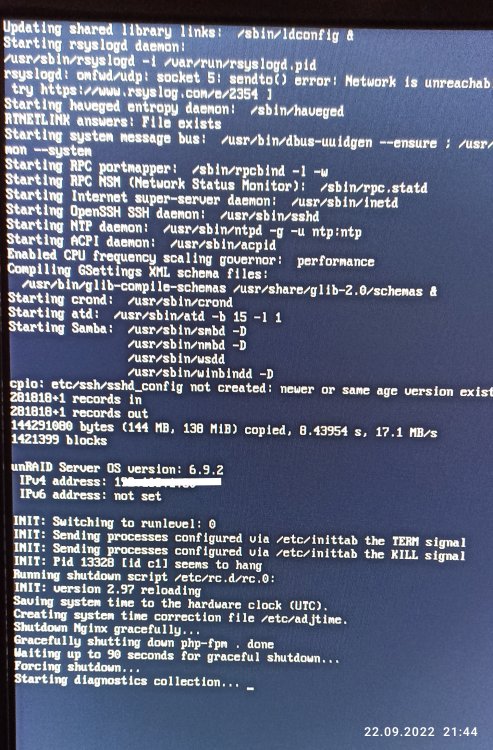
Hallo, nein. Er hängt beim booten, wie man auf dem Bild sieht. Ich glaube da hilft nur noch ein Reset?!
-
Hallo, wie lange geht so eine diagnostics collection, seit Donnerstag habe ich immer noch das gleiche Bild wie oben gepostet? Auf die Tastatur wird nicht reagiert.
-
Hallo Members, ja, das ist die gleiche Platte. Also doch Toshiba anschreiben. Unraid hat sich wenigstens am Schalter ausschalten lassen. Jetzt hängt er zwar an Starting diagnostics collection, würde aber mal abwarten was passiert.
-
Hallo zusammen, ich glaube, ich habe mich zu frühe gefreut. Jetzt habe ich diesen Fehler und unRAID ist aktuell nicht erreichbar 😩 198 Offline_Uncorrectable 0x0030 001 001 000 Old_age Offline - 418
-
Ok, danke euch für die Hilfe!!
-
Hallo, bis jetzt habe ich keine Fehler mehr erhalten. Ich habe vorgestern einen smartctl long Test gestartet. Hier werden, bis auf den Error 1 occurred at disk power-on lifetime: 5193 hours (216 days + 9 hours) keine Fehler mehr angezeigt. Was haltet ihr davon, sollte ich Toshiba mal anschreiben? Gruß Frank
-
Guten Abend zusammen und danke für eure Hilfe. 👍 Als Nächstes werde ich Folgendes versuchen; Powertop in der /boot/config/go auskommentieren reboot Write corrections to parity deaktivieren Parity-Check läuft bereits (der letzte Check wurde vor 30 Min. beendet und ergab keine Fehler etc.) Gruß Frank Nachtrag; die Fehler auf der Startseite sind jetzt auch wieder weg, siehe Bild...

-
Hallo, Eigentlich in der Zeitfolge, wie ich geschrieben bzw. geantwortet habe. Current pending sector = 418 Array Error´s (1024) Current pending sector = 0 Die beiden Ergebnisse von smartctl habe ich direkt vor dem Schreiben im Forum ausgelesen. ca. 11 Uhr 17:21 Uhr Das interessante ist der SMART Error Log ca. 11 Uhr SMART Error Log Version: 1 No Errors Logged und 17:21 SMART Error Log Version: 1 ATA Error Count: 1




-noVNCMozillaFirefox.png.353e31f293e09f296512af419236b829.png)

