SinoBreizh
Members
-
Joined
-
Last visited
-
Thanks for your answer! I do have 4 x 16TB + 1 x 16TB parity, so I'm good then. I guess I got lucky it was the parity drive this time. What solutions are open to me, to protect my privacy if I have to send in array drives for warranty next time? Encryption (XFS encyrpted?) is the only solution, correct?
-
TL;DR: my parity drive has failed. Insurance/extended warranty wants to inspect the drive before they decide it can't be fixed and deserves a replacement/refund. Drive is too far gone to be wiped. Is data written to the parity drive by Unraid something readable which a data specialist could extract? I have critical personal files on there which I'm not comfortable sharing. My parity drive has failed recently, with increasing numbers of reallocated sectors and other SMART errors. I pulled it from Unraid as soon as it became clear it wasn't a one-off issue, but a cascading failure. I chose an extended warranty on that drive, due to it being a refurbished drive. The insurance company has accepted my claim. But they want the drive to "make sure it can't be fixed", before they decide to replace it or refund it. There's already a DHL pickup scheduled for tomorrow, before I could say anything. I'm wary of giving them the drive, since I have critical personal information on there: from copies of ID and banking statements to girlfriend's nudes, with everything you could possibly imagine in between. Basically all you need for identity theft and/or extortion. I obviously can't wipe the drive before the pickup, since it's failing hard. I've turned it back on a few times in Windows on a 3.5" to USB adapter to diagnose with CrystalDiskInfo and HDD Sentinel. But now it's not recognised in Windows anymore. Is the data written to the parity drive something which could be readable to a data recovery specialist? Which is who I assume the drive is going to once DHL picks it up for the insurance company. As the TL;DR said, there's tons of stuff on my array which is none of their business. I'd appreciate any information or help you may have on this. Thanks!
-
I'm honestly not so sure. Limetech themselves seem to care about it enough to have a blog about it on their homepage. And their latest article is about choosing the right hardware to keep power costs down. I'd wager a non-negligible amount of people who are tech savvy enough to pick up Unraid, are probably also going down the C-state rabbit hole. Since unlike the TrueNAS community, I don't think most of us here are running homelabs where power efficiency is sacrificed on the altar of a hobby. 😂 Unraid also strikes me as an OS designed around power efficiency, since the whole value add compared to TrueNAS is you don't have to spin up all the disks to read from any single drive. No problem. To refocus on the original question though: Is it possible to install a driver without a plugin on Unraid? Is the dedicated Realtek Linux driver I mentioned earlier (copied the README) something which could be packaged into this plugin, or installed manually? I've attached it here for everyone's convenience. r8127-11.015.00.tar.bz2 For context also, it's the highlighted file on Realtek's website.
-
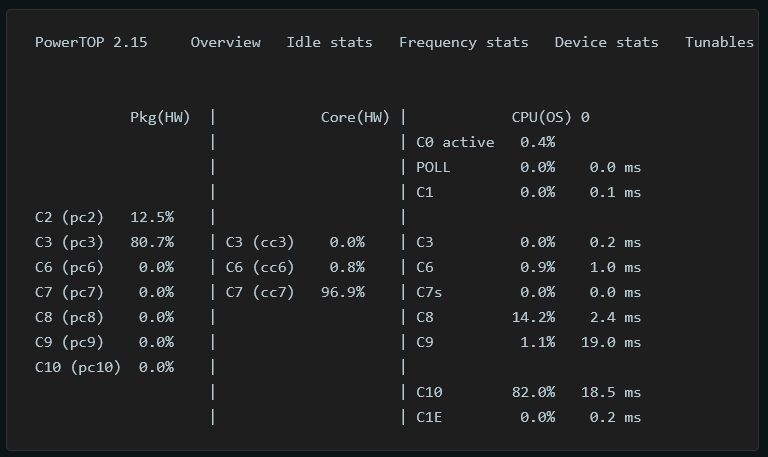
Unfortunately, as I mentioned in a previous comment, the kernel driver is apparently bad and disables power saving. A system running an RTL8126 (5Gbe) or 8127 (10Gbe) will be unable to go below C3: I've read here and there that the dedicated driver from Realtek fixes this, which is why I've been inquiring about packaging the Realtek driver instead.
-
Would you mind answering a few questions, since you're daily driving this setup? How do you backup and restore before taking the plunge to a custom kernel? I've never done this outside atomic distros. Do you just use Unraid Connect's flash backup function? What happens to this custom kernel through restarts/updates? It gets replaced by the default kernel every update, correct? Is ASPM correctly enabled? (Can be checked with ASPM Helper plugin or lspci -vvv ) Even if ASPM is enabled, kernel Realtek drivers are known to limit CPU C-states. Would you mind confirming with Powertop that your setup can go below C3 at idle? (If your other components allow it of course) Thanks in advance!
-
Good idea for file integrity, I didn't think about that! I'm hoping this works, because my TEG-10GECSFP is the only 10Gbe SFP+ NIC (that isn't a 130€ Intel X710) which "supports" ASPM where I live. If I can't get it to work stable, I guess I'll just switch back to RJ45. I'm firmly in the camp of scrolling down in the log, rather than potentially missing something important ha ha Thanks for your help!
-
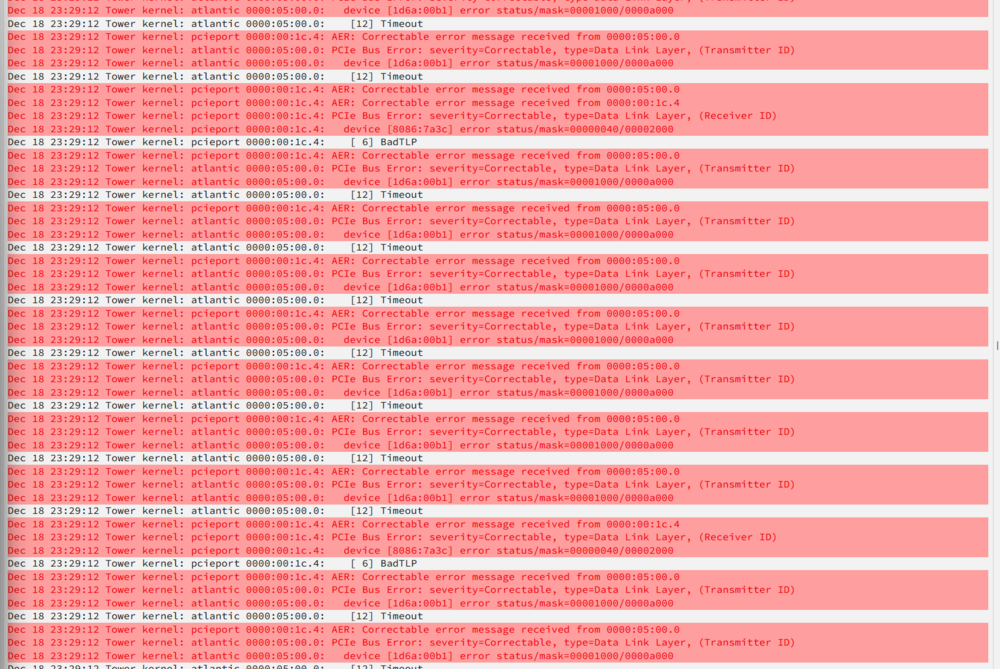
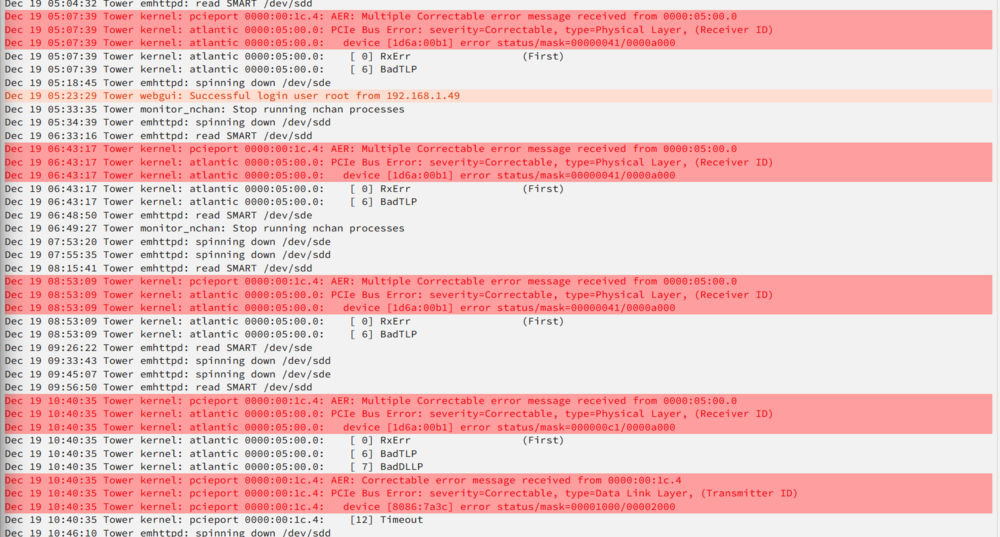
Thanks alturismo for your pointers. L0s L1 turned out to be unstable (judging by the logs). I suspect this is because the PCIe root, according to ASPM Helper and my BIOS settings, only supports L1. So not only does L1 lower power consumption by around 8W compared to L0s L1, it is also more stable. I do have another question: L1 has been stable so far in the sense that all my apps work, and (as far as I can see) I never lose connection. But in the logs I now see the same errors I saw with L0s L1, just much less frequent. Is it safe to leave L1 enabled in ASPM Helper, or is it a sign I should live with no ASPM on that device, or replace it with a NIC that natively supports ASPM? For context, I get this error every hour or two, instead of hundreds of times per second with L0s L1. Here is a text copy for your convenience. The root and device addresses match the device I force enabled L1 to. 05:00.0 is my TEG-10GECSFP 10Gbe SFP+ NIC. 00:1c.4 is the PCIe root it is connected to. NIC error: Dec 19 10:40:35 Tower kernel: pcieport 0000:00:1c.4: AER: Multiple Correctable error message received from 0000:05:00.0 Dec 19 10:40:35 Tower kernel: atlantic 0000:05:00.0: PCIe Bus Error: severity=Correctable, type=Physical Layer, (Receiver ID) Dec 19 10:40:35 Tower kernel: atlantic 0000:05:00.0: device [1d6a:00b1] error status/mask=000000c1/0000a000 Root error (which the NIC is connected to): Dec 19 10:40:35 Tower kernel: pcieport 0000:00:1c.4: AER: Correctable error message received from 0000:00:1c.4 Dec 19 10:40:35 Tower kernel: pcieport 0000:00:1c.4: PCIe Bus Error: severity=Correctable, type=Data Link Layer, (Transmitter ID) Dec 19 10:40:35 Tower kernel: pcieport 0000:00:1c.4: device [8086:7a3c] error status/mask=00001000/00002000Thanks again for your time.
-
Hello! If a device supports L0sL1 (which I have to manually force through ASPM Helper), is it better to: Force L1? In my testing this allows my system to reach 80% C6. Force L0sL1? In my testing this allows the system to reach 60% C3, 25% C6. L1 is clearly superior at complete idle. But when the server is experiencing light load (seeding torrents, Plex every once in a while, etc), I can't help but think forcing L1 will prevent standby that could have been achieved with L0s. L1 feels like "all or nothing", while L0sL1 feels like it keeps the door open for standby during lighter loads which wouldn't reach L1. Or maybe, if it can't reach L1 due to activity, it can't reach L0s either? I can't really simulate seeding/daily use in a repeated manner, hence why I ask here. Any thoughts? Thanks!
-
I've been checking the README of the RTL8127 driver package from Realtek's website. I've pasted it below. Having no experience with installing drivers outside of plugins in CA, I have a few questions: Is manually installing the driver like the README instructs possible under Unraid? If so, this install would be wiped at every update, correct? Is this "manual" driver any different than the kernel driver that's coming soon™ ? Can this package serve as the basis for a CA plugin? Moreover, I'd just like to join the voices calling for a plugin for this chipset. It is the 10Gbe NIC for the masses: it's dirt cheap (38€ on Aliexpress atm), supports both SFP+ and RJ45, comes in PCIe4.0 x1 slots, consumes less than 2W, and supports ASPM out of the box (even though it for now locks C-states at C3 - similar behaviour to other RTL kernel drivers that have power savings off due to instability). In comparison: Intel X710 supports ASPM and C7+; but cost an arm and a leg, have 2 ports minimum, and come only in x8 format. AQC113 comes in PCIe 4.0 x1 slots; but is 50-100% more expensive than the RTL8127, uses double the power, is RJ45 only, and needs to be flashed with custom firmware to even support ASPM and C7+. AQN100 is SFP+, supports ASPM and C7+, but the driver is apparently not included in the kernel anymore, and is now unstable according to Unraid forums. Then there's all the X520/X540/X550 which "support" ASPM, but lock C-states to C3. I've seen how long we had to wait for Unraid to update the Kernel. And I've seen how bad these kernel drivers can be (RTL8125 still have power saving disabled in the kernel due to instability on early models, fucking over other users). I'd literally be down to pool some money to get this plugin done by the community, but done right with ASPM and C-state support. Even if Unraid updates the kernel, the RTL8127 kernel driver is currently broken and does not go further than C3. But some commenters seem to claim using this driver from Realtek directly would allow for better power management. <Linux device driver for Realtek Ethernet controllers> This is the Linux device driver released for Realtek 5 Gigabit Ethernet controllers with PCI-Express interface. <Requirements> - Kernel source tree (supported Linux kernel 2.6.x and 2.4.x) - For linux kernel 2.4.x, this driver supports 2.4.20 and latter. - Compiler/binutils for kernel compilation <Quick install with proper kernel settings> Unpack the tarball : # tar vjxf r8127-11.aaa.bb.tar.bz2 Change to the directory: # cd r8127-11.aaa.bb If you are running the target kernel, then you should be able to do : # ./autorun.sh (as root or with sudo) You can check whether the driver is loaded by using following commands. # lsmod | grep r8127 # ifconfig -a If there is a device name, ethX, shown on the monitor, the linux driver is loaded. Then, you can use the following command to activate the ethX. # ifconfig ethX up ,where X=0,1,2,... <Set the network related information> 1. Set manually a. Set the IP address of your machine. # ifconfig ethX "the IP address of your machine" b. Set the IP address of DNS. Insert the following configuration in /etc/resolv.conf. nameserver "the IP address of DNS" c. Set the IP address of gateway. # route add default gw "the IP address of gateway" 2. Set by doing configurations in /etc/sysconfig/network-scripts /ifcfg-ethX for Redhat and Fedora, or /etc/sysconfig/network /ifcfg-ethX for SuSE. There are two examples to set network configurations. a. Fixed IP address: DEVICE=eth0 BOOTPROTO=static ONBOOT=yes TYPE=ethernet NETMASK=255.255.255.0 IPADDR=192.168.1.1 GATEWAY=192.168.1.254 BROADCAST=192.168.1.255 b. DHCP: DEVICE=eth0 BOOTPROTO=dhcp ONBOOT=yes <Modify the MAC address> There are two ways to modify the MAC address of the NIC. 1. Use ifconfig: # ifconfig ethX hw ether YY:YY:YY:YY:YY:YY ,where X is the device number assigned by Linux kernel, and YY:YY:YY:YY:YY:YY is the MAC address assigned by the user. 2. Use ip: # ip link set ethX address YY:YY:YY:YY:YY:YY ,where X is the device number assigned by Linux kernel, and YY:YY:YY:YY:YY:YY is the MAC address assigned by the user. <Force Link Status> 1. Force the link status when insert the driver. If the user is in the path ~/r8127, the link status can be forced to one of the 5 modes as following command. # insmod ./src/r8127.ko speed=SPEED_MODE duplex=DUPLEX_MODE autoneg=NWAY_OPTION ,where SPEED_MODE = 1000 for 1000Mbps = 100 for 100Mbps = 10 for 10Mbps DUPLEX_MODE = 0 for half-duplex = 1 for full-duplex NWAY_OPTION = 0 for auto-negotiation off (true force) = 1 for auto-negotiation on (nway force) For example: # insmod ./src/r8127.ko speed=100 duplex=0 autoneg=1 will force PHY to operate in 100Mpbs Half-duplex(nway force). 2. Force the link status by using ethtool. a. Insert the driver first. b. Make sure that ethtool exists in /sbin. c. Force the link status as the following command. 2.5G before kernel v4.10 # ethtool -s eth0 autoneg on advertise 0x802f 2.5G for kernel v4.10 and later # ethtool -s eth0 autoneg on advertise 0x80000000002f 5G for kernel v4.10 and later (Couldn't be supported before kernel v4.10) # ethtool -s eth0 autoneg on advertise 0x180000000002f # ethtool -s eth0 autoneg on advertise 0x1000 (10G) # ethtool -s eth0 autoneg on advertise 0x002f (1G) # ethtool -s eth0 autoneg on advertise 0x000f (100M full) # ethtool -s eth0 autoneg on advertise 0x0003 (10M full) <Jumbo Frame> Transmitting Jumbo Frames, whose packet size is bigger than 1500 bytes, please change mtu by the following command. # ifconfig ethX mtu MTU , where X=0,1,2,..., and MTU is configured by user. RTL8127 supports Jumbo Frame size up to 9 kBytes. <EEE> Get/Set device EEE status Get EEE device status # ethtool --show-eee enp1s0 Set EEE device status # ethtool --set-eee enp1s0 eee on tx-lpi on tx-timer 1546 advertise 0x0008 (100M full) # ethtool --set-eee enp1s0 eee on tx-lpi on tx-timer 1546 advertise 0x0020 (1G) # ethtool --set-eee enp1s0 eee on tx-lpi on tx-timer 1546 advertise 0x8000 (2.5G)
-
Yeah, I never planned to use ZFS on the array, since single disk parity and individual disk spinup was the whole reason I chose Unraid. If I ever need a ZFS HDD server, I'll either run it in pools or just use TrueNAS. I have a side question regarding that. I'm not quite sure I understood the Unraid documentation regarding exclusive shares. Does it mean: /mnt/user/data becomes identical to /mnt/pool/data and both can be used interchangeably? /mnt/pool/data becomes the default option? I ask, because when installing new dockers after enabling exclusive shares, the default paths seem to randomly alternate between /mnt/user/... and /mnt/pool/... That's good to hear from you over anyone else. Were there any significant ZFS changes between 7.0 (the version the user in that post is running) and 7.1.4? Because if not I still can't explain what causes the orders of magnitude slower speeds of ZFS compared to BTRFS in that post. One one hand, he's running 32GB of RAM, and I assume he had enough free for ARC. His screenshots indicate he's using direct paths to pools, skipping FUSE overhead. On the other he's not really running a clean test since he's comparing a BTRFS RAID1 of 2 different drives, with a single disk ZFS pool of yet another drive model. The obvious answer is to test for myself, but I just don't have the spare hardware or server downtime to test for myself. Quality resources on ZFS vs BTRFS in pools on Unraid specifically are pretty much nonexistent. The Unraid documentation does a good job explaining the different file systems, but is still very surface level with no performance comparisons; and advertising snapshot support when there's still no built in snapshot tools (afaik) in Unraid is a bit disingenuous. The Snapshot plugin for BTRFS hasn't been updated in 2 years either, which only leaves btrbk and good old elbow grease. Do you have any opinion or experience you'd like to share on ZFS vs BTRFS for Unraid pools? BTRFS has worked fine so far, but the snapshot experience is not great. I'm about to get into some database-heavy stuff with critical data, so I'd like to commit to a file system before I start setting all that up.
-
I've stumbled upon this post detailing a user's experience and testing with ZFS (both array and pools) on Unraid. Anecdotally, I also often read about disappointing and unusually slow ZFS performance on Unraid, as compared to BTRFS. Even with NVMe pools where performance should be no issue whatsoever. I understand ZFS on the Unraid array is a special (and discouraged) use case, but pools should not be affected afaik. Personally, I've always stuck with BTRFS, but I am getting tired of the lack of proper GUI/native systems in Unraid to manage snapshots. So I've been itching to give ZFS a try, to see if the snapshot experience was any better; but these experiences have been putting me off. Reading into them however, no one seems to give a concrete explanation as to why ZFS pool performance is so poor in Unraid. Could someone more technically minded than me comment on this, and hopefully give an explanation?
-
Alright, I'll keep an eye on this in the coming updates. Thanks for your help!
-
Glad to hear LT is working on it. For now it isn't the end of the world, since I've been able to pin TOWER to the quick access bar with the array stopped. So therefore the issue is unrelated to my using New Permissions and Appdata Backup? I very recently updated from 6.12.x to 7.1.4, which would explain why I hadn't had the issue until now. It is very likely that I simply didn't notice the workgroup issue in the new update, until my mistake with New Permissions brought my attention to it.
-
It does indeed! How come?
-
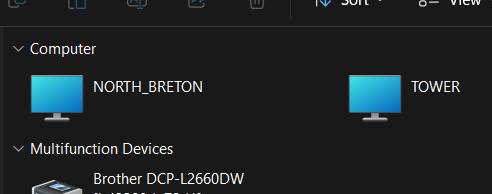
Some important context - I nuked my appdata share permissions with the New Permissions tool, because I'm an idiot who can't read the warning. Thankfully I had the Appdata Backup plugin, and I deleted the nuked appdata share and repopulated a new one of the same name, to avoid having to chmod 777 the existing share. All is well and good on that front, and I have been able to restore my docker containers without issue. However I now encounter the issue I described in the title. I do not know if this is caused by my New Permissions fuckup, or something else in my troubleshooting/restore steps. But it coincides perfectly with this disaster, so I assume it is related. To elaborate, my Unraid server used to show up as a connectable computer called "Tower" in my Windows workgroup (as does my desktop called "North_Breton" in the linked screenshot). This was handy since it meant I did not have to mount every share as a network drive/network location, hence cluttering my file explorer. It no longer appears in that workgroup area (the "Network" section of the Windows file explorer). However I noticed that for a few seconds after boot, the Unraid "Tower" is briefly visible and accessible, but disappears soon after. I also noticed that while the "Tower" disappears, the server and its SMB shares are still accessible when typing the adress manually in adress bar ( "\\TOWER" or "\\TOWER\appdata\plex" for instance ). Any ideas on what may cause this, and how to resolve this? Thanks in advance. Edit: forgot attachment.