





Evenimous
Members
-
Joined
-
Last visited
Everything posted by Evenimous
-
6 years is pretty solid for hard drive life span. I can't imagine needing to upgrade to that much data anytime soon, personally. I hope the upgrade goes smoothly.
-
What are you keeping on your array? That's a lot of data!
-
Update as promised, The rebuild for the second drive finished earlier this morning. I clicked around through some share folders, wrote some data, accessed some data, and deleted some data, and everything seems alright. I believe that my troubles were mostly related to something on Thursday, from the initial logs. A problem with my HBA seemed like the most feasible thing, and to me, seems like the likely point of failure for the system anyways. I am going to order another HBA, and some 8643 breakout cables, and keep them handy. The drives themselves are entirely fine, and I did not need to switch anything out. Thank you for the help. Edit so I can tag this as solved; I read through my logs, and with the help of the comments above determined that there was an intermittent issue, likely with my Adaptec ASR-71605. I plugged the problem drives into the motherboard via sata, and rebuilt using parity data. All is OK now. 👌
-
Will update. it's 2x 16TB 7200RPM drives, and I estimate it will take 18 hours per drive I rebuild, so it should be done by Sunday. Thank you, JorgeB, and itimpi for the input thus far.
-
I see. I only have ONE log from the system initially throwing errors, which I shared in my initial post. Every log since then has been shortly after a reboot, after trying a potential hardware fix, and upon reading your message, I looked back through the logs after that first one, and I have NOT seen any errors regarding the drives. They seem to be totally fine. I feel that it should be safe to rebuild the data drive with the parity data, so I will try that.
-
I left the system off overnight when it was having the problems, and just booted it this morning. I couldn't have had a better log, really. It's maybe only spent 10 minutes on total with the sata cables
-
sedona-diagnostics-20230505-0946.zip Reading through the syslog here, I don't seem to see any mention of a failure regarding the drives "sdg", or "sdf", the ones disabled. The log looks mostly to be boot information. The log even mentions reading the SMART for the disks in question, and it didn't show in any way that it disliked it or that it had failed.
-
I'll get the diag right now and check.
-
I chose the power supply I use because I can have all of the hard drives I'd need without needing to use splitters. I'm going to try another power cable anyways.
-
Wouldn't have plugging in the drives via sata cables rather than my hba ruled out the potential for a bad HBA? Regarding power, should I simply try another modular PSU cable from my box? I get my power from a Corsair HX750 hooked up to a Cyberpower UPS.
-
As another fix for the problem, and a way to diagnose either the cables or the card as bad, I have tried grabbing some spare SATA data cables and connecting those to the drives, and the motherboard, rather than the breakout cables and adaptec card. The same problem still persisted. Though, as I noted before, I am fairly certain the drives are not dead. Is there a way to re-enable the drives? What can cause a drive to become "disabled" like this?
-
Did this fix your issue?
-
I looked into this a bit further and found the following; Some of the problems seem to be coming from the Adaptec HBA card. I am getting "aacraid: host adapter abort request" errors, as well as "detected capacity change from 1600900661248 to 0" on sdf, sdb, sdc, and sde, with sdc and sde being some of the ones showing the problems. To me, this points to one of my sas breakout cables potentially being bad, as that's 4 drives, and I have 4 drives per cable on one cable, and 2 drives per cable on another. So, I powered down the server again, and I moved the SAS breakout cables from the right half of the ports on the adaptec to the left, and pressed them in securely until I heard the click, and then rebooted. Still no dice, on the exact same drives. I have a feeling that I should replace the cables or the adaptec. I do not feel that the drives are bad. Edit: added the diagnostics for my most recent boot. Very different from the first diag. sedona-diagnostics-20230504-1659.zip
-
I have been having the exact same issue. 2 drives not showing up and the same errors in the logs. You can see my post here. Did you ever fix your issue?
-
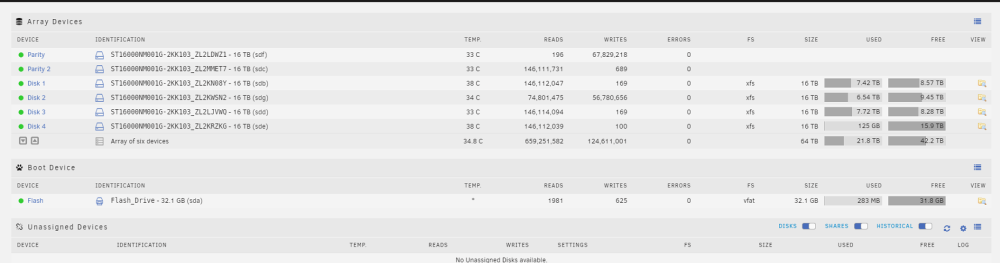
Hello forum, My UnRaid server started exhibiting an odd error earlier this morning. I was unable to access any of my user shares, so I started to look into why. When viewing the main tab, there is a red X next to Parity and next to Disk 2. In my system, there are 6 total hard drives in my system, with 4 drives as data, and 2 as Parity. They are all connected through an Adaptec ASR-71605 in HBA mode, using 8643 SAS to SATA breakout cables. My first thought was to try checking SMART data, so I went to Tools > Diagnostics > Download (with anonymize turned OFF), and tried to read the SMART data. To my surprise, All of the SMART files did not display any data, and were mostly empty. The problem drives were showing errors such as "Smartctl open device: /dev/sde failed: No such device or address" My next thought was to try checking from the UnRaid GUI by clicking the drives, and generating a smart short self test report per drive. To my dismay, nothing would show at all. Figuring there was some sort of bigger problem at play, I tried to click "STOP" on the array under Main in the webGUI, thinking it would allow me to generate SMART data afterwards. I went to the drives individually again, and I couldn't get anything to display, which was quite odd. Now, I figured the next easiest thing to do would be a simple reboot, so I opened the terminal, and typed "powerdown -r" to give it a fresh restart. Once the system booted, I went back into the webGUI, then to Tools > Diagnostics > Download for a new diag file, before ever mounting the array. This worked, and I was able to read the smart data. To me, the data seems alright. Not like there would be drive failures, but not fantastic either. I've linked the diag file here. Considering the SMART data seemed alright, I went back to the "main" tab, and even before the array was mounted, the same two drives were disabled. I tried mounting the array anyway, and again, they were disabled. My next thought was that there could be some sort of loose cable for power or data for those two drives, so again, I powered down the machine, but this time, without an immediate restart. I went into my server room and unplugged all cables from the drives, and reseated them, and then rebooted the system, and grabbed another diag file. Again, they were disabled. My final thought before deciding to write this was to check the system logs from my initial diagnostics zip, before I ever rebooted the system. I noticed some odd entries after 5AM this morning, a time when nobody would be using this system. I have no clue what any of these mean, so I wanted share that here and ask. Since that diag zip was not anonymized, I have linked solely that syslog.txt here, and it doesn't show anything I am uncomfortable sharing here. What is going on with my system? Is there bad hardware, or is something wrong with my configuration? --------------------------------------------------------------------------- For some additional context for the drives, the system was build on April 27th of 2022, and the drives were brand new off Amazon. I doubt that two of the drives would fail in the same morning a year later after working just fine for this long. Considering they're from the same batch, I would assume they would ALL fail within a close period of time to each other, but not only two of the drives. sedona-diagnostics-20230504-1133.zip syslog.txt
-
I always base the cost of a system on the current parts in it, not what used to be in it. Usually those are sold off or upcycled.
-
Are those parts from your old personal system that you upcycled?
-
For my own personal answer, My server cost roughly $2511 to build. The specs of my server are shown in my signature, but here's a breakdown Base Fractal Design 7XL ($250) (Newegg) Corsair HX750 80+ Plat Fully Modular PSU ($145) (Amazon) Adaptec ASR-71605 ($89.99) (Ebay) CableCreation Mini 8643 SAS->SATA Breakout Cable, 0.5M / 1.6ft ($15.59) (Amazon) Unraid Pro ($129) Compute Supermicro X9DRE-TF+ ($155) (Ebay) 2x Xeon E5-2660-v2 ($20/each) (Ebay) 2x32GB IBM 78P1539, RDIMM, 1066MHz ($34/each) (Ebay) Cooling Arctic P12 PWM 5 pack ($30.99) (Amazon) Noctua A4x10 FLX ($13.95) (Amazon) Arctic Freezer 34 Esports Duo ($46.7/each) (Amazon) Storage Samsung BAR 32GB USB (boot drive) ($13) (Newegg) 6x Seagate Exos x16 16TB (array) ($244.5/each) (Amazon) Things that I wish I purchased differently; I wish that I purchased a slightly newer CPU, for the sake of idle power consumption. I did not realize that the idle power consumption for this server would be 105-110w. To me, that seems like quite a bit. Power numbers are observed from my UPS with nothing else plugged into it. I also feel that the CPU coolers are entirely overkill for what I anticipated that I would need. I have literally never seen the temperatures go over 45C, And that's with extremely warm room ambient temperature, as I live in a hot climate and the server is in a room with no air conditioning. I wish that I purchased higher static pressure fans for the intake for the server. Some of the hard drives in the PSU basement get a little bit toasty in the summer, reaching 51C at max when the server is under full load from 5-10 users, which gives me concerns about drive longevity. Outside of the summer, the drives seem to stay comfortably in the 38-45 range under load, depending on ambient temperatures. The Supermicro board has its power connectors at the top... and this required me to get the most out of the cable lengths from even this power supply, which is pretty long. I would recommend cable extensions for other users in the future. The same can actually be said about the fan cables. It was difficult to get the fans to reach all the way along the case. I would have routed cables cleaner if I had enough slack to do so. I have also attached two pictures of the server from just before I deployed it. (Edit, added another picture showing the HBA with fan)



-
Hello, I was curious what the systems cost for hobbyists and sysadmins out there using UnRaid, as well as some other questions. Personally, I feel like I was able to get decent deals for my components. How much did your server cost to purchase or build? What are the specs of the aforementioned server, and do you feel that you got a good deal? What are the things about your server that you wish you purchased differently?
-
Thank you @Frank1940and @JorgeB for your thoughtful comments. I was already on the right path yesterday and found the source of my issue, which was actually exactly what you two had guessed. Previously, I had set up my UnRaid server to use active directory, though I recently switched off of it due to poor implementation. To my understanding, what that would have added in are more granular ACLs, controlled by the active directory administrator, rather than by UnRaid. After I learned what the "+" meant, and how to check ACLs with getfacl, I found my solution, which you may read below. --------------------------------------------------------- As mentioned in my initial post, the permissions were set to "-rw-rw----+", with "+" indicating that there is an access control list for the directory. To me, this means that the "users" group could potentially have "---" permissions within this ACL, which, once I checked, there was. Command used at terminal; > getfacl New\ folder <-- created "new folder" as "brad" user in windows Summarized response from terminal; > "group:users:---" <-- Previous assumption that the ACL was blocking was correct So, to fix my problem, I need to properly set the ACL. I first tested this within a test share, set to "secure" with all users given read and write perms, as follows. > cat /etc/group <--- Used to find what the GID is of the "users" group > users:x:100: <--- GID is "100", which will be used in setfacl Map test share as "brad" on device. Create folder named "folder" via windows file explorer. Check ACL via terminal on server > cd /mnt/user/testshare > getfacl folder Response below: --------------------------------------------------------- user::rwx user:nobody:rwx user:1590166004:rwx group::--- group:users:--- mask::rwx other::--- default:user::rwx default:user:nobody:rwx default:user:1590166004:rwx default:group::--- default:group:users:--- default:mask::rwx default:other::--- --------------------------------------------------------- Note how there is a user with a bunch of numbers. this is the active directory administrator. I'm simply going to ignore that user for now, as the admin should have perms anyways. The problem currently lies with "group:users:---", disallowing the users group from accessing the folder. Also, "default:group:users:---", which will make this non-access ACL propogate whenever new folders are created. I then changed the default ACLs and the ACL for the folder to allow the "users" group access with the two following commands: > setfacl -m g:100:rwx folder <--- Sets the users group on the folder to be allowed read, write, and execute > setfacl -d -m g:100:rwx folder <--- Sets the users group to be allowed by default on this folder, and any content created within the folders. Now we check the ACL of the folder to see if everything is alright. > getfacl folder Response below: --------------------------------------------------------- user::rwx user:nobody:rwx user:1590166004:rwx group::--- group:users:rwx mask::rwx other::--- default:user::rwx default:user:nobody:rwx default:user:1590166004:rwx default:group::--- default:group:users:rwx default:mask::rwx default:other::--- --------------------------------------------------------- Everything seems good, so I mapped the test share as user "John" and was able to read and write from the folder that Brad had created, and when I went on my other system previously set up for Brad, he was able to read and write anything John had created. All works well. So, now I just have to recursively write ACL changes to any of the shares experiencing the problem, aka all of them. Before I do that, I want to make sure I know how to do this recursively correctly, so I went into the test share again, and made a new file called "testfolder", and within that, a folder called "recursivefolder", and a file within that called "recursivefolderfile.txt". Then, I went back to my terminal and tried the following commands; --------------------------------------------------------- >setfacl -d -Rm g:100:rwx testfolder <--- I had previously messed up putting the "R" elsewhere. It must be BEFORE the modifier "m", or it won't work. Not sure why. >setfacl -Rm g:100:rwx testfolder <--- Must also set the non-default, or the current. This will apply to the files within the folder, as those don't have defaults, they simply inherit them. >getfacl testfolder <--- All good, as my previous fix above. >getfacl testfolder/recursivefolder <--- All good, recrusive functionality is working for folders >getfacl testfolder/recursivefolder/recursivefolderfile.txt <--- All good, recursive functionality worked for files too. --------------------------------------------------------- Now I recursively set this on my actual use folders, using the setfacl commands "setfacl -d -Rm g:100:rwx [foldername]" and "setfacl -RM g:100:rwx" after cd /mnt/user. This solved my problem. --------------------------------------------------------- Another potential problem that I realized is that /mnt/user was causing any new shares created to inherit these incorrect ACLs, so I changed that as well. I don't want any non-authenticated users to be able to access data on my unraid server, so other will be set to --- for my setup. > cd /mnt <-- Places us in the easiest spot to write the next command > setfacl -d -m g:100:rwx user <-- Fixes the "user" shares area of UnRaid for future use. Essentially will be "Secure" for any shares created.
-
I used two commands in the terminal to try to understand the users and the groups in UnRaid; > cat /etc/group > cat /etc/passwd Output for the first command, excluding unnecessary info, was as follows; > users:x:100: <-- Indicates to me that no users are a part of this group? should see something like "users:x:100:john:brad:" to show that they are part of that group and for the second command, was as follows; > brad:x:1004:100::/bin/false > john:x:1005:100:descriptioon:/:/bin/false <-- Indicates that both users are in group "100", which is users.... does not explain why they are not shown as part of the group or act like they are part of the group
-
Sorry for the super late reply, I never got an email notification for this lol. Before I continue, my reasoning for picking Seagate was that for their higher capacity drives, you can get $/GB that rivals shucking or beats it for some of their Exos line and for some of their NAS specific drives. Regarding the "studies", it was this one by Backblaze, as you had assumed. Say what you want, but regardless of them trying to promote their services, they are reporting based on their use of those drives, so they can't be too far from the truth. https://www.backblaze.com/blog/backblaze-drive-stats-for-2022/ If you are aware of any other hard drive / ssd failure rate and doa rate articles or studies, I would be happy to read them.
-
The title explains the problem... but let me give a bit more context. There are five user accounts that will be accessing this particular share. This share is set to: Export: Yes, Case-sensitive names: Auto, and Security: Secure. In the unraid GUI, under the share's security settings, every one of these accounts has been set as read/write capable for this share. They are all perfectly able to access the share via a mapped network drive in windows 10, and are able to read/write as they please, with the exception of this. Say for example, user "John" writes a file to /mnt/user/path/to/folder, and then user "Brad" goes to access this file. This file is not even readable for the "Brad" user, even though both of them should have full read/write access to this share. I figured that this may have been a configuration issue, so I went into the terminal, CD'd to the appropriate location, and then ls -la to check the ownership and permissions on the folders and files within /mnt/user/path/to/folder. The folders/files that were problematic were said to be "-rw-rw----+" in terms of permissions, and rather than being owned by "nobody users", was owned by "John users" To me, this means that they are all in the "users" group from Unraid, and thus "Brad" should have "rw" access to the folders/files created, at the very least. So, why can't "Brad" read and write to this file, and why does "John" own the files/folders they wrote, rather than the "nobody" user? How may I make it such that the files written are accessible in the manner I have configured in the GUI?
-
I found the solution to my problem. The Unraid Server will not be considered to be disconnected from the Active Directory until it has been rebooted. I had not rebooted my server, so I waited for a good time, then tried that, and it worked. I then had to go into the unraid terminal through the gui, and make sure that the "root" user had ownership of the base directory of the user shares to make sure that UnRaid's GUI features would work correctly again.
-
Yes, SMB is enabled. NFS is also enabled.






