





Evenimous
Members
-
Joined
-
Last visited
-
6 years is pretty solid for hard drive life span. I can't imagine needing to upgrade to that much data anytime soon, personally. I hope the upgrade goes smoothly.
-
What are you keeping on your array? That's a lot of data!
-
Update as promised, The rebuild for the second drive finished earlier this morning. I clicked around through some share folders, wrote some data, accessed some data, and deleted some data, and everything seems alright. I believe that my troubles were mostly related to something on Thursday, from the initial logs. A problem with my HBA seemed like the most feasible thing, and to me, seems like the likely point of failure for the system anyways. I am going to order another HBA, and some 8643 breakout cables, and keep them handy. The drives themselves are entirely fine, and I did not need to switch anything out. Thank you for the help. Edit so I can tag this as solved; I read through my logs, and with the help of the comments above determined that there was an intermittent issue, likely with my Adaptec ASR-71605. I plugged the problem drives into the motherboard via sata, and rebuilt using parity data. All is OK now. 👌
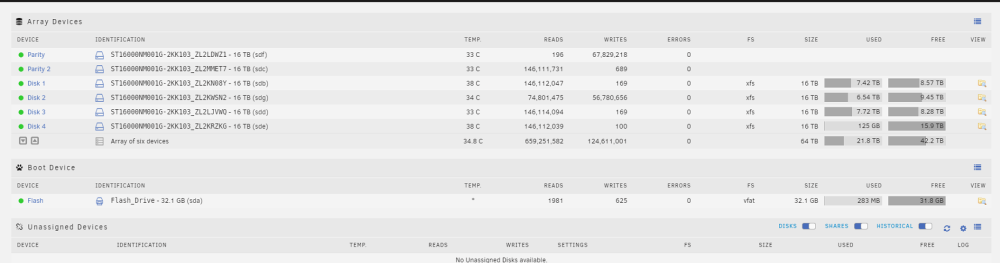
-
Will update. it's 2x 16TB 7200RPM drives, and I estimate it will take 18 hours per drive I rebuild, so it should be done by Sunday. Thank you, JorgeB, and itimpi for the input thus far.
-
I see. I only have ONE log from the system initially throwing errors, which I shared in my initial post. Every log since then has been shortly after a reboot, after trying a potential hardware fix, and upon reading your message, I looked back through the logs after that first one, and I have NOT seen any errors regarding the drives. They seem to be totally fine. I feel that it should be safe to rebuild the data drive with the parity data, so I will try that.
-
I left the system off overnight when it was having the problems, and just booted it this morning. I couldn't have had a better log, really. It's maybe only spent 10 minutes on total with the sata cables
-
sedona-diagnostics-20230505-0946.zip Reading through the syslog here, I don't seem to see any mention of a failure regarding the drives "sdg", or "sdf", the ones disabled. The log looks mostly to be boot information. The log even mentions reading the SMART for the disks in question, and it didn't show in any way that it disliked it or that it had failed.
-
I'll get the diag right now and check.
-
I chose the power supply I use because I can have all of the hard drives I'd need without needing to use splitters. I'm going to try another power cable anyways.
-
Wouldn't have plugging in the drives via sata cables rather than my hba ruled out the potential for a bad HBA? Regarding power, should I simply try another modular PSU cable from my box? I get my power from a Corsair HX750 hooked up to a Cyberpower UPS.
-
As another fix for the problem, and a way to diagnose either the cables or the card as bad, I have tried grabbing some spare SATA data cables and connecting those to the drives, and the motherboard, rather than the breakout cables and adaptec card. The same problem still persisted. Though, as I noted before, I am fairly certain the drives are not dead. Is there a way to re-enable the drives? What can cause a drive to become "disabled" like this?
-
Did this fix your issue?
-
I looked into this a bit further and found the following; Some of the problems seem to be coming from the Adaptec HBA card. I am getting "aacraid: host adapter abort request" errors, as well as "detected capacity change from 1600900661248 to 0" on sdf, sdb, sdc, and sde, with sdc and sde being some of the ones showing the problems. To me, this points to one of my sas breakout cables potentially being bad, as that's 4 drives, and I have 4 drives per cable on one cable, and 2 drives per cable on another. So, I powered down the server again, and I moved the SAS breakout cables from the right half of the ports on the adaptec to the left, and pressed them in securely until I heard the click, and then rebooted. Still no dice, on the exact same drives. I have a feeling that I should replace the cables or the adaptec. I do not feel that the drives are bad. Edit: added the diagnostics for my most recent boot. Very different from the first diag. sedona-diagnostics-20230504-1659.zip
-
I have been having the exact same issue. 2 drives not showing up and the same errors in the logs. You can see my post here. Did you ever fix your issue?
-
Hello forum, My UnRaid server started exhibiting an odd error earlier this morning. I was unable to access any of my user shares, so I started to look into why. When viewing the main tab, there is a red X next to Parity and next to Disk 2. In my system, there are 6 total hard drives in my system, with 4 drives as data, and 2 as Parity. They are all connected through an Adaptec ASR-71605 in HBA mode, using 8643 SAS to SATA breakout cables. My first thought was to try checking SMART data, so I went to Tools > Diagnostics > Download (with anonymize turned OFF), and tried to read the SMART data. To my surprise, All of the SMART files did not display any data, and were mostly empty. The problem drives were showing errors such as "Smartctl open device: /dev/sde failed: No such device or address" My next thought was to try checking from the UnRaid GUI by clicking the drives, and generating a smart short self test report per drive. To my dismay, nothing would show at all. Figuring there was some sort of bigger problem at play, I tried to click "STOP" on the array under Main in the webGUI, thinking it would allow me to generate SMART data afterwards. I went to the drives individually again, and I couldn't get anything to display, which was quite odd. Now, I figured the next easiest thing to do would be a simple reboot, so I opened the terminal, and typed "powerdown -r" to give it a fresh restart. Once the system booted, I went back into the webGUI, then to Tools > Diagnostics > Download for a new diag file, before ever mounting the array. This worked, and I was able to read the smart data. To me, the data seems alright. Not like there would be drive failures, but not fantastic either. I've linked the diag file here. Considering the SMART data seemed alright, I went back to the "main" tab, and even before the array was mounted, the same two drives were disabled. I tried mounting the array anyway, and again, they were disabled. My next thought was that there could be some sort of loose cable for power or data for those two drives, so again, I powered down the machine, but this time, without an immediate restart. I went into my server room and unplugged all cables from the drives, and reseated them, and then rebooted the system, and grabbed another diag file. Again, they were disabled. My final thought before deciding to write this was to check the system logs from my initial diagnostics zip, before I ever rebooted the system. I noticed some odd entries after 5AM this morning, a time when nobody would be using this system. I have no clue what any of these mean, so I wanted share that here and ask. Since that diag zip was not anonymized, I have linked solely that syslog.txt here, and it doesn't show anything I am uncomfortable sharing here. What is going on with my system? Is there bad hardware, or is something wrong with my configuration? --------------------------------------------------------------------------- For some additional context for the drives, the system was build on April 27th of 2022, and the drives were brand new off Amazon. I doubt that two of the drives would fail in the same morning a year later after working just fine for this long. Considering they're from the same batch, I would assume they would ALL fail within a close period of time to each other, but not only two of the drives. sedona-diagnostics-20230504-1133.zip syslog.txt

