




AeroMaestro
Members
-
Joined
-
Last visited
Everything posted by AeroMaestro
-
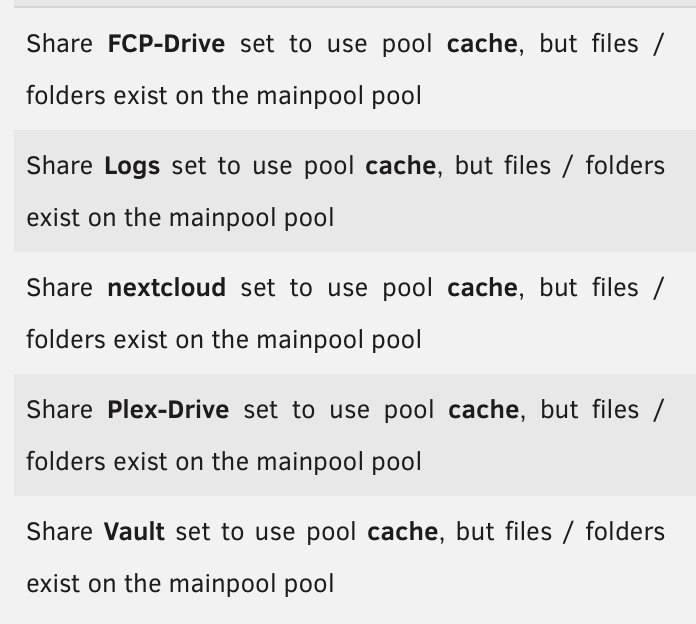
I'm also having issues with the "Files / Folders exist on..." errors. In this screenshot, every one of these shares has cache as the primary storage and mainpool as the secondary storage, so they're behaving as expected. Cache and Mainpool are both ZFS pools, and I do not have an Array. I suspect this issue is caused by the plugin not understanding that I don't have an array.
-
How do I spin down an unassigned HDD? I've pre cleared this drive, and I want to keep it in the server as a ready spare. How do I spin it down? The green dot to the left isn't clickable. I don't think it's mounted -- it has no mountable filesystem because it's just been pre cleared. I can't seem to find any spin down settings anywhere applying to this drive. I need to keep it connected so I can swap it in if necessary from the road, but don't have any need for it to be spinning, accruing Power On Hours, and wasting electricity.

-
I have a script in Un that's been working for months, based off the example script from post #1 -- when I plug in an external drive, it mounts and does an rsync of several of my shares. But now, for some reason, I can't alter that script. I can see the script in the script editor. I can type my changes in. But clicking "Apply" doesn't update the script--It just reloads the screen and my changes are gone. I don't get a "save" button... but I can click the Delete button, which gives me a "Save" option. I paste my script back in, but "Save" is still greyed out. Clicking the "Reset" button works as expected - just reverting the script. If I click "Default" it populates with the default script, but even then when I click Save it just reverts back to an empty script. Do I have a permissions error somewhere that's preventing it from saving? I've tried Safari, Chrome, and Firefox. The problem persists in all three browsers. Help? EDIT -- I seem to have gotten around my problem. I deleted all the scripts that were present, since the "Delete" button seems to work properly. Then I just opened a terminal, nano /boot/config/unassigned.devices/Cold_Storage.sh and pasted my script in there. Went back to Unassigned Devices, selected the script I created manually, clicked "Save" and it's all good.
-
I started noticing some messages in the logs about TIMEMACHINE being "a local master browser for workgroup WORKGROUP" -- sometimes it seemed to revert to unRAID, and sometimes it would switch back to timemachine. I really don't understand SMB in this regard, but I edited the timemachine to be on its own workgroup (WORKGROUP2) so it wouldn't conflict with unRAID's master status. At least, in my mind, that seemed to make sense--perhaps my client computers were having trouble connecting to the timemachine share because there was confusion about who the master was and where the share was located. BUT also, it looks like this docker pushed an update last night. I'm not sure what's changed, but it appears to be working OK again now. I have three clients all connected and backing up and it's been running for about six hours without error so far. So I'm not exactly sure if switching the workgroup fixed my issue, or if the latest update fixed it, but things are still running OK. Apologies to anybody searching for a solution to a similar issue -- I wasn't very scientific here.
-
Actually, after some more experimenting, it seems the problem might be caused by the latest MacOS release 14.3.1. I have two clients that are both on MacOS 14.3.1 and they're both having this same issue. I have one older macbook on an earlier release of MacOS and it continues to work without any troubles.
-
Hey folks. My timemachine implementation has gone all wonky. After a full unRAID reboot, I can get it to run for a while. (Have to reboot my client computers, too.) But then after 30 minutes or so it just keeps spitting out this error: scavenger_timer: Failed to cleanup share modes and byte range locks for file 52:11540474045137110:0 open 3433579876 scavenger_timer: Failed to cleanup share modes and byte range locks for file 52:11540474045137784:0 open 2202357559 scavenger_timer: Failed to cleanup share modes and byte range locks for file 52:648799821323949090:0 open 3485260591 scavenger_timer: Failed to cleanup share modes and byte range locks for file 52:11540474045138732:0 open 4061891360 scavenger_timer: Failed to cleanup share modes and byte range locks for file 52:648799821323949088:0 open 541969747 scavenger_timer: Failed to cleanup share modes and byte range locks for file 52:648799834239568738:0 open 2356579153 ... and my timemachine backups fail. Here's what I've tried: * I've rebooted everything multiple times, restarted timemachine docker many many times, too. * I thought maybe there was some corrupted file in one of my backups, so I've deleted all files out of the timemachine share. * I've run the permissions command as suggested by the timemachine docker template: sudo chown -R 1000:1000 /mnt/user/timemachine/ * I've turned SMB sharing off and on again. * I've completely uninstalled the timemachine docker, deleted the timemachine share, and reinstalled everything. I'm not exactly sure if this started after my update to unRAID 6.12.8 or not. I think yes, but it's possibly coincidental.
-
Thanks a bunch. I'm working remotely today, so I've only tried the checkmark so far, and the fsck gives me this: FS: hfsplus Executing file system check: /usr/sbin/fsck.hfsplus -l '/dev/sdg2' 2>&1 ** /dev/sdg2 (NO WRITE) ** Checking HFS Plus volume. ** Checking Extents Overflow file. ** Checking Catalog file. ** Checking Catalog hierarchy. ** Checking Extended Attributes file. ** Checking volume bitmap. ** Checking volume information. ** The volume Cold Storage appears to be OK. So UD+ wasn't able to fix the problem, but when I get home I'll plug it into the mac and properly unmount it. EDIT - Some time later - Yup. That fixed it. I guess my routine is going to require me to spend the extra five seconds every day to properly eject the drive from my mac before I plug it into the Unraid server.
-
Hey unassigned folks. I have an external HD. Two partitions. First one is APFS, second is HFS+. I've successfully gotten Unassigned Devices Plus to work and setup a script so that when I plug in the drive it automatically backs up some of my Shares to the HFS+ partition. That worked once or twice, but now every time I plug in the external drive that HFS+ partition just mounts as "Read Only" and all the rsync commands in the script fail, showing "Read-only file system". I've been searching like crazy, but all I can find are lots and lots of posts in the Unraid forums with people having a similar issue, and the mods telling them to repost it here. Any advice? unraid-diagnostics-20231116-1122.zip
-
EDIT -- I rolled my Transmission_VPN back to version 5.1.0 from about a week ago, and it's working fine. So the latest update, pushed out this morning, seems to be causing the trouble with IPv6. I'm also having trouble with the Transmission_VPN container, which started for me immediately after updating Unraid to 6.12.4. (Although I also updated my Transmission_VPN Docker container about 1 minute before updating Unraid, and the new issue could be caused by the container update rather than the OS.) The container appears to startup OK, but the GUI is unresponsive, and the Transmission API isn't responding to any of my *arrs. After about 9 minutes it just gives an "unhealthy" label in the Docker settings. I've checked the log, and here's what I'm seeing (starting with just the first error code): 2023-09-05 13:18:59 sitnl_send: rtnl: generic error (-101): Network is unreachable 2023-09-05 13:18:59 ROUTE6: default_gateway=UNDEF 2023-09-05 13:18:59 TUN/TAP device tun0 opened 2023-09-05 13:18:59 net_iface_mtu_set: mtu 1500 for tun0 2023-09-05 13:18:59 net_iface_up: set tun0 up 2023-09-05 13:18:59 net_addr_v4_add: 10.13.111.7/24 dev tun0 2023-09-05 13:18:59 net_route_v4_add: 181.215.182.203/32 via 172.17.0.1 dev [NULL] table 0 metric -1 2023-09-05 13:18:59 net_route_v4_add: 0.0.0.0/1 via 10.13.111.1 dev [NULL] table 0 metric -1 2023-09-05 13:18:59 net_route_v4_add: 128.0.0.0/1 via 10.13.111.1 dev [NULL] table 0 metric -1 2023-09-05 13:18:59 WARNING: OpenVPN was configured to add an IPv6 route. However, no IPv6 has been configured for tun0, therefore the route installation may fail or may not work as expected. 2023-09-05 13:18:59 add_route_ipv6(2000::/3 -> :: metric -1) dev tun0 2023-09-05 13:18:59 net_route_v6_add: 2000::/3 via :: dev tun0 table 0 metric -1 2023-09-05 13:18:59 sitnl_send: rtnl: generic error (-13): Permission denied 2023-09-05 13:18:59 ERROR: Linux IPv6 route can't be added 2023-09-05 13:18:59 WARNING: External program may not be called unless '--script-security 2' or higher is enabled. See --help text or man page for detailed info. 2023-09-05 13:18:59 WARNING: Failed running command (--route-up): disallowed by script-security setting 2023-09-05 13:18:59 WARNING: this configuration may cache passwords in memory -- use the auth-nocache option to prevent this 2023-09-05 13:18:59 Initialization Sequence Completed So it looks like there's something involving IPv6 that it doesn't like, but I don't see any IPv6 settings anywhere in the Transmission_VPN settings. Perhaps this is something about the Private Internet Access servers that Unraid doesn't like anymore?
-
I use your Transmission_VPN docker package, and it's been terrific. But for the past few months, I find I need to restart the docker about once per day. It isn't crashing, but after a few hours all the transfers just seem to stall. It'll add new torrents just fine, and they'll populate Seeders and Leechers, but it just won't start downloading or uploading anything. Nothing downloads, and none of my seeds upload anymore. Restarting the container fixes the issue, and it's good for several hours but then stalls again. Maybe this is some sort of Private Internet Access problem, but does anybody else have this behavior? I think I might switch PIA servers and see if that makes any difference. (But I think I might've tried that already several weeks ago.) Edit: 36 hours later -- changing PIA servers didn't help. But I'm just using the User Scripts plugin to restart the docker every few hours and that's good enough, I suppose.
-
My unRAID server has two different ethernet NICs: eth0 is 1gbps, ip 192.168.1.xxx eth1 is 2.5gbps, ip 192.168.2.xxx I connect eth0 (1gbps) to a switch and it's used for general networking and internet. I connect eth1 (2.5gbps) directly to my client computer (which dual-boots MacOS and windows) I've been running all my SMB shares as public to keep my life simple, but would like--for obvious reasons--to change them over to Private. So I created a new user in unraid, and that user has read/write access to all shares. Then I created a new share (TestingShare) and setup SMB on that share with private security, and gave my (testuser) user read/write access. When I try to connect to the share on eth1 (2.5gbps), it prompts me for a user/pass, but then I just get an error. Windows and MacOS both fail to connect on 192.168.2.xxx. But if I try to connect to the TestingShare on eth0 (1gbps, 192.168.1.xxx), I get the login prompt, and it connects just fine. Frustratingly, I've always been able to connect without trouble to all of my shares over the eth1 (2.5gbps) connection when they're public. But changing them to private causes problems and I can only connect on eth0 (1gbps.) Got any ideas how I could fix it? I looked around the SMB settings and found: "Enable SMB Multi Channel:" I tried turning it on thinking this might help SMB fully work on both NICs, but that didn't make any difference.
-
Aha! Some limited success! My home network is on 192.168.1.0 my WireGuard VPN is on 10.253.0.0. So I switched this LOCAL NETWORK setting to 10.253.0.0/24 and now I can access the WebGUI from my VPN connections but can't access it from my home network. Got any ideas how I can possibly add a second Local Network in these settings? I see clowrym's script suggestion, but I'll admit I'm enough of a Docker newbie that I'm not sure where I'd put that script or precisely what it does. EDIT: I just tried going back to that LOCAL_NETWORK setting and wrote 10.253.0.0/24, 192.168.1.0/24 And it worked! I can't believe it was that easy! I can access the GUI from my Wireguard VPN and from my home network. Sheesh. I've been on the road for over a week and struggling with this the whole time.
-
Thanks for maintaining this TransmissionVPN app. I'm having trouble accessing the webUI through my wireguard VPN. I can access the webUI from my home LAN without any trouble, so I'm reasonably certain my home network is set properly in the Docker. But I need to access the webui through my Wireguard VPN. When I'm on the road I access ALL my other dockers through this Wireguard VPN. This Transmission docker is the only one I can't get to. Any suggestion where I might start looking in the Transmission docker settings to get this to work? In wireguard, I've tried setting up various different peers using either "Remote tunneled access" or "Remote Access to LAN". Both work for all my other dockers. Neither works for this Transmission docker.



