





LeeNeighoff
Members
-
Joined
-
Last visited
Everything posted by LeeNeighoff
-
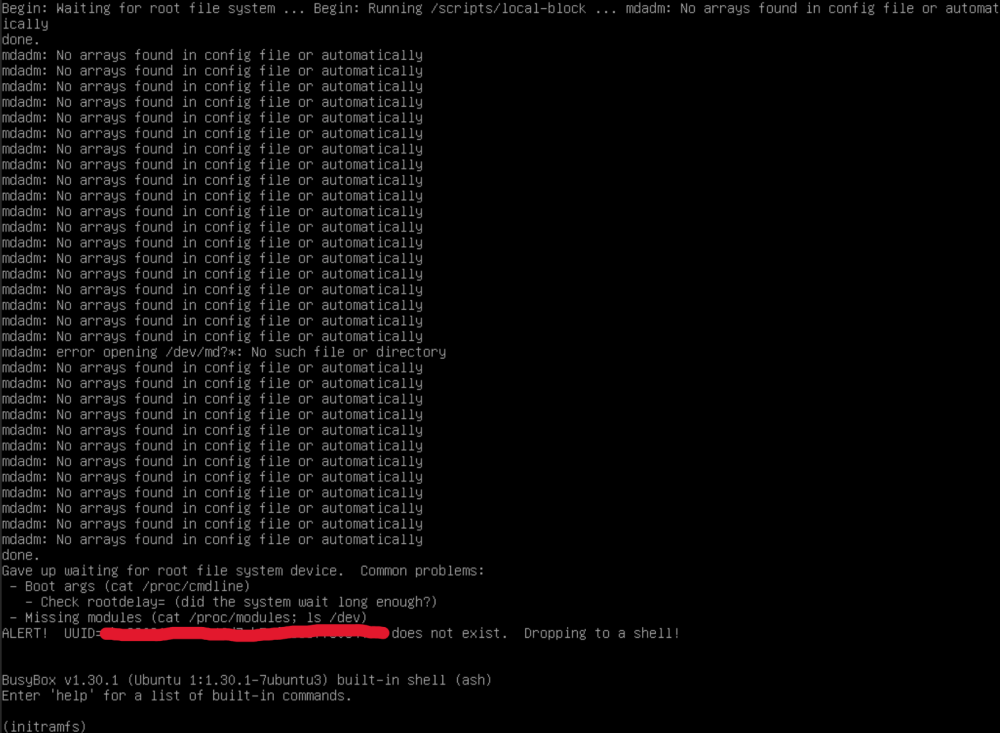
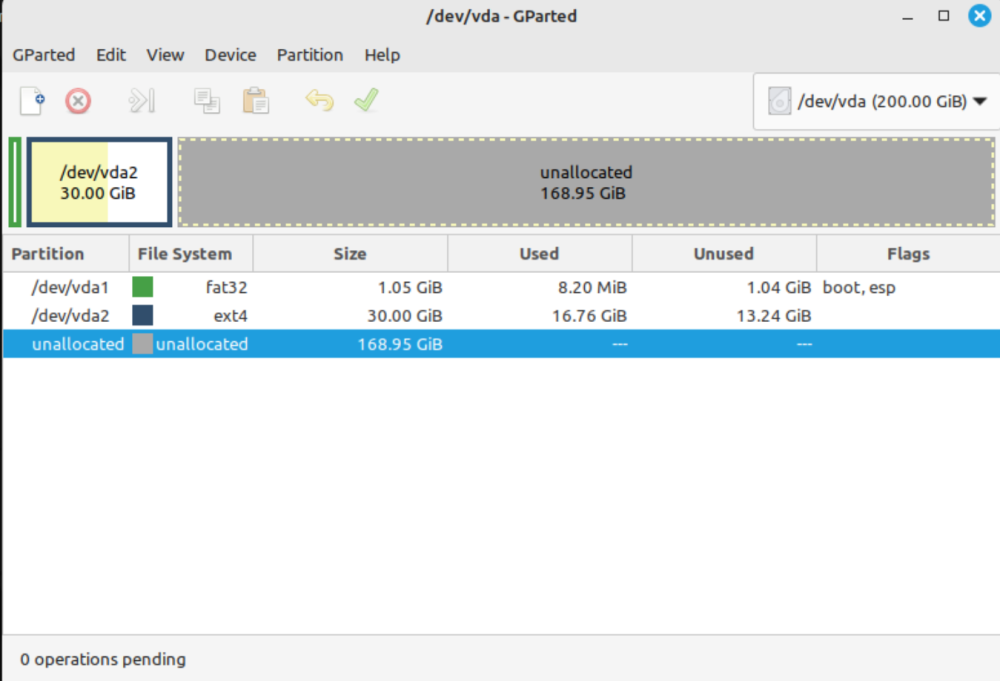
I'm having some trouble shrinking my Ubuntu Server 22.04 vdisk from 200 GiB to 40 GiB. I booted into a live distro, used GParted to shrink the primary partition to 30 GiB (to expand up to 40 later), and confirmed there are no partitions after it. Booted back into Ubuntu and it worked perfectly. Shut it back down and made a backup. Resized the .img file with qemu-img to 40G, and now suddenly it will no longer boot. It gives up waiting for the root filesystem to become available. Since I had a backup, I tried multiple different variations of the command, to no avail: qemu-resize --shrink vdisk1.img 40G qemu-resize --shrink vdisk1.img 199G qemu-resize --shrink -f raw vdisk1.img 40G qemu-resize --shrink -f raw vdisk1.img 199G Am I missing a critical step for Ubuntu/Linux that isn't required for shrinking a Windows vdisk? Thanks in advance.
-
I'm also experiencing this issue. I want to use the VPN and manage my server/access home resources directly from my phone, but I'm unable to do so due to T-Mobile's IPv6 network and Verizon FiOS's IPv4 network. Apparently FiOS has IPv6 support in limited areas, but I'm not in one of them.
-
Shot in the dark considering how old this thread is, but were you able to determine what the cause of this was? I can't seem to replicate it on demand so it's hard to tell what causes dockerd to cause CPU stalls/spinlocks.
-
I am also having this issue, on 6.12.3 with a Ryzen 3950X. Tried thor2002ro's updated kernel (mostly for Arc GPU compatibility, but also to troubleshoot this) as well, but I see the same behavior. It gets to the point that all 32 threads hit 100%, the web GUI stops responding, and all services running on both VMs and Docker containers cease to operate. EDIT: After viewing the syslog live, I caught it locking up. Several/many instances of "rcu_preempt self-detected stall on CPU," "rcu_preempt detected expedited stalls on CPUs/tasks," and "native_queued_spin_lock_slowpath" for CPU 20, with "PID: dockerd Tainted: P O." Investigating further as it seems something either Docker or a container is doing is locking things up. EDIT 2: After dealing with intel_gpu_top spawning ~30 processes each using 100% of a CPU thread and fighting the VM Manager locking up the system afterwards, I've determined that in this case, my issue came down to a VM with corrupted data. After moving my entire VM cache drive to the array, running a parity check, and then updating every component of the VM's OS and installed software, things have stabilized. For now, at least.
-
I feel like I'm missing something simple here. My container is experiencing a slow network connection. When I set my NDI bandwidth to lowest, everything in OBS is smooth. But, when I set it to highest, both the audio and video hang every few seconds. I have a VM running on br0 as well, but it doesn't use much bandwidth. I tried setting the container to use bridge, host, and another custom network, but I could not get it to see my NDI source on any of them, so I can't really continue troubleshooting. Checking Task Manager on the source PC shows that NDI isn't using more than 120 Mbps on a gigabit LAN connection. The source PC and unRAID server are connected to the same switch and router.


