dgallaher
Members
-
Joined
-
Last visited
-
[27.05.2025 09:42:13][][Main] WELCOME TO APPDATA.BACKUP!! :D [27.05.2025 09:42:13][][Main] Backing up from: /mnt/user/appdata, /mnt/cache/appdata [27.05.2025 09:42:13][][Main] Backing up to: /mnt/user/backups/ab_20250527_094213 [27.05.2025 09:42:13][][Main] Cannot create destination folder! [27.05.2025 09:42:20][][Main] Checking retention... [27.05.2025 09:42:20][][Main] DONE! Thanks for using this plugin and have a safe day ;) [27.05.2025 09:42:20][][Main] Have gotten this error about not being able to create the destination folder for a couple weeks now. Nothing obvious sticks out to me--there should be plenty of space available on the array in the /user/backups/ share, no disks excluded from that share, and I don't see anything in the unraid syslog that provides further context. I submitted the plugin debug log at 225e0926-27d8-450d-82c4-bf6a243c5643 and would appreciate any help in diagnosing
-
Apologies if this has been answered somewhere in the previous pages, but I searched and could not find an answer. I have the Dynamix System Stats plugin installed and love the clean and simple graphs it creates. I'd love to be able to export/embed these graphs on a publicly accessible webpage, but I'm not sure how I would go about it. Is it possible, and if so, might someone point me in the right direction? Ideally I'd be able to display the tabs for Disk Stats as well as System Stats.
-
I'm in the same situation and haven't been able to find a working link for telegraf.conf. Any help?
-
The above process worked pretty flawlessly, thank you for the help and working through this with me!
-
Thank you, @JorgeB. I did as you suggested: powered down and replaced the SATA cable and reseated the power cables. Disk 7 has reappeared (as you probably suspected) and disk 5 now shows as unmountable, which also seems expected. I've started extended SMART scans on both disks for now and have posted diagnostics. If the SMART scans complete without issue, do you think it's safe to go ahead and just try to rebuild disk 5? dunbar-diagnostics-20221112-1027.zip
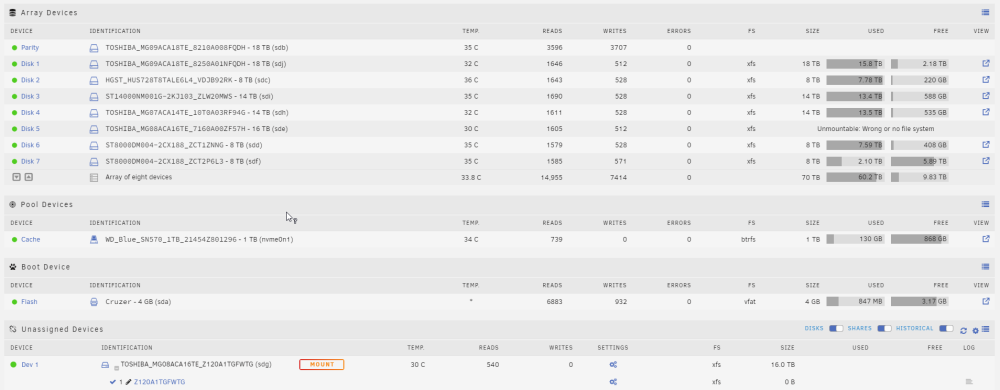
-
Version 6.11.2 I replaced disk 5 (sdg) from the screenshot above with an identical disk (sde) and started to rebuild that disk. During the rebuild, disk 7 (sdf) began to report lots of errors and eventually failed. The array rebuild continued and eventually completed, but obviously disk 5 has not been fully/successfully reconstructed. The previous disk 5 (dev 1/sdg in unassigned devices above) is still operational and could be put back into the array. However, during the rebuild, there were docker containers running that were writing to the array (like a torrent client, etc.). So I am assuming that I will lose some amount of data here and that the best I can hope for is to mitigate/minimize my losses as much as possible, but I'm unsure exactly what the best next steps to take would be. Can I just swap dev 1/sdg back into the disk 5 slot? And then try to rebuild disk 7 on a new drive? I assume since there have been further writes to the array after sdg was taken out of the array that this would mean parity sync issues. Diagnostics are attached but not exactly sure how much help they will be. Please let me know if there's any other info I can provide and how you might recommend to proceed. Your help would be really appreciated. dunbar-diagnostics-20221108-2153.zip
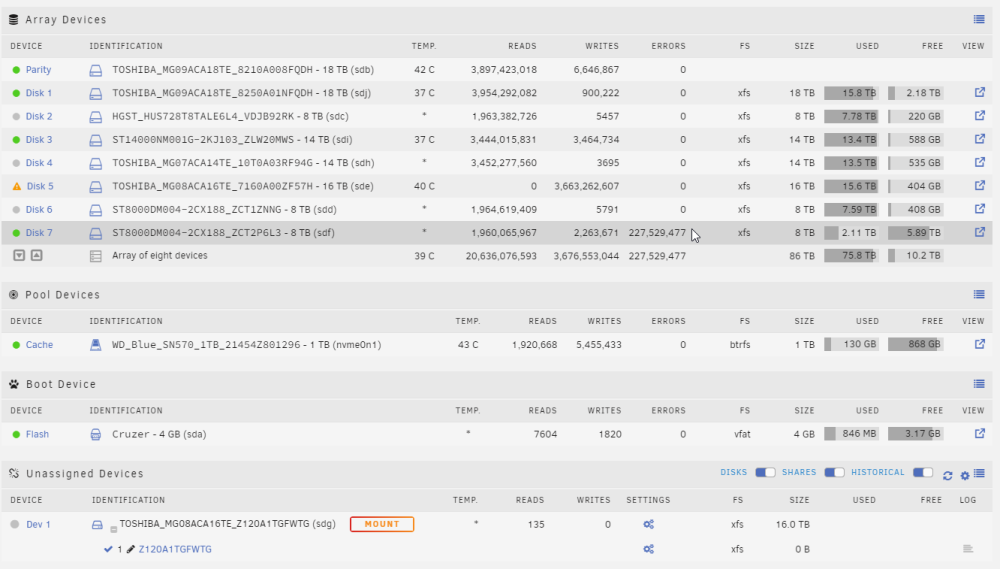
-
A-ha, found out how to generate diagnostics via the command line. Attaching here. dunbar-diagnostics-20220114-1423.zip
-
Having some trouble pinning down this issue, but having quite a few weird issues with the webGUI and it must be related to something filling up RAM. Any help is appreciated! I've tried to generate the diagnostics file, but when I click Tools > Diagnostics > Download, I get the popup that the file will download and then nothing happens. The syslog snippet available in webGUI is full of yellow and red warnings: Jan 14 11:35:33 dunbar nginx: 2022/01/14 11:35:33 [error] 3275#3275: shpool alloc failed Jan 14 11:35:33 dunbar nginx: 2022/01/14 11:35:33 [error] 3275#3275: nchan: Out of shared memory while allocating channel /diagnostic. Increase nchan_max_reserved_memory. Jan 14 11:35:33 dunbar nginx: 2022/01/14 11:35:33 [alert] 3275#3275: *625513 header already sent while keepalive, client: 192.168.0.165, server: 0.0.0.0:80 Jan 14 11:35:33 dunbar kernel: nginx[3275]: segfault at 0 ip 0000000000000000 sp 00007ffd93cf4428 error 14 in nginx[400000+22000] Jan 14 11:35:33 dunbar kernel: Code: Unable to access opcode bytes at RIP 0xffffffffffffffd6. Jan 14 11:35:33 dunbar nginx: 2022/01/14 11:35:33 [alert] 12346#12346: worker process 3275 exited on signal 11 Jan 14 11:35:33 dunbar nginx: 2022/01/14 11:35:33 [crit] 3295#3295: ngx_slab_alloc() failed: no memory Jan 14 11:35:33 dunbar nginx: 2022/01/14 11:35:33 [error] 3295#3295: shpool alloc failed Jan 14 11:35:33 dunbar nginx: 2022/01/14 11:35:33 [error] 3295#3295: nchan: Out of shared memory while allocating channel /var. Increase nchan_max_reserved_memory. Jan 14 11:35:33 dunbar nginx: 2022/01/14 11:35:33 [alert] 3295#3295: *625515 header already sent while keepalive, client: 192.168.0.165, server: 0.0.0.0:80 Jan 14 11:35:33 dunbar kernel: nginx[3295]: segfault at 0 ip 0000000000000000 sp 00007ffd93cf4428 error 14 in nginx[400000+22000] Jan 14 11:35:33 dunbar kernel: Code: Unable to access opcode bytes at RIP 0xffffffffffffffd6. Jan 14 11:35:33 dunbar nginx: 2022/01/14 11:35:33 [alert] 12346#12346: worker process 3295 exited on signal 11 Jan 14 11:35:33 dunbar nginx: 2022/01/14 11:35:33 [crit] 3296#3296: ngx_slab_alloc() failed: no memory Jan 14 11:35:33 dunbar nginx: 2022/01/14 11:35:33 [error] 3296#3296: shpool alloc failed Jan 14 11:35:33 dunbar nginx: 2022/01/14 11:35:33 [error] 3296#3296: nchan: Out of shared memory while allocating channel /cpuload. Increase nchan_max_reserved_memory. Jan 14 11:35:33 dunbar nginx: 2022/01/14 11:35:33 [error] 3296#3296: *625522 nchan: error publishing message (HTTP status code 507), client: unix:, server: , request: "POST /pub/cpuload?buffer_length=1 HTTP/1.1", host: "localhost" Jan 14 11:35:34 dunbar nginx: 2022/01/14 11:35:34 [crit] 3296#3296: ngx_slab_alloc() failed: no memory Jan 14 11:35:34 dunbar nginx: 2022/01/14 11:35:34 [error] 3296#3296: shpool alloc failed Jan 14 11:35:34 dunbar nginx: 2022/01/14 11:35:34 [error] 3296#3296: nchan: Out of shared memory while allocating channel /disks. Increase nchan_max_reserved_memory. Jan 14 11:35:34 dunbar nginx: 2022/01/14 11:35:34 [error] 3296#3296: *625523 nchan: error publishing message (HTTP status code 507), client: unix:, server: , request: "POST /pub/disks?buffer_length=1 HTTP/1.1", host: "localhost" Jan 14 11:35:34 dunbar nginx: 2022/01/14 11:35:34 [crit] 3296#3296: ngx_slab_alloc() failed: no memory Jan 14 11:35:34 dunbar nginx: 2022/01/14 11:35:34 [error] 3296#3296: shpool alloc failed Jan 14 11:35:34 dunbar nginx: 2022/01/14 11:35:34 [error] 3296#3296: nchan: Out of shared memory while allocating channel /diagnostic. Increase nchan_max_reserved_memory. Jan 14 11:35:34 dunbar nginx: 2022/01/14 11:35:34 [alert] 3296#3296: *625524 header already sent while keepalive, client: 192.168.0.165, server: 0.0.0.0:80 Jan 14 11:35:34 dunbar kernel: nginx[3296]: segfault at 0 ip 0000000000000000 sp 00007ffd93cf4428 error 14 in nginx[400000+22000] Jan 14 11:35:34 dunbar kernel: Code: Unable to access opcode bytes at RIP 0xffffffffffffffd6. Jan 14 11:35:34 dunbar nginx: 2022/01/14 11:35:34 [alert] 12346#12346: worker process 3296 exited on signal 11 Jan 14 11:35:34 dunbar nginx: 2022/01/14 11:35:34 [crit] 3299#3299: ngx_slab_alloc() failed: no memory Jan 14 11:35:34 dunbar nginx: 2022/01/14 11:35:34 [error] 3299#3299: shpool alloc failed Jan 14 11:35:34 dunbar nginx: 2022/01/14 11:35:34 [error] 3299#3299: nchan: Out of shared memory while allocating channel /var. Increase nchan_max_reserved_memory. Jan 14 11:35:34 dunbar nginx: 2022/01/14 11:35:34 [alert] 3299#3299: *625526 header already sent while keepalive, client: 192.168.0.165, server: 0.0.0.0:80 Jan 14 11:35:34 dunbar kernel: nginx[3299]: segfault at 0 ip 0000000000000000 sp 00007ffd93cf4428 error 14 in nginx[400000+22000] Jan 14 11:35:34 dunbar kernel: Code: Unable to access opcode bytes at RIP 0xffffffffffffffd6. Jan 14 11:35:34 dunbar nginx: 2022/01/14 11:35:34 [alert] 12346#12346: worker process 3299 exited on signal 11 Jan 14 11:35:34 dunbar nginx: 2022/01/14 11:35:34 [crit] 3300#3300: ngx_slab_alloc() failed: no memory Jan 14 11:35:34 dunbar nginx: 2022/01/14 11:35:34 [error] 3300#3300: shpool alloc failed Jan 14 11:35:34 dunbar nginx: 2022/01/14 11:35:34 [error] 3300#3300: nchan: Out of shared memory while allocating channel /cpuload. Increase nchan_max_reserved_memory. Jan 14 11:35:34 dunbar nginx: 2022/01/14 11:35:34 [error] 3300#3300: *625528 nchan: error publishing message (HTTP status code 507), client: unix:, server: , request: "POST /pub/cpuload?buffer_length=1 HTTP/1.1", host: "localhost" Jan 14 11:35:35 dunbar nginx: 2022/01/14 11:35:35 [crit] 3300#3300: ngx_slab_alloc() failed: no memory Jan 14 11:35:35 dunbar nginx: 2022/01/14 11:35:35 [error] 3300#3300: shpool alloc failed Jan 14 11:35:35 dunbar nginx: 2022/01/14 11:35:35 [error] 3300#3300: nchan: Out of shared memory while allocating channel /disks. Increase nchan_max_reserved_memory. Jan 14 11:35:35 dunbar nginx: 2022/01/14 11:35:35 [error] 3300#3300: *625535 nchan: error publishing message (HTTP status code 507), client: unix:, server: , request: "POST /pub/disks?buffer_length=1 HTTP/1.1", host: "localhost" Any help on where I can start diagnosing this? For what it's worth, this is what the Dashboard showed for RAM usage when I copied the above from syslog:
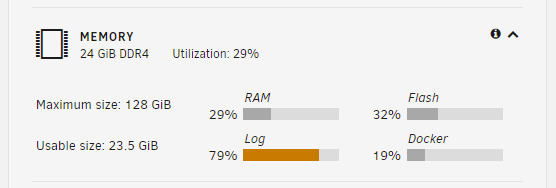
-
Hello, and thanks in advance for any help/advice you can offer. I'll try to provide as much detail as I can here. I was experiencing some weird playback issues with my Plex server, so I restarted the server. Upon a clean restart, I had a disk report that it was unmountable. After some digging, it seemed to be a filesystem issue and I ran through the xfs_repair instructions here. This didn't fix the issue, so I ended up having to remove the disk from the array and rebuilding it. The server went through a data rebuild and completed successfully. After that, the disks all looked fine and the array appeared to be functioning correctly. I started extended SMART tests on my smaller drives, including the disk that had originally presented a problem, and went to bed. I also ran short SMART tests on the larger disks and those seem to all have completed successfully. When I woke up, the server had gone through what seems to have been a hard reset and was running a parity check. Fix Common Problems reported an error: So I'm posting my diagnostics file here and asking for any help you guys can offer. A quick skim through my syslog and it seems like these are concerning lines: Dec 3 07:42:50 dunbar kernel: mce: [Hardware Error]: Machine check events logged Dec 3 07:42:50 dunbar kernel: mce: [Hardware Error]: CPU 3: Machine Check: 0 Bank 5: bea0000000000108 Dec 3 07:42:50 dunbar kernel: mce: [Hardware Error]: TSC 0 ADDR 1ffff81074b06 MISC d012000100000000 SYND 4d000000 IPID 500b000000000 Dec 3 07:42:50 dunbar kernel: mce: [Hardware Error]: PROCESSOR 2:800f11 TIME 1638484949 SOCKET 0 APIC 8 microcode 8001138 ... Dec 3 07:54:09 dunbar root: Fix Common Problems: Error: Machine Check Events detected on your server Dec 3 07:54:09 dunbar root: mcelog: ERROR: AMD Processor family 23: mcelog does not support this processor. Please use the edac_mce_amd module instead. A few searches in this forum turned up bad memory issues, so I'll run memtests as soon as the current parity check finishes, but please let me know if there's anything else I should be looking out for. dunbar-diagnostics-20211203-1003.zip
-
Just an update: the same containers still fail to update most of the time. As a terrible workaround I just set them to auto update via the CA plugin and eventually the updates stick. 🤷♂️
-
Yes, I can install new containers and most other currently installed containers update normally.
-
Nope, and the only user scripts I run are to regularly (daily or weekly) restart a couple docker containers.
-
Thank you dunbar-diagnostics-20210717-2252.zip
-
The latest stable, 6.9.2.
-
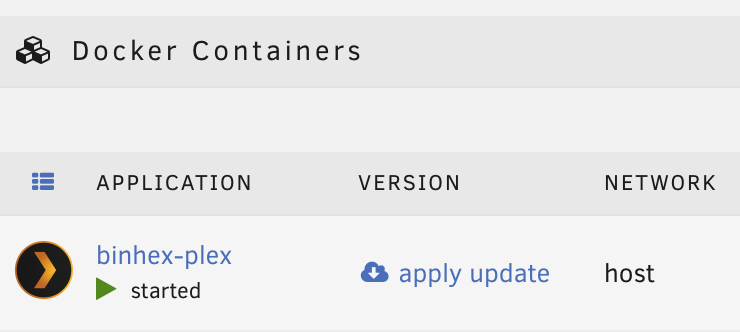
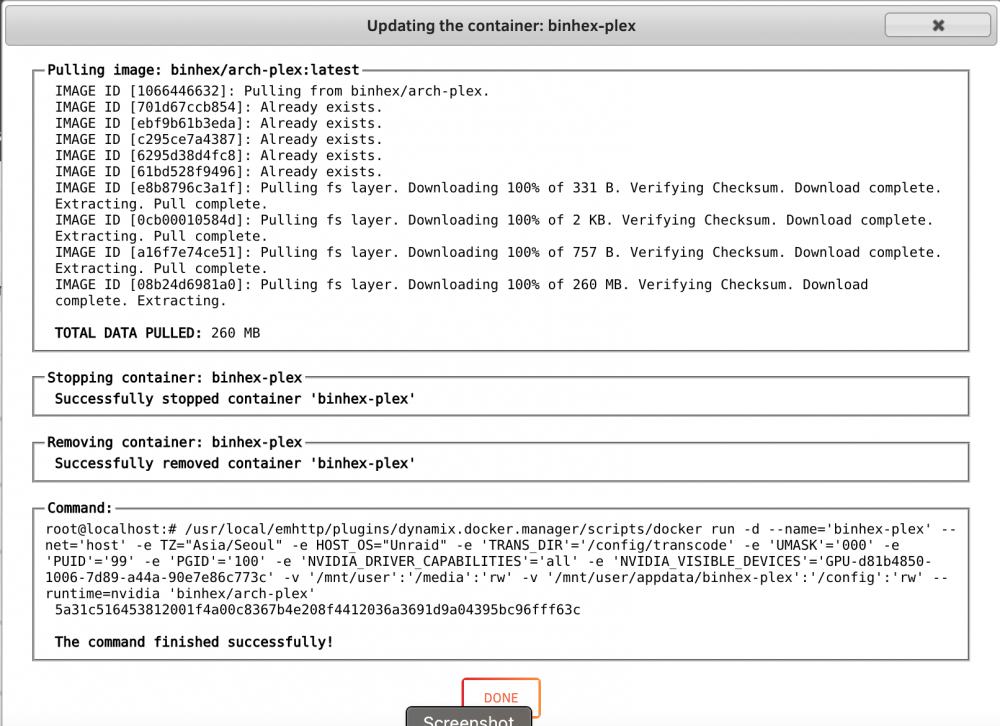
I have a few docker containers that won't update. They show an update available (apply update), complete the regular update process via GUI, and then afterwards still show that an update is available. This is happening with a few select docker containers (binhex-plex, linuxserver/qbittorrent, linuxserver/transmission), but not all. Other dockers are updating successfully. Here is the relevant part of the syslog from when I tried to update one this morning: Jul 16 11:47:24 dunbar webGUI: Successful login user root from 192.168.0.136 Jul 16 11:47:40 dunbar kernel: docker0: port 1(vethce1f00c) entered disabled state Jul 16 11:47:40 dunbar kernel: veth2b61baa: renamed from eth0 Jul 16 11:47:41 dunbar avahi-daemon[10305]: Interface vethce1f00c.IPv6 no longer relevant for mDNS. Jul 16 11:47:41 dunbar avahi-daemon[10305]: Leaving mDNS multicast group on interface vethce1f00c.IPv6 with address fe80::e81c:daff:fe3b:d63f. Jul 16 11:47:41 dunbar kernel: docker0: port 1(vethce1f00c) entered disabled state Jul 16 11:47:41 dunbar kernel: device vethce1f00c left promiscuous mode Jul 16 11:47:41 dunbar kernel: docker0: port 1(vethce1f00c) entered disabled state Jul 16 11:47:41 dunbar avahi-daemon[10305]: Withdrawing address record for fe80::e81c:daff:fe3b:d63f on vethce1f00c. Jul 16 11:47:49 dunbar kernel: docker0: port 1(vethe346b53) entered blocking state Jul 16 11:47:49 dunbar kernel: docker0: port 1(vethe346b53) entered disabled state Jul 16 11:47:49 dunbar kernel: device vethe346b53 entered promiscuous mode Jul 16 11:47:49 dunbar kernel: docker0: port 1(vethe346b53) entered blocking state Jul 16 11:47:49 dunbar kernel: docker0: port 1(vethe346b53) entered forwarding state Jul 16 11:47:49 dunbar kernel: docker0: port 1(vethe346b53) entered disabled state Jul 16 11:48:02 dunbar kernel: eth0: renamed from veth0359162 Jul 16 11:48:02 dunbar kernel: IPv6: ADDRCONF(NETDEV_CHANGE): vethe346b53: link becomes ready Jul 16 11:48:02 dunbar kernel: docker0: port 1(vethe346b53) entered blocking state Jul 16 11:48:02 dunbar kernel: docker0: port 1(vethe346b53) entered forwarding state Jul 16 11:48:04 dunbar avahi-daemon[10305]: Joining mDNS multicast group on interface vethe346b53.IPv6 with address fe80::34c6:e0ff:fe10:734f. Jul 16 11:48:04 dunbar avahi-daemon[10305]: New relevant interface vethe346b53.IPv6 for mDNS. Jul 16 11:48:04 dunbar avahi-daemon[10305]: Registering new address record for fe80::34c6:e0ff:fe10:734f on vethe346b53.*. Jul 16 11:51:53 dunbar kernel: veth5b3491c: renamed from eth0 Jul 16 11:51:53 dunbar kernel: docker0: port 2(vethb82f3a7) entered disabled state Jul 16 11:51:55 dunbar avahi-daemon[10305]: Interface vethb82f3a7.IPv6 no longer relevant for mDNS. Jul 16 11:51:55 dunbar avahi-daemon[10305]: Leaving mDNS multicast group on interface vethb82f3a7.IPv6 with address fe80::8ceb:f5ff:fe26:9c7b. Jul 16 11:51:55 dunbar kernel: docker0: port 2(vethb82f3a7) entered disabled state Jul 16 11:51:55 dunbar kernel: device vethb82f3a7 left promiscuous mode Jul 16 11:51:55 dunbar kernel: docker0: port 2(vethb82f3a7) entered disabled state Jul 16 11:51:55 dunbar avahi-daemon[10305]: Withdrawing address record for fe80::8ceb:f5ff:fe26:9c7b on vethb82f3a7. Jul 16 11:52:13 dunbar kernel: docker0: port 2(vethe496117) entered blocking state Jul 16 11:52:13 dunbar kernel: docker0: port 2(vethe496117) entered disabled state Jul 16 11:52:13 dunbar kernel: device vethe496117 entered promiscuous mode Jul 16 11:52:13 dunbar kernel: docker0: port 2(vethe496117) entered blocking state Jul 16 11:52:13 dunbar kernel: docker0: port 2(vethe496117) entered forwarding state Jul 16 11:52:13 dunbar kernel: docker0: port 2(vethe496117) entered disabled state Jul 16 11:52:20 dunbar kernel: eth0: renamed from veth9929264 Jul 16 11:52:20 dunbar kernel: IPv6: ADDRCONF(NETDEV_CHANGE): vethe496117: link becomes ready Jul 16 11:52:20 dunbar kernel: docker0: port 2(vethe496117) entered blocking state Jul 16 11:52:20 dunbar kernel: docker0: port 2(vethe496117) entered forwarding state Jul 16 11:52:22 dunbar avahi-daemon[10305]: Joining mDNS multicast group on interface vethe496117.IPv6 with address fe80::20cc:95ff:fed6:9568. Jul 16 11:52:22 dunbar avahi-daemon[10305]: New relevant interface vethe496117.IPv6 for mDNS. Jul 16 11:52:22 dunbar avahi-daemon[10305]: Registering new address record for fe80::20cc:95ff:fed6:9568 on vethe496117.*. Not sure where to start on troubleshooting this. I've tried switching DNS servers at my router but that doesn't seem to help. Thanks in advance for any help that can point me in the right direction.