




Auggie
Members
-
Joined
-
Last visited
Everything posted by Auggie
-
OKAY, from this tidbit, I discovered how to enable the web GUI at the console via this "Boot GUI Mode" thread (I manually edited the syslinux.cfg file on another computer) but just in case, I also learned how to automatically pause console text scrolling via the "| less" command in case I needed to use it for screen capture purposes. Now, due to some SNAFU when I was fiddling behind the "retiring" server while it was performing a disk-to-disk file move operation and inadvertently bumped the power cord enough for it to turn off, I downloaded a trial UnRAID and used that to boot my new build and enable the GUI mode while my "old" server is busy checking parity. Right off the bat, the trial UnRAID recognized the PCI NIC and had acquired a network IP address, and all was well according to both the GUI and on the text console via lspci. So my next step is to retest my "Pro" UnRAID stick and see if it, too, will now recognize the PCI NIC. If not, at least I've narrowed it down to something with the configuration of the Pro stick and am prepared for further troubleshooting and tweaking with knowledge of how to enable the Web GUI locally and to control console text scrolling...
-
Yea, I'll do that once I find the time to bring down the "retiring" machine again (I've been swapping its stick to the new machine for setup and testing). I'm also going to attach a monitor to the new machine to get better "eyes" on the output. I also have a brand new ASUS XG-C100C that is intended for my other UnRAID NAS and I'll test it in place of the IBM 1G NIC I'm having problems with to see if it get automatically recognized by UnRAID...
-
Well, I was able to "disable" via BIOS, but I still can't seem to get UnRAID to recognize the PCI NIC now there doesn't appear to be any Ethernet NIC's available on UnRAID. The problem is that since I can't get a network-assigned IP address, I can't access UnRAID's web GUI from anywhere on the network. I can't figure out how to pause the scrolling in the small window of the SuperMicro mobo's iKVM/HTML5 screen so there's no way I can see what was scrolled out of view. I tried the Java-based console redirection but continually get errors getting the screen working. But regardless, I don't think being IBM-branded should be problematic; it's still an Intel-chipped dual-RJ45 Pro/1000 NIC. So at this time, I'm dead in the water as I just can't access unRAID's GUI nor can I effectively use the "console" as I can't pause the scrolling of pertinent information before it disappears.
-
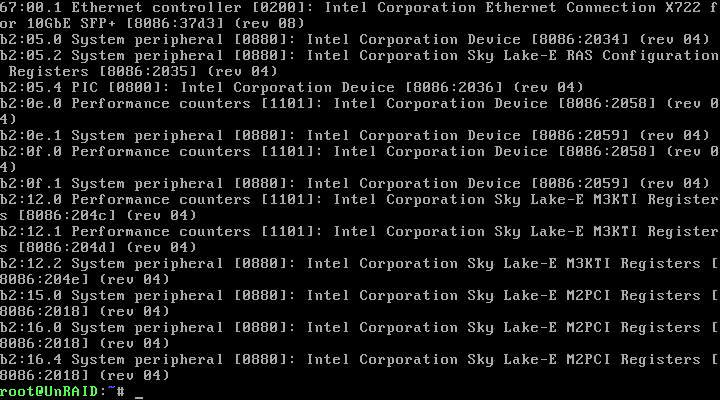
I know in the past that UnRAID always used the first onboard NIC it came across with no option to select any other onboard or PCI NIC. Has this changed with the current version of UnRAID? I'm in the last steps of transitioning to my new SuperMicro X11SPH-nCTPF build, but since it has a pair of SFP+ 10Gb and I haven't yet upgraded my network to 10Gb, I'm trying to use a PCI 1G-BaseT NIC and haven't been able to get UnRAID to default to it as there is no way to disable the onboard NICs via BIOS or other means. Also, I'm not sure if the IBM Intel Pro/1000 39Y6127/39Y6128 NIC is even being recognized at all if I read the lspci list correctly (I'm a real noob at this command). So, two questions: 1) How do I set up UnRAID to use a specific NIC? I came across a few threads which mentioned "stub" but those were way too technical and lacked in a "layman's" step-by-step approach that I could follow. 2) What are some UnRAID "friendly" (i.e. plug-n-play) NICs I could select from, if the one I got isn't compatible?
-
I installed an SSD to use for a VM but mistakenly added it to the cache pool after discovering that I would lose total capacity. After stumbling about to remove it from the cache pool successfully (I ended up having to reformat my original cache SSD), it doesn't appear that the Unassigned Devices is able to mount it; a necessary requirement in order to use this for my VM outside of the array. I'm able to add it the array (at least, it lets me add it but I never commit) and to the cache pool. So is the issue of not being able to mount it via this plugin a problem with the plugin, a problem arising from my mistaken step of initialing adding it the cache pool, or something with UnRAID (6.4.1) itself? UPDATE: I figured it out. I first had to enable Destructive Mode in the Unassigned Devices settings page. This enabled the FORMAT button, which after formatting, the Auto-Mount feature became enabled.

-
Although it seems a relatively simple process, I don't have any PC's to flash the HBA's other than my headless unRAID servers, both of which have SuperMicro mobo's that utilize Java-based IPMI in which the Java applet has been extremely unstable and crashes constantly on my OS X computers. So, I would have to create a bootable flash drive and connect a monitor and keyboard in a cramped, low ceiling storage closet where my RPC-4224 machine resides (or temporarily haul it out onto a table).
-
unRAID will do it's magic based on software. The controller hardware has to simply provide the drives to the OS. Hardware RAID is not necessary and will not work. Some hardware in this thread may be obsolete, but the fact that a controller card has to run in IT mode is still valid. Thanks. I think I understand now; basically, the HBA must allow "JBOD" (which is the term that I've usually looked for when selecting an HBA card). I had purchased the M1015 last year from a recommendation on these forums in another unrelated thread but it wasn't mentioned that I may have to flash the card (it's brand new). I paid $140 but I just compared prices and an LSI SAS9211-8I is going for $112 new; it seems that's the better option as it's cheaper and is already just a plain JBOD HBA with no RAID functions (which flashing the M1015 essentially makes it into a SAS9211-8I with the FW provided by OP).
-
I, too, recently picked up an M1015 card but haven't installed it. Is it necessary to flash this card for unRAID v6.x? Or can it be plugged-and-played? And if it is plug-n-play, is flashing to IT mode simply for better throughput? In general, how relevant is the OP's information regarding the various LSI controllers for v6.x?
-
What are the commands you added to the go script to get this running on cron? I don't remember where I found this, but I'm using the following in my go script: # Load adapter drivers: modprobe ipmi-si # Load chip drivers: modprobe coretemp modprobe w83627ehf # Insert unraid-fan-speed.sh into crontab chmod +x /boot/scripts/unraid-fan-speed.sh crontab -l >/tmp/crontab grep -q "unraid-fan-speed.sh" /tmp/crontab 1>/dev/null 2>&1 if [ "$?" = "1" ] then crontab -l | egrep -v "control unRAID fan speed based on temperature:|unraid-fan-speed.sh" >/tmp/crontab echo "#" >>/tmp/crontab echo "# control unRAID fan speed based on temperature" >>/tmp/crontab echo "*/2 * * * * /boot/scripts/unraid-fan-speed.sh 1>/dev/null 2>&1" >>/tmp/crontab cp /tmp/crontab /var/spool/cron/crontabs/root- crontab /tmp/crontab fi The problem is unRAID 5 is choking on this line "/tmp/crontab /var/spool/cron/crontabs/root-" (specifically, something to do with the root account) and reports this constantly in the syslog. So I'm trying to understand the logic behind this copy command followed by the crontab command in order to modify it to work under unRAID 5, though even with these errors, the script appears to still be running in a timely fashion and correctly adjusting my fans.

