HGWBLN
Members
-
Joined
-
Last visited
Everything posted by HGWBLN
-
Weiß jemand wie lange es dauert bis der Container im App-Store verfügbar ist? Habe eben geschaut, aktuell ist noch nichts da...
-
Hi, ich habe dazu mal ne dumme Frage und bitte nicht falsch verstehen, aber was macht dein Dashboard besser als das bereits verfügbare crowdsec-dashboard von metabase? Ist es rein die grafische Visualisierung?
-
Das war die Lösung! Ich habe jetzt den Raid1 aufgelöst und beide SSDs als Single Disk in den Pool gepackt und mit xfs formatiert. Das Problem tritt nicht mehr auf. Wenn ich mich jetzt in die GUI einlogge, erscheinen die Container und die VM sofort und alle HDDs bleiben im Ruhemodus. Vielen Dank für die Unterstützung.
-
Moin liebe Community, ich bekomme aktuell folgende Fehlermeldung: Invalid folder cache contained within /mnt Diagnostics sind im Anhang. skynet-diagnostics-20250707-0812.zip Kurze Hintergrundgeschichte: Ich hatte als Pool bis vor kurzem 2x NVME als Raid 1 mit Btrfs. Der Name des Pools war Cache. Der Cache hat Probleme gemacht, daher habe ich den Raid 1 Pool aufgelöst und beide SSDs als Single Disk mit xfs wieder hinzugefügt. Der Name der beiden SSDs lautet nun ssd und temp Seit ich das gemacht habe, bekomme ich die obige Fehlermeldung. Eine Recherche im Foum hat diesen Thread ergeben: https://forums.unraid.net/topic/115554-invalid-folder-cache-contained-within-mnt/ Frage: Verstehe ich das richtig, dass es eine Applikation gibt, die noch auf die NVME mit dem Namen Cache schreiben will? Falls ja, könnte es vllt. der LuckyBackup Container sein? Denn im Feld Data Dir steht /mnt/cache/appdata/luckybackup/ Bei allen anderen Containern steht immer /mnt/user/appdata/... Und der Primary Storage für den Share Appdata ist die NVME mit dem Namen ssd ohne einen secondary storage. Falls es das nicht sein sollte, wüsste ich ad hoc nicht was sonst noch einen Bezuzg auf den alten Cache haben könnte. Ich danke euch schon einmal vorab für die Unterstützung. Beste Grüße
-
Hi. Erst einmal möchte ich dir danken für deine Mühen und die Arbeit die du dir machst. Zur obigen Frage, nein die HDDs fahre ich nicht manuell runter. Diese fahren nach 30 min Inaktivität automatisch herunter. Einen Scrub hatte ich erst vor ein paar Tagen durchgeführt. Und beim Scrub den ich eben furchgeführt habe, hieß es dass keine Fehler gefunden wurden. Da dies aber bereits in einem anderen Thread ein Thema war, wäre meine Tendenz aus dem Cache der derzeit im Raid 1 läuft, zwei Single NVME zu machen mit XFS als Format. Dann dürften die Fehlermeldungen ja verschwinden (hoffentlich). Ich habe mir alle Plugins angeschaut. Aus meiner Sicht dürfte keiner davon unkontrolliert auf die HDDs zugreifen. Ich habe folgende Plugins: Appdata Backup --> greift nur auf Appdata zu, Share liegt auf dem Cache AutoTweak Community Applications Compose Manager --> habe ich jetzt gelöscht, da ich es bisher sowieso nicht genutzt habe Dynamix Stop Shell Dynamix System Buttons Dynamix System Information Dynamix System Statistics Dynamix System Temperature Fix Common Problems Intel GPU TOP ITE IT87 Driver Nuvoton NCT6687 Driver rclone Theme Engine Tips and Tweaks Unassigend Devices Unassigend Devices Plus Unassigend Devices Preclear unbalanced Unraid Connect USB Manager USB Manager Addon USer Scripts Da muss ich ehrlicherweise gestehen, dass ich beim heutigen Login auch gesehen habe, dass die VMs nicht sofort angezeigt wurden. Allerdings ist dieses Verhalten neu und war vorher nicht so. FAZIT Ich versuche erstmal den Schritt, dass ich den Raid 1 auflöse, zwei Single Disks im Cache habe, das Format für beide NVMEs umstelle und dann mal schaue wie sich das System verhält... Das wird ein bißchen dauern, da ich schauen muss wann ich ausreichend Zeit dafür habe. Sobald ich das durchgeführt und neue Erkenntnisse gewonnen habe, lasse ich es euch wissen.
-
@alturismo : Anbei findest du eine neue Diagnostics, diesmal sollte sie übersichtlicher sein... Ich habe die unmittelbar nach dem Login erstellt. Auch dieses Mal ist das oben beschriebene Verhalten wieder aufgetreten...skynet-diagnostics-20250626-1752.zip
-
Vielen Dank für die schnelle Antwort. Wenn ich die SSDs eh komplett platt machen sollte, wäre dann ZFS das bessere Format oder sollte ich die beiden NVMEs als Single Disk laufen lassen ohne Raid 1?
-
Hi zusammen, ich muss das Thema erstmal pausieren, da ich wahrscheinlich derzeit ein Cacheproblem habe (siehe auch https://forums.unraid.net/topic/191414-ssd-defekt-froh-%C3%BCber-zweitmeinung/). Sobald das geklärt ist, würde ich nochmal auf eure Antworten eingehen. Ich danke euch für eure Geduld.
-
Hi, ich habe 2 NVME als Cache im Raid 1 mit BTRFS. Ich ermute, dass eine meiner beiden NVMEs defekt ist, hätte aber gerne, bevor ich jetzt loslaufe und mir ne neue hole, gerne eine kompetente Zweitmeinung ob meine Annahme korrekt ist. Dazu auch anbei die Diagnostics: skynet-diagnostics-20250623-1229.zip
-
@alturismo : Ich kann die Unraid Integration in Home Assistant gerne abstellen und die Tage eine neue Diagnostics hochladen... Dann sind die Logs nicht ganz so doll überfrachtet.
-
Hi @DataCollector , sorry für meine späte Antwort. Erst einmal bedanke ich mich vielmals für deine Hilfe und deine Anmerkungen. :) Ich habe mit Compute All geprüft was alles auf Disk 4 liegt. Dabei hat sich bestätigt, dass dort liegen: Logs (leer) Isos Media Wie du empfohlen hast, habe ich den Share Logs von der Disk 4 auf den Cache verschoben. Das brachte leider keine Veränderung, das oben beschrieben Problem besteht weiterhin. Beim Share isos bin ich bei dir, dass dieser mit Docker eigentlich nichts zu tun hat und daher nicht das Problem sein sollte. Der Share Media wird vom Container Plex benutzt. Allerdings liegen auch auf den Disk 1-3 Mediadaten, auf die ebenfalls Plex zugreift und diese Disks fahren beim einloggen in die WebGUI von Unraid nicht hoch. Ich verschiebe gerade alle Mediadaten von der Disk 4 auf die Disk 3, das dauert aber noch ein paar Stunden. Ich melde mich dann noch einmal, wenn der Prozess abgeschlossen ist ob dies ggf. eine Veränderung gebracht hat.
-
Ich mache immer mein Backup vom Stick mit dem Plugin "Appdata Backup". Dort kann man das in den Einstellungen anklicken.
-
Moin liebe Community, der nachfolgende Fall ist kein wirkliches Problem da das System an sich ohne Probleme läuft, sondern eher mehr eine allg. Frage ob das beschrieben Verhalten normal ist. Ausgangsitutaion: Ich habe einen Server mit 5x HDD (davon 1x Parity) und einem Cache mit 2x NVME als Raid 1. Der Ordner Appdata ist dem Cache zugewiesen. Ich habe 17 Docker Container sowie zusätzlich Home Assistant OS als VM aktiv. Der Server läuft so vor sich hin und alle HDDs sind im spindown. Wenn ich mich nun auf die WebGUI einlogge, sehe ich erstmal keine Docker Container und die Last der CPU geht von ca. 20% auf ca. 75 % hoch für rd. 4-5 Sek. Anschließend sehe ich alle meine Container, aber erst zu dem Zeitpunkt an dem auch meine Disk 4 hochgefahren ist. Die Frage die ich habe, warum fährt meine HDD hoch, wenn die Daten der Container doch auf der NVME liegen? Dadurch, dass die Container erst angezeigt werden, wenn die Disk 4 hochgefahren ist, gibt es ja anscheinend einen Zusammenhang. Auf der Disk 4 befinden sich: der Share Isos der Ordner logs (dieser ist leer) ein Ordner mit ein paar Mediadaten Vielleicht ist es noch interessant zu erwähnen, dass es bei der VM nicht vorkommt, sprich, diese wird mir unmittelbar nach dem login angezeigt. Ich habe mal die Diagnostics mit angehängt. Da bitte nicht wundern, ich tracke mein Unraid Dashboard in Home Assistant (HA hat die IP 192.168.10.222)skynet-diagnostics-20250614-1229.zip Ich bedanken mich schon einmal vorab für alle, die zu diesem Verhalten etwas sagen können. Habt ein schönes Wochenende.
-
Vielen Dank für die schnelle Antwort. Ich sehe dann für mich erstmal nur folgende Lösung: (1) Harter Reset durch Stromtrennung (2) Deinstallation des Make MKV Dockers (3) System in Ruhe laufen lassen und die Logs weiter beobachten ob der Fehler wiederkommt (4) Hoffen, dass es irgendwann eine Lösung für das Problem gibt
-
Hallo zusammen, ich habe seit neustem das Problem, dass ich mein Unraidsystem (Name Skynet) nicht rebooten oder herunterfahren kann. Weder funktioniert es über die Schaltflächen (z.B. im Reiter "Main") noch mittels Befehl via SSH. Wenn ich auf den Button klicke oder den Befehl eingebe erscheint in den Logs auch der Befehl "Skynet shutdown[7118]: shutting down for system halt" aber es passiert danach nichts. Auch andere Funktionen wie bspw. das Array stoppen funktionieren nicht. Auch hier sagt das System, dass es das macht, aber dennoch steht seit langer Zeit nur "Stopping..." und das Array ist immer noch aktiv. Ein Blick in die Logs hat mir auch eine immer wiederkehrende Fehlermeldung gezeigt, die sehr häufig vorkommt: "Skynet kernel: traps: lsof[6449] general protection fault ip:1465a0fcfc6e sp:74a24275c97b6e80 error:0 in libc-2.37.so[1465a0fb7000+169". Die blau markierten Werte variieren dabei. Die Logs finden sich anbei. Ich hatte am 29.12 um 01:39 Uhr den Server neu gestartet, indem ich ihn vom Strom getrennt habe. Leider hat sich das eingangs beschriebene Problem dadurch nicht gelöst. Ein Parity-Check hat keine Fehler ergeben. Gefühlt taucht das Problem erst auf, seit ich den Docker MakeMKV installiert und ein externes BluRay-Laufwerk via USB angeschlossen habe. Dazu nutze ich das Plugin USB Devices, um das Laufwerk für den Docker verfügbar zu machen. Aber wie gesagt, ist es nur ein Gefühl. Hat jemand bereits ähnliche Fehlermeldung erhalten? In den englischsprachigen Foren taucht das Problem auch immer wieder auf, allerdings habe ich dort keine Lösung gefunden. Für jegliche Hilfe bin ich sehr dankbar. Edit: Typos skynet-syslog-20241230-1828.zip
-
I love you man, this works great
-
Hi Simon, thank you for your work and your patience answering all the questions. I have a Gigabyte C246M-WU4-CF Mainboard. This Motherboard has in total 12 USB-Ports, but it seems that this Motherboard has only one USB-Controller (Link: server_manual_c246m-wu4_e_1101.pdf (gigabyte.com), Page 7). My goal is to passthrou 2 USB Ports to a Win 10 VM. I installed the USB-Manager and the additional USBIP plugin. After the installation, all buttuons i see are grey. Does that mean that i can not passthrough single USB-Ports to a VM? Thank you very much.

-
Ich nutze LuckyBackup und nach ein paar kleineren Startschwierigkeiten läuft das Teil wunderbar... Ich kann es nur empfehlen.
-
Ja, das mag durchaus Sinn machen, aber ich möchte gerne alle Docker zentral auf dem Unraid laufen lassen. Trotzdem vielen Dank für den Hinweis.
-
Vielen lieben Dank, ich werde das mal ausprobieren und schauen ob es mein Problem löst.
-
Hi. Das ist eine DS220+ mit einem Intel Celeron J4025. Was wäre der Vorteil wenn LuckyBackup auf der Syno läuft?
-
Hallo liebe Community, ich muss ein Script bzw. mehrere Scripte schreiben und habe darin, gelinde gesagt, null Erfahrung und benötige daher etwas Hilfe. Hintergrund: Ich habe eine Synology, die ich für Unraid-Backups nutze. Sowohl die Syno als auch Unraid befinden sich im gleichen Netzwerk. Die Syno fährt aber nur hoch, wenn das Update ansteht und fährt anschließend nach einer gewissen Zeit wieder herunter. Dieses Vorgehen hat mit LuckyBackup Probleme gemacht, die aber dank der Unterstützung von alturismo behoben werden konnte (siehe auch dieses topic: https://forums.unraid.net/topic/158628-luckybackup-sichert-nach-erstmaligem-backup-keine-neue-daten/) Der Zeitplan sieht dabei wie folgt aus: 01:30 Uhr -> Syno fährt hoch 01:55 Uhr -> LuckyBackup wird via Script neugestartet 02:00 Uhr -> LuckyBackup führt sein Backup durch 06:00 Uhr -> Syno fährt herunter Die Syno ist als //192.168.10.52/backup_unraid gemountet. Der Name in Unraid lautet Synology DS220, ich finde die Syno auch unter /mnt/remotes/Synology DS220. Soweit so gut. Problem: Wenn nun die Syno hochfährt, dauert es manchmal ewig bis Unraid diese erkennt. Und selbst wenn das passiert ist, mountet sich die Syno nicht immer automatisch, so dass das LuckyBackup die Syno nicht findet und das Backup nicht startet. Meine Recherche ergab, dass man nach dem Hochfahren der Syno diese via dem Unraid Terminal anpingen soll, so dass Unraid diese schneller erkennt. Lösungsweg: Was muss also getan werden? Die Syno muss via Script angepingt werden. Die Syno muss via Script gemountet werden. Der Docker LuckyBackup muss neugestartet werden (--> dafür habe ich bereits ein Script) Erforderliche Scripte (via UserScript): (1) Syno anpingen Ich denke für die erste Lösung müsste das Script wie folgt aussehen 1 #!/bin/bash 2 ping 192.168.10.52 Frage: Wie lautet der Befehl, dass Unraid mit dem anpingen wieder aufhört, denn wenn ich den Befehl in das Terminal eingebe, läuft der Ping immer weiter. (2) Syno mounten Hier bin vollkommen überfragt und habe mit meiner Recherche auch nichts passendes gefunden. (3) LuckyBackup neustarten Hier habe wie wie bereits geschrieben schon ein Script. 1 #!/bin/bash 2 docker restart luckyBackup Der Zeitplan in Unraid ist ein custom schedule mit 55 1 *** Und jetzt die Frage aller Fragen: Wer kann mir mit den Scripten weiterhelfen?


-
Backup läuft jetzt wunderbar durch. Es lag wirklich daran, dass die Syno immer vor dem Backup erst hochgefahren wird. Mit dem Script das LuckyBackup vor dem Erstellen des Backups neu gestartet wird, klappt nun alles. Nochmals vielen Dank für den Tipp.
-
Alles klar, ich probiere das aus. Schon einmal vielen Dank für die Hilfe. Als Script nehme ich an, reicht folgender Befehl? #!/bin/bash docker restart luckyBackup Und in userscripts erstelle ich dann ein custom schedule, korrekt?
-
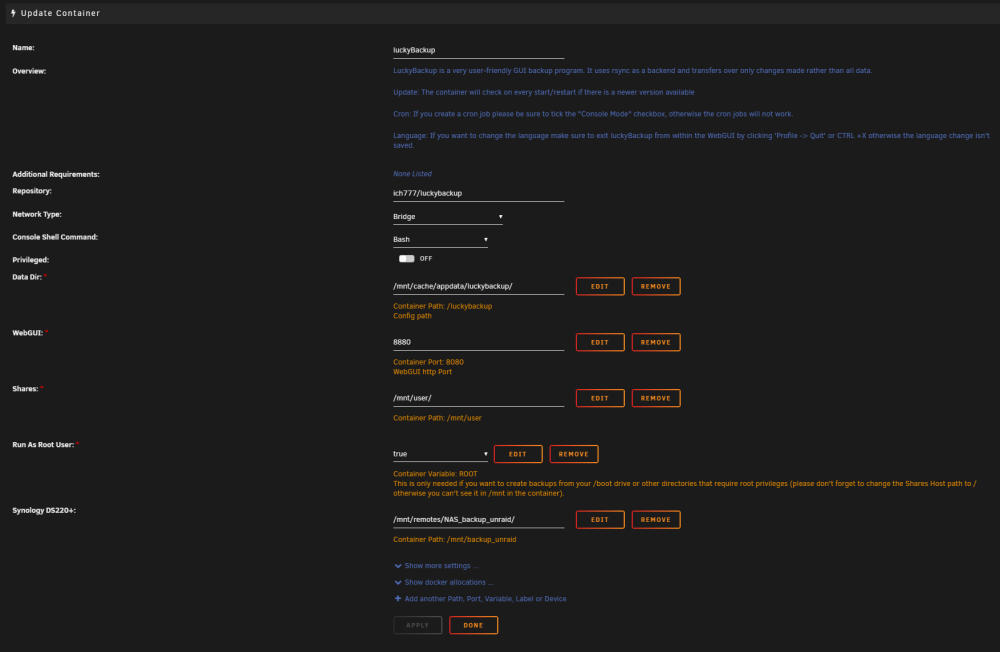
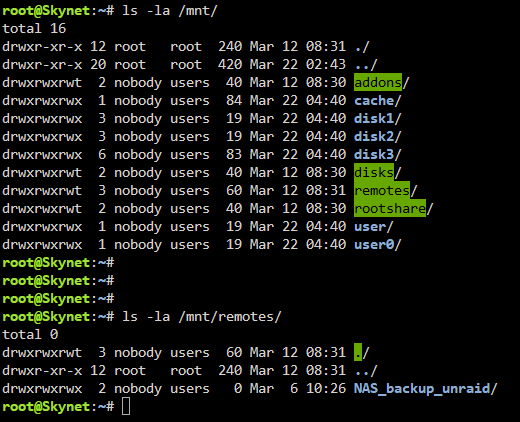
Hi. Anbei findest du die gewünschten Angaben: Screenshot von den Containereinstellungen Screenshot der Ausgabe von ls -la /mnt/ und ls -la /mnt/remotes/ Vielleicht ist noch die nachfolgende Info wichtig: Ich fahre die Syno immer um 01:30 Uhr hoch, die Backups starten um 02:00 Uhr und sind meistens nach 60-90 min fertig. Anschließend fahre ich die Syno wieder um 06:00 Uhr herunter. Sprich das Laufwerk der Syno wird jedes Mal neu gemountet (habe Automount aktiviert). Wenn du sagst, dass LuckyBackup nach einem mount neu gestartet werden muss, könnte das evtl. eine Fehlerquelle sein?