




secretstorage
Members
-
Joined
-
Last visited
-
Nope, it's just hit and miss and crashes from time to time when USB devices fall out. For the moment mine has been stable for about a months, as I've not used the 3D printer much, nor had much to do with Frigate, but I am sure that a day will come. At the moment I am looking at upgrading my rig with an X870E motherboard, so will have a lot more USBs under a single controller. Hopefully should be able to minimize the probability of these crashes, but not entirely sure if it will help.
-
@spants would you envision updating the docker image to include the new camera stack? https://octoprint.org/blog/2023/05/24/a-new-camera-stack-for-octopi/ https://plugins.octoprint.org/plugins/camerastreamer_control/ It would be fantastic to have RTC support for the buttery smooth streaming. Thanks in advance!
-
How would you read this: Looks like there are two and I am currently using both. I couldn't use only the back sockets because devices would fight for allocations and oscillate back and forth ON/OFF.

-
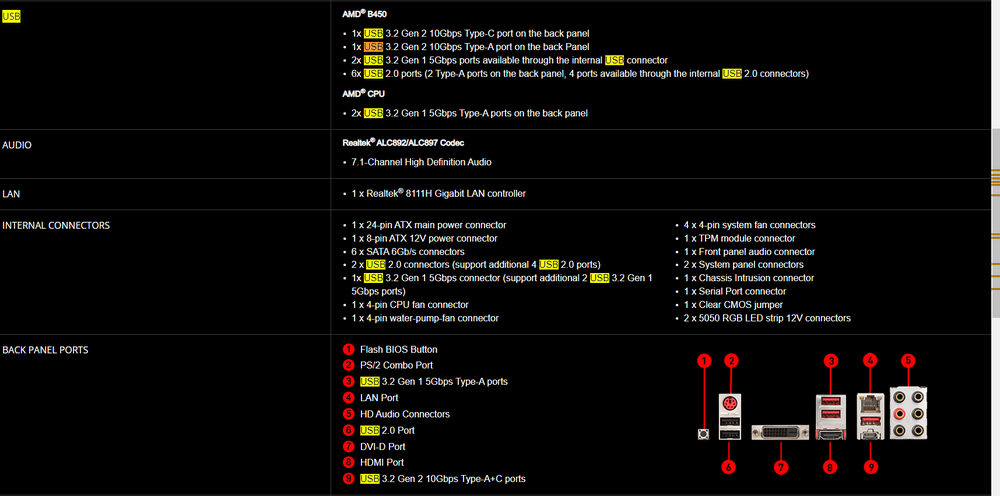
Just to clarify, "different USB controller" would be a physical USB hub? I am using 5 different ports on my B450 Tomahawk board, with all but one being allocated with the Unraid USB, 3D printer, SDR-adapter, Webcam and UPS. Should I buy a hub and get it transferred to it?
-
Looks to be mostly exactly the same errors for two users with completely different vintage and type of equipments. How should we proceed with seeking the Unraid's team help on this? Thank you!
-
Almost identical to my logs from a crash minutes ago - a pattern?? ``` Jun 6 18:17:10 Server dhcpcd-run-hooks[29674]: br0: Invalid domain name: .local Jun 6 18:47:10 Server dhcpcd-run-hooks[31956]: br0: Invalid domain name: .local Jun 6 19:17:10 Server dhcpcd-run-hooks[2210]: br0: Invalid domain name: .local Jun 6 19:47:10 Server dhcpcd-run-hooks[4298]: br0: Invalid domain name: .local Jun 6 20:17:10 Server dhcpcd-run-hooks[5781]: br0: Invalid domain name: .local Jun 6 20:43:36 Server kernel: usb 2-2: reset SuperSpeed USB device number 2 using xhci_hcd Jun 6 20:43:36 Server kernel: usb 2-2: LPM exit latency is zeroed, disabling LPM. Jun 6 20:47:10 Server dhcpcd-run-hooks[7601]: br0: Invalid domain name: .local Jun 6 21:17:10 Server dhcpcd-run-hooks[10055]: br0: Invalid domain name: .local Jun 6 21:47:10 Server dhcpcd-run-hooks[12527]: br0: Invalid domain name: .local Jun 6 22:17:10 Server dhcpcd-run-hooks[16036]: br0: Invalid domain name: .local Jun 6 22:47:10 Server dhcpcd-run-hooks[19282]: br0: Invalid domain name: .local Jun 6 23:17:10 Server dhcpcd-run-hooks[21925]: br0: Invalid domain name: .local Jun 6 23:47:10 Server dhcpcd-run-hooks[24961]: br0: Invalid domain name: .local Jun 7 00:17:10 Server dhcpcd-run-hooks[27826]: br0: Invalid domain name: .local Jun 7 00:26:23 Server kernel: xhci_hcd 0000:03:00.0: WARN Set TR Deq Ptr cmd failed due to incorrect slot or ep state. Jun 7 00:26:24 Server kernel: xhci_hcd 0000:03:00.0: WARN Successful completion on short TX Jun 7 00:26:24 Server kernel: xhci_hcd 0000:03:00.0: ERROR Transfer event TRB DMA ptr not part of current TD ep_index 2 comp_code 1 Jun 7 00:26:24 Server kernel: xhci_hcd 0000:03:00.0: Looking for event-dma 0000000103b91a90 trb-start 0000000103b91aa0 trb-end 0000000103b91aa0 seg-start 0000000103b91000 seg-end 0000000103b91ff0 Jun 7 02:13:45 Server unassigned.devices: Mounting 'Auto Mount' Devices... Jun 7 02:13:45 Server unassigned.devices: Error: Device '/dev/sdb1' mount point 'spare' - name is reserved, used in the array or a pool, or by an unassigned device. Jun 7 02:13:45 Server unassigned.devices: Disk with serial 'ST4000DX001-1CE168_Z30195RK', mountpoint 'spare' cannot be mounted. Jun 7 02:13:46 Server emhttpd: Starting services... ``` @JorgeB I've currently switched off in config all the cameras that previously were rebooting and causing errors in Frigate, so they are no longer present in logs. This may thus be strictly related to USB resetting? https://github.com/google-coral/edgetpu/issues/166
-
Thank you very much for taking the time to look into it. Would you mind elaborating on what re-test would mean? Since it's often 2-4 weeks between crashes (before) and 3-4 happening today, I wonder how would I go about testing it. I would have to disable my NVR, 3D printer monitoring and many automations for weeks/months to confirm anything... hmm what to do.... In the meantime, I've found the following thread, which seems very close to what is going on for me. Would you agree?
-
@JorgeB would you mind taking a look? It failed 3 times just today and while there are still USB errors attributable to my UPS which for some reason seems to disconnect all the time, there are other docker related errors (blocked mode). Not sure where to look for next steps.... syslog-10.10.10.99.log
-
And again died this morning, just 30-45 min ago. From what I can see there are a lot of GPU errors as well, which starts to make sense in the way the GPU was behaving, but it would this cause a kernel panic issue? syslog-10.10.10.99.log
-
My 3D printer is powering down and up maybe 2-3 times a day and I am running OctoPrint container - so this could be one. Outside of that nothing else is connecting/disconnecting. Need to remove the GPU as it's been giving me grief recently and try to run it headless. The issue with that is that I will not know what state the server is in when it locks up.
-
It happened 3 times in the last two weeks, with the latest one about 20 minutes ago. I can look up the other two, which took place when I was on leave. Thanks for looking into it. syslog-10.10.10.99.log
-
OK, I'll continue logging and will come back to this thread upon another crash. It's typically every 10-14 days. Thanks for looking into it!
-
The crash occurred today around 22.20 CET and I've recovered around 0:20 CET, so rough 2h later. Please see the logs attached syslog-10.10.10.99.log
-
Thanks very much for looking into it so quickly! 1) You may have missed that in an earlier post, I've migrated ALL hardware (including case 😉) bar the USB drive and the issue continues happening as it had before. 2) I understand it may be a route for some but since Unraid is hosting my home automation server it's not an option to bring it down for several days as it would affect many systems. I don't have hardware to host it in parallel unfortunately. 3) With many threads on this and people having corrected the mcvlan issues already, it's really difficult to understand how everyone is having a hardware issue that produces the same outcome. I understand it's very difficult to chaise down such intermitent problems but I also fell there is a lot of 'it works on my end' vibes going around. I'll await another kernel panic crash and send in the logs, as it haven't happened yet. This may allow us additional information. Fingers crossed! 🤞
-
syslog-10.10.10.99.logserver-diagnostics-20240213-1804.zip Please see the diagnostics attached. Second, I am including the logs from the last 24 hours, which may provide some clues or further confusion. What have not happened before, for an unknown reason my whole docker simply stopped yesterday and was disabled until I enabled it about an hour ago. The logs are also flooded with Server kernel: device vethe9dd15e entered promiscuous mode Please feel free to have a look, if you see anything relevant. Thank you in advance!!

