




kecho05
Members
-
Joined
-
Last visited
-
root@ENAS:~# wget --compression=auto -O /dev/null https://ca.unraid.net/assets/feed/applicationFeed.json --2025-10-16 09:55:09-- https://ca.unraid.net/assets/feed/applicationFeed.json Resolving ca.unraid.net (ca.unraid.net)... 172.67.69.176, 104.26.3.117, 104.26.2.117, ... Connecting to ca.unraid.net (ca.unraid.net)|172.67.69.176|:443... connected. HTTP request sent, awaiting response... 200 OK Length: unspecified [application/json] Saving to: ‘/dev/null’ /dev/null [ <=> ] 1.94M 1.67MB/s in 1.2s 2025-10-16 09:55:11 (1.67 MB/s) - ‘/dev/null’ saved [20395759]
-
sometimes at homepage/docker i can see the error message above but actually dockers like qbittorrent runs well, still can open x.x.x.x:8080 which is qbittorrent's webui. after restart whole system everything works well but after days or hours the error happens again. i check the logs then found some SQUASHFS error, maybe it is the reason? i upload two logs file, all of them have same problem and same records on logs. thank you very much for helping me on this. enas-diagnostics-20240602-1312.zip enas-diagnostics-20240606-1010.zip enas-syslog-20240602-0512.zip enas-syslog-20240606-0210.zip
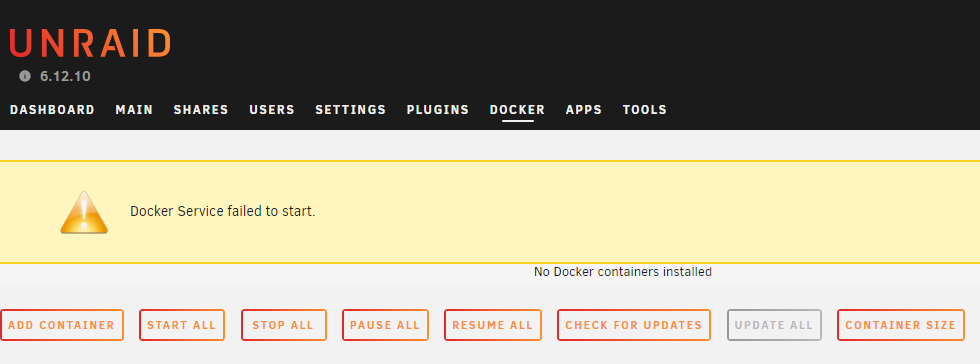
-
在系统后台无法访问docker页面了,错误页面如下 但是直接访问ip:8080是可以打开qb的页面,说明docker是在运行状态的 平时只开了两个docker,一个静态服务,一个qb 相比以往,这次只是让qb校验了几个比较大的种子。 然后观察后台日志,昨天晚上出现了一些报错 Jun 1 20:50:23 ENAS kernel: SQUASHFS error: xz decompression failed, data probably corrupt Jun 1 20:50:23 ENAS kernel: SQUASHFS error: Failed to read block 0x2b77b70: -5 Jun 1 20:50:23 ENAS kernel: SQUASHFS error: xz decompression failed, data probably corrupt Jun 1 20:50:23 ENAS kernel: SQUASHFS error: Failed to read block 0x2b77b70: -5 Jun 1 20:50:23 ENAS kernel: SQUASHFS error: xz decompression failed, data probably corrupt Jun 1 20:50:23 ENAS kernel: SQUASHFS error: Failed to read block 0x2b77b70: -5 Jun 1 20:50:23 ENAS kernel: SQUASHFS error: xz decompression failed, data probably corrupt Jun 1 20:50:23 ENAS kernel: SQUASHFS error: Failed to read block 0x2b77b70: -5 Jun 1 20:50:23 ENAS kernel: SQUASHFS error: xz decompression failed, data probably corrupt Jun 1 20:50:23 ENAS kernel: SQUASHFS error: Failed to read block 0x2b77b70: -5 Jun 1 20:50:23 ENAS kernel: SQUASHFS error: xz decompression failed, data probably corrupt Jun 1 20:50:23 ENAS kernel: SQUASHFS error: Failed to read block 0x2b77b70: -5 虽然影响不是很大,而且重启以后一切正常。 但是我仍然想知道出现这个问题的原因到底在哪里,如果可以的话,怎么去避免它 enas-diagnostics-20240602-1312.zip enas-syslog-20240602-0512.zip
-
hi there, I had changed a new 10t disk instead of old 2t disk, because old disk have a lots of errors. My array has one nvme ssd disk and 2 sata disk (previous are 10t+2t and now 10t+10t) My nas have enough dock so i first add new 10t disk to my array and use rsync command to transfer data. During the transfer there are a lots of input/output error 5 and the result is the command only transferred ~1.2TB data to new disk (which should be around 1.6T data according to the useage) Now i found a lots of errors in logs and i think the error happens when my docker-qbittorrent run the recheck for the red seeds. if i stop the recheck, no more errors. Attached are my log and diagnostics file. Thanks in advance for any help with this issue. enas-diagnostics-20240421-2141.zip enas-syslog-20240421-1341.zip
-
已根据上一条的回复增加了pcie禁用参数 这次启动系统以后,xhci_hcd 0000:00:0d.0: PCI post-resume error -19!的报错依旧存在,看来其跟我的硬件有关,但是似乎它并不是造成问题的核心原因,个人认为可以暂时排除这个因素。 这次重启系统以后我成功复现了报错 附件是日志和诊断文件 可以看到21:56:39起不断报错,这是因为我在等待系统启动并稳定运行后,开启了docker-qbittorrent的校验文件功能,因为之前2t的硬盘rsync过来的文件有一些是不完整的,这也导致了我qb部分红种的情况,我想让qb把红种校验一遍,然后重新下载缺失部分。 如此推断,很可能是qb的校验行为导致的日志里出现的大量报错,而且这个报错出现的时候,也会反过来影响qb的校验速度。 待qb校验完现有红种以后此问题就会消失? 还是说以后只要qb校验文件就会出现这个情况? 暂时还不清楚,不过以前肯定是没有这个问题的。 如果大佬们有猜想的解决方案,我也乐于一试,如果等校验完毕后仍会报错,我也会回来提供新的日志和诊断文件 enas-syslog-20240420-1414.zip enas-diagnostics-20240420-2214.zip
-
更新几条错误日志记录,这期间除去qb下载,没有做其他操作
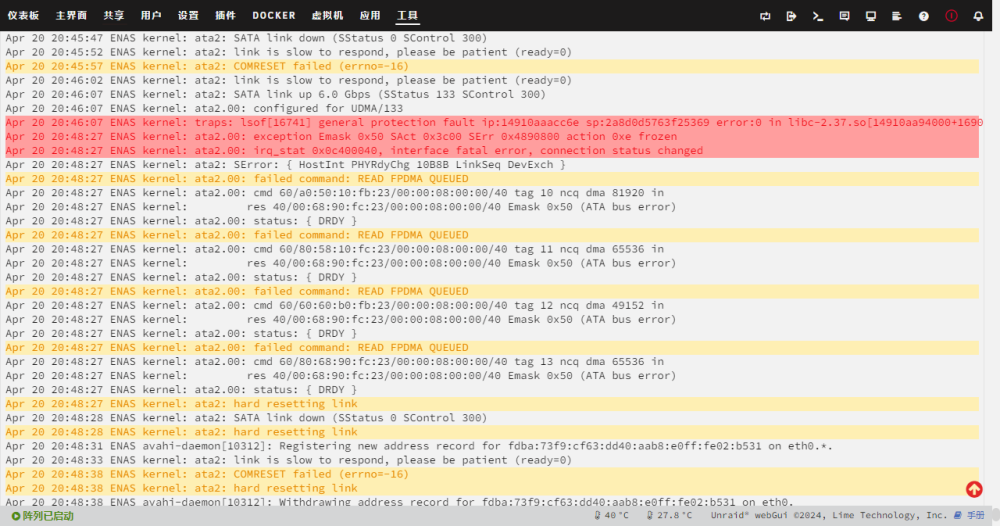
-
已排查了供电、sata线等区域,暂时没有发现什么异常(除了更换的硬盘,一切均与前几天一致,更换上去的硬盘也是一个全新的健康硬盘,我也尝试过更换硬盘插槽) 我暂时定位到了一个100%复现的错误,我也不知道是对是错 附件这是系统重启的日志 可以发现系统在启动的时候这里有报错 然后我去设备列表里看,这个设备代码好像是usb控制器(下图红框)但是我的设备目前只有一个正在使用的usb设备(即unraid系统盘,下图蓝框) 我也不知道这是不是后续sata硬盘错误的导火索(刚才又出现了sata硬盘的大量错误,与一开始的提问类似,sata一会link到6.0Gbps,一会link到3.0Gbps,一会儿link到1.5Gbps,最后还出现了文件在nfs共享中访问不到的问题,后续重启又好了) 附件是nas重启到能够web登录的日志和诊断文件,不知道能否有帮助 后续我会在硬盘再次出现错误的时候,上传新的诊断和日志文件。 enas-syslog-20240420-1155.zip enas-diagnostics-20240420-1956.zip


-
之前的阵列是2t+10t硬盘,那块2t的硬盘频频报错,于是买了一块新的10t硬盘 然后用rsync把2t数据转移到新的10t硬盘的时候频频报错(出现大量input/output error 5)的错误 最后2t硬盘显示1.69t的数据只转移过来1.2t,不是什么特别重要的数据我也就拉倒了。 但是现在阵列是10t+10t硬盘,smart也完全是健康的情况下 在日志里发现如下错误 请问这个问题该如何排查?
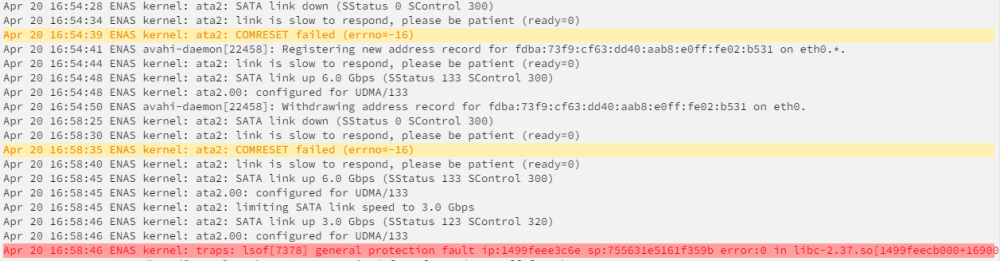
-
顺便问一下,默认unraid设置中的这个等待的时间单位是啥?秒?分钟?小时?
-
-
目前的状态:一共4个硬盘槽位,槽位1和3分别装了硬盘A和B,没有使用校验盘。 想达到的状态:把槽位3的硬盘B更换为硬盘C,使得原来1-A、3-B变成1-A、3-C,依旧不使用校验盘。 问题: 我应该如何转移数据及挂载硬盘?
-
又出现了一段新的错误 伴随着这段错误的出现,我的整个文件共享也没了(磁盘序列还在) 请问这也是磁盘IO的问题吗?(已经删掉了intel sriov插件) Mar 31 14:01:52 ENAS avahi-daemon[25993]: Registering new address record for fdba:73f9:cf63:dd40:aab8:e0ff:fe02:b531 on eth0.*. Mar 31 14:02:03 ENAS avahi-daemon[25993]: Withdrawing address record for fdba:73f9:cf63:dd40:aab8:e0ff:fe02:b531 on eth0. Mar 31 14:04:20 ENAS avahi-daemon[25993]: Registering new address record for fdba:73f9:cf63:dd40:aab8:e0ff:fe02:b531 on eth0.*. Mar 31 14:06:52 ENAS avahi-daemon[25993]: Withdrawing address record for fdba:73f9:cf63:dd40:aab8:e0ff:fe02:b531 on eth0. Mar 31 14:11:41 ENAS avahi-daemon[25993]: Registering new address record for fdba:73f9:cf63:dd40:aab8:e0ff:fe02:b531 on eth0.*. Mar 31 14:11:46 ENAS avahi-daemon[25993]: Withdrawing address record for fdba:73f9:cf63:dd40:aab8:e0ff:fe02:b531 on eth0. Mar 31 14:15:23 ENAS avahi-daemon[25993]: Registering new address record for fdba:73f9:cf63:dd40:aab8:e0ff:fe02:b531 on eth0.*. Mar 31 14:15:33 ENAS avahi-daemon[25993]: Withdrawing address record for fdba:73f9:cf63:dd40:aab8:e0ff:fe02:b531 on eth0. Mar 31 14:17:49 ENAS avahi-daemon[25993]: Registering new address record for fdba:73f9:cf63:dd40:aab8:e0ff:fe02:b531 on eth0.*. Mar 31 14:18:12 ENAS avahi-daemon[25993]: Withdrawing address record for fdba:73f9:cf63:dd40:aab8:e0ff:fe02:b531 on eth0. Mar 31 14:20:16 ENAS avahi-daemon[25993]: Registering new address record for fdba:73f9:cf63:dd40:aab8:e0ff:fe02:b531 on eth0.*. Mar 31 14:20:23 ENAS avahi-daemon[25993]: Withdrawing address record for fdba:73f9:cf63:dd40:aab8:e0ff:fe02:b531 on eth0. Mar 31 14:21:29 ENAS avahi-daemon[25993]: Registering new address record for fdba:73f9:cf63:dd40:aab8:e0ff:fe02:b531 on eth0.*. Mar 31 14:21:52 ENAS avahi-daemon[25993]: Withdrawing address record for fdba:73f9:cf63:dd40:aab8:e0ff:fe02:b531 on eth0. Mar 31 14:22:00 ENAS dhcpcd[25119]: eth0: REPLY6 received from fe80::d635:38ff:fe75:b700 Mar 31 14:22:00 ENAS dhcpcd[25119]: eth0: adding address 240e:388:5f18:3d00::3d2/128 Mar 31 14:22:00 ENAS dhcpcd[25119]: eth0: renew in 1605, rebind in 2568, expire in 3210 seconds Mar 31 14:23:58 ENAS avahi-daemon[25993]: Registering new address record for fdba:73f9:cf63:dd40:aab8:e0ff:fe02:b531 on eth0.*. Mar 31 14:29:58 ENAS avahi-daemon[25993]: Withdrawing address record for fdba:73f9:cf63:dd40:aab8:e0ff:fe02:b531 on eth0. Mar 31 14:30:55 ENAS kernel: shfs[27961]: segfault at 14b86491bbf0 ip 000014b87178f9c7 sp 000014b8703edb88 error 4 in libc-2.37.so[14b87164d000+169000] likely on CPU 3 (core 3, socket 0) Mar 31 14:30:55 ENAS kernel: Code: 48 01 d0 c5 f8 77 c3 66 2e 0f 1f 84 00 00 00 00 00 66 90 c4 41 01 ef ff 89 f8 09 f0 c1 e0 14 3d 00 00 00 f8 0f 87 29 03 00 00 <c5> fe 6f 07 c5 fd 74 0e c5 85 74 d0 c5 ed df c9 c5 fd d7 c9 ff c1 Mar 31 14:31:01 ENAS avahi-daemon[25993]: Registering new address record for fdba:73f9:cf63:dd40:aab8:e0ff:fe02:b531 on eth0.*. Mar 31 14:31:10 ENAS avahi-daemon[25993]: Withdrawing address record for fdba:73f9:cf63:dd40:aab8:e0ff:fe02:b531 on eth0.
-
目前整个unraid系统还是可用的,但是暂时不知道应该把错误定位到哪里 提问是想知道错误到底在哪,方便后续的维护(换u盘 or 换硬盘) 请主要看Mar 29 18:00及以后的日志(之前是重启了一下系统) 我确实有个smart不那么健康的硬盘(disk2),但是想着既然能用就先用着再说了 看日志好像错误也跟硬盘无关,那是U盘的问题?还是网络的问题?(日志里好像提到过) Mar 29 17:58:37 ENAS kernel: i915 0000:00:02.0: [drm] *ERROR* AUX USBC2/DDI TC2/PHY TC2: did not complete or timeout within 10ms (status 0xad4002ff) Mar 29 17:58:37 ENAS kernel: i915 0000:00:02.0: [drm] *ERROR* AUX USBC2/DDI TC2/PHY TC2: did not complete or timeout within 10ms (status 0xad4002ff) Mar 29 17:58:37 ENAS kernel: i915 0000:00:02.0: [drm] *ERROR* AUX USBC2/DDI TC2/PHY TC2: did not complete or timeout within 10ms (status 0xad4002ff) Mar 29 17:58:37 ENAS kernel: i915 0000:00:02.0: [drm] *ERROR* AUX USBC2/DDI TC2/PHY TC2: did not complete or timeout within 10ms (status 0xad4002ff) Mar 29 17:58:37 ENAS kernel: i915 0000:00:02.0: [drm] *ERROR* AUX USBC2/DDI TC2/PHY TC2: did not complete or timeout within 10ms (status 0xad4002ff) Mar 29 17:58:37 ENAS kernel: i915 0000:00:02.0: [drm] *ERROR* AUX USBC2/DDI TC2/PHY TC2: not done (status 0xad4002ff) 和 Mar 29 17:59:02 ENAS root: Error response from daemon: network with name eth0 already exists enas-syslog-20240330-0318.zip enas-diagnostics-20240330-1127.zip
-
首先我不是很懂。 但是我看你这里container port后面都没有值,是不是没有映射成功啊? 点后面的编辑按钮,把container port的值加上试试看呢?

-
哈哈,我也是晕乎乎的,我最近出现的问题都很奇怪(今早我改了一下qb的密码,然后停了docker再打开,qb的webui就打不开了。。。) 有没有一键恢复网络默认配置的方法啊






